
1. Introduction
Dictionary learning (DL) is a branch of signal processing and machine learning that aims to find a frame (or dictionary) for sparsely representing signals as a combination of few elements. The initial basis is unknown and is usually learned from the data. This method has been widely used in multiple fields, such as image and audio processing, inpainting, compression, feature extraction, clustering, and classification.
where is the matrix that contains N signals of size m, stored compactly as columns, is named dictionary and is usually overcomplete (), and is the coefficients’ matrix. The column vectors of matrix are named atoms and define the basis vectors used for the linear combination. For each signal sample, only s atoms are used for the representation. The matrix is a sparse matrix that contains the coefficients associated with the atoms used for the linear representation.
Dictionary learning (DL) can be used in various application problems. Considering the sparse representation capabilities and the light optimization procedure, relevant results can be obtained in practice. However, performance usually depends on the initialization of the dictionary and its properties. For example, in classification problems or discriminative learning, the incoherence of the atoms becomes relevant. Incoherence is the property of the atoms to be far apart one from another; equivalently, their scalar product is small in absolute value. Several methods include discriminative terms in the optimization procedure to meet the incoherence goal. On the other hand, a pre-trained dictionary can be advantageous when prior knowledge about the data is known. In this paper, we address the dictionary initialization problem using a previous problem validated for deep neural networks in a self-supervised manner. This initialization can be used for general problems or classification problems solved with DL.
A significant challenge within the instance discrimination framework is the lack of intraclass variability. In traditional supervised learning, there are typically hundreds or thousands of examples per class, which helps the algorithm to learn the inherent variation within each class. However, in many applications, there are only a few examples per class, which clearly hinders the learning process. This issue can be tackled through extensive data augmentation. By applying different transformations to a specific data point, we can generate slightly varied versions while maintaining its fundamental semantic meaning. This approach allows us to learn valuable representations without relying on explicit labels.
To set up the contrast between instances, several views of the inputs are produced using a process and then evaluated in the representation space. For a particular input , an anchor is calculated as and then compared to a positive sample , which is another transformation of the same input or a sample from the same class with the anchor. A negative sample, , which represents a transformation of a different input, is also contrasted with the anchor. In addition, the process is modified or updated so that it represents positive pairs in a compact form, while negative pairs are projected far apart.
In the general context of Self-Supervised Representation Learning (SSRL), this approach involves a pretext task generator that creates pretext inputs for multiple pairs of raw input instances. These inputs have pseudo-labels that indicate whether the pairs are matching or not.
where k represents the number of negative samples that have been used in contrast with the anchor. The training process can also include the transformation process or only the encoder .
Multiple versions of this strategy can be employed within this framework. The methods vary based on the similarity function, the family of transformations , the encoder function , and approaches to the sampling anchor, and positive and negative examples.
Contributions. In this paper, we adapt the SimCLR framework to the dictionary learning problem, with the purpose of obtaining more incoherent atoms that are better adapted for DL applications (classification and anomaly detection). The learned atoms can then be used to improve sparse representations, leading to smaller representation errors and better discriminative performances.
The main contribution is reconfiguring the initial SimCRL algorithm in the context of dictionary learning. This includes the substitution of the base encoder network with a dictionary learning problem. The network projection head is no longer used since the encoding and projection are performed using the OMP algorithm. The augmentation procedure was adapted for n-dimensional vectors. For this, we only used four elementary operations, which were changed in the context of dictionary learning. This self-supervised framework is capable of building more incoherent dictionaries, which facilitates a better representation error and has an impact on further supervised and semi-supervised applications.
The use of SimCLR can be beneficial for dictionary learning applications from different perspectives. In many real-world applications, large amounts of unlabeled data are used. SimCLR can learn robust feature representations from the unlabeled data, which can then be used to initialize the dictionary. This initialization can improve the performance of downstream tasks, such as classification, anomaly detection, or clustering, even when labeled data are scarce. On the other hand, the initialization of the dictionary using the SimCLR framework can boost the optimization process. The learning process can start from a more informative and structured point, potentially leading to faster convergence and more stable solutions. This not only enhances the efficiency and effectiveness of the learning process, but also improves the interpretability and stability of the resulting model.
2. Contrastive Dictionary Learning
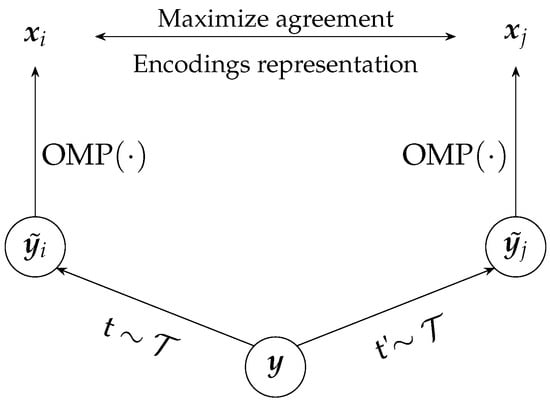
In the context of dictionary learning (DL), we apply stochastic data augmentation transformations to generate pairs of correlated signals from the same example, denoted and . These two samples are derived from an initial sample . Let represent the space of augmentation operations that can be applied to the samples. For two different random initializations of the augmentation operators, we have and . The next step is to follow an encoding process that aims to maximize the agreement between the two augmented samples in the representation space.
The SimCLR problem has been adapted without using a projection head or a base encoder. Instead, the dictionary is used directly to calculate the encodings using an OMP procedure. The embeddings are represented by the column vectors of the matrix .
To build a positive pair of encodings, denoted as and , we compute the representation coefficients of the two augmented samples, and . In addition, contrastive loss is calculated to measure similarities between positive pairs of encodings and discriminate them from negative pairs.
To compute the loss function, we randomly select a mini-batch of K examples at each iteration. After that, we create pairs of augmented samples for each of the K examples, resulting in a total of data points. By doing so, we do not need to sample negative examples explicitly.
where is the dictionary matrix and s is the sparsity level.
OMP aims to find the best sparse representation of a signal by iteratively selecting the most relevant atoms from the dictionary . Iteratively, the algorithm selects the atom most correlated with the current residual. After the selection is made, the residual is updated by projecting the signal onto the subspace spanned by the selected atoms. This process is repeated until a stopping criterion is met (e.g., a desired sparsity level or error threshold). This whole process substitutes the encoding base network that was previously used in SimCLR.
The global loss function is summed across all positive pairs, representing the normalized temperature-scaled cross-entropy loss (NT-XEnt). The numerator encourages positive pairs to be closer, while the denominator introduces competition with all other representations in the batch, treating them as negatives. The contrastive loss can be interpreted as the maximization of the similarity between positive pairs in relation to the similarity between negative pairs. This process effectively forms a distribution over possible pairs, emphasizing the relative similarity of positive pairs over negatives. The temperature parameter controls the sharpness of the similarity scores. From a mathematical point of view, this parameter affects the relative weighting of similarities. A lower-value leads to sharper distributions, which heavily penalizes dissimilarities between positive pairs, leading to a stronger focus on very close positives. On the other hand, a higher-value treats similarities equally, which can lead to the avoidance of overemphasizing the few closest pairs. In general, the temperature term can be seen as controlling the entropy of the similarity distribution.
Using the NT-XEnt loss function, the full dictionary is updated using a Stochastic Gradient Descent (SGD) procedure, where the gradient is computed using reverse-mode automatic differentiation. The optimization result leads to more diverse quasi-orthogonal atoms that can better represent all the samples available in the training set. This problem is similar to a frame design problem, in which the atoms are designed to represent the samples better. In the context of SimCDL, we want to randomly initialize a dictionary and optimize it following the SGD procedure. Our experiments demonstrate that relevant results can be obtained for small batch sizes and several iterations, leading to better representation errors. The idea of SimCDL is summarized in Algorithm 1.
where and are different augmentations of . The maximization of mutual information for the data samples is related to the problem of reducing mutual coherence in the problem of dictionary learning. Since we want to enhance the representation capabilities (mutual information), more diverse atoms are needed, leading to a reduction in mutual coherence.
| Algorithm 1 SimCDL: main learning algorithm |
|
The use of SimCDL can be beneficial for the initialization of dictionaries with incoherent atoms or even incoherent sub-dictionaries. In classification problems, with representing a set of feature vectors, we want to learn local dictionaries, , for each class. In general, the initialization problem is not addressed; simple methods like random matrices or a random selection of signals are used for initialization; we will tackle the problem using SimCDL. Considering that a class dictionary, , should achieve good representations for its class, we will further adapt the SimCRL framework for the initialization of dictionaries in classification problems. Since we need C dictionaries, we will further optimize a wide dictionary, . During optimization, the sparsity constraint s is set to N, which is the number of atoms per class. Since we need N atoms, we want to overspecialize enough atoms for each class.
Source link
Denis C. Ilie-Ablachim www.mdpi.com