1. Introduction
Machine learning (ML) approaches as part of artificial intelligence systems for visual and sound pattern detection are receiving increasing popularity because of their high efficiency and comparatively simple application [
1,
2]. For instance, machine learning algorithms have been used to detect lesions in medical images [
3], leukemia in blood cell count data patterns [
4], movement and behavior of livestock [
5], individual pig recognition [
6], as well as face and speech recognition [
7,
8]. In the natural sciences, some identification applications of plants and animals (e.g., iNaturalist, observation.org) are assisted by artificial intelligence [
9], but the algorithms are usually not open source or freely available. Most ML algorithms were developed by hiring costly programmers and need considerable model training data for acceptable performance. Hence, for biologists with specialized (‘niche’) research questions, artificial intelligence systems such as those described above might be out of reach.
In addition, automated call detection and species identification of amphibians are less widely available compared to other taxa (e.g., birds and bats). The available tools are based on specific call characteristics such as pulse rate and frequency [
10], hence they might lack specificity in cases of species with similar calls, high levels of background noise, simultaneously calling individuals, or more specific research questions [
11]. Furthermore, manual or semi-automatic preprocessing steps of the audio files are often needed to improve detection performances [
12]. Thus, researchers would benefit from an easily adaptable small-scale approach, where they use familiar toolsets such as software R [
13] to implement ML into their data analysis.
Earlier research has shown that algorithms based on decision trees might be a promising avenue for anuran call recognition [
14]. A state-of-the-art candidate machine learning algorithm is the eXtreme Gradient boosting algorithm (XGboost) [
15]. It is a further development of the gradient boosting approach and has consistently performed very well in multiple competitions hosted by the Kaggle AI/ML community platform [
16]. Importantly, XGboost can be applied using all standard programming languages for statistical computing used in natural sciences, including R (via the xgboost package [
17]).
While many species sampling efforts in field biology are based on visual detection, some taxa can be easily identified by the sounds they produce. For instance, species-specific vocalizations can be used to monitor birds [
18] and frogs [
19]. Especially for citizen science, acoustic detection is already used to collect vast datasets of species distributions [
20,
21]. However, anuran species acoustic identification is hardly used in citizen science compared to bird or bat species [
22,
23,
24]. Recently the automated recording of soundscapes became a promising tool for efficient acoustic monitoring, even going beyond species identification [
25].
Despite the advances in digitalization and automatization, a lot of the call identification of recorded audio still requires time-consuming effort by researchers [
26,
27], in particular for citizen science projects that collect very large datasets [
28]. In part, utilizing existing ML algorithms or creating new ones might not be feasible (e.g., high costs); furthermore, the scope of existing algorithms might not fit the needs of a particular research question.
In the current study, we show that open-source tools can be easily used to develop a highly efficient call detection algorithm, at least for a single species, using the European green toad Bufotes viridis as an example. Our study is not a comparison between different possible detection algorithms, and there might be other equally or better performing solutions. However, for our approach, we provide a step-by-step instruction to reproduce our approach, with example sound files and annotated code including explanations on how it could be customized for other species. We expect our work to be of use to biologists working with sound data, extending the available tools in wildlife research.
4. Discussion
We demonstrate that customized, semi-automated, and highly accurate anuran call detection algorithms can be easily built and implemented using open-source software, if there are sufficient suitable reference vocalizations available. Our example protocol can be utilized by biologists of all areas working with sounds to build their own customized detection algorithm with little effort. Furthermore, we provide the tools in an environment (R) that should be familiar to a wide swath of researchers, running on major operating systems (Windows, Mac, Linux), and does not depend on external software companies or specialized programmers. However, like detection algorithms for bird songs (for example, the Merlin Bird ID application by The Cornell Lab of Ornithology), such tools may be integrated with available citizen science mobile phone applications such as iNaturalist or observation.org.
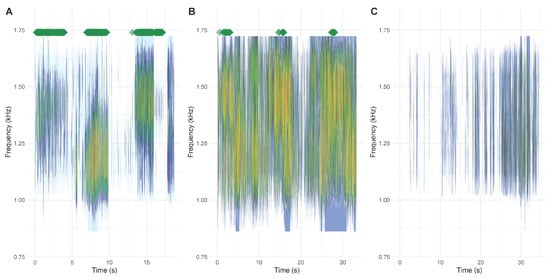
We show that the detection algorithm we built was robust and specific. It detected green toad calls when other amphibians were present, even with high background noise and low sound quality. However, great care should be taken in preparing the training and testing data sets to include sounds that are like the target species vocalizations, as well as common background noise. The best results are expected to be obtained when the training data cover the range of possible sound files to be evaluated by the algorithm. Hence, for a citizen science application, it would make sense to use the initial data collection period to obtain a training data set and then continue within the same framework but add the algorithm to speed up call identification. The size of the data set required likely varies a lot between research questions, target sound type, and file qualities.
Importantly, we prepared the algorithm to detect one specific call, the green toad breeding call. In cases of animals with several sound types (e.g., mating, warning, territorial calls), it might be possible to include all of them in one algorithm training procedure. However, in this case, the different calls could not be separated afterwards other than manually. Therefore, we would suggest training as many algorithms as there are sounds that should be detected and include all of them in one detection function. In this instance, one could differentiate not only if their target species is present, but also their behavioral state. The advantage of training several algorithms is that they can detect different sound types (e.g., warning versus mating) even when they are happening at the same time point. Similarly, one could train several algorithms for several different species and detect all of them in a single audio file, if all the algorithms are included in the detection function. Moreover, animal sounds can change from younger to older [
38] and smaller to larger individuals [
39] of the same species, potentially enabling researchers to estimate age/size structure through audio surveys.
We advise against training the data set on calls from one specific region and limited time frame in the season and then using the algorithms in a different area or/and different seasons. Small variations in call characteristics, but also background/non-target sounds between populations or regions (e.g., [
40]) that could be missed by human ears, might decrease the accuracy of algorithms trained and applied on sound files obtained from different locations. We noticed during testing that the training files for such algorithms should be within the range of files that you expect to obtain. For instance, training the algorithm on files of natural sounds but then testing files containing music (e.g., piano) will likely lead to false results.
Importantly, the majority of the sounds we analyzed were likely exclusively being collected with built-in smartphone microphones through the AmphiApp and directly saved in MP3 format. Thus, the sound quality might vary based on the specific hardware and software characteristics of individual devices and their ability to record and convert sounds in real time, the distance from the recording device to the calling toad, and/or background noise [
22,
41,
42]. Furthermore, the MP3 format is widely used for audio recording as it generates relatively small-size files but achieves this by using lossy data compression consisting of inexact approximations and the partial discarding of data (including reducing the accuracy of certain components of sound that are beyond the hearing capabilities of most humans). Therefore, care needs to be taken that key characteristics of the animal calls recorded and analyzed are not lost during recording/conversion and subsequently unavailable for analysis and recognition by the algorithm. Training data should thus include a range of sounds with varying recording quality. However, considering these limitations, at least in our case, the algorithm was robust and accurate even when analyzing recordings with quality deemed poor to the human listeners.
Using machine learning approaches for automated species detection in addition to professional (human) assessments could improve data quality for auditory surveys [
43,
44]. Such auditory surveys are common in amphibian ecology [
45] and can help monitor species distribution and to some extent even population trends. New developments in automated sound recording (e.g., soundscape recordings) could easily boost our understanding of the activity and distribution of calling amphibians, as it is already transforming marine acoustic studies [
46]. As most anuran calls are specifically related to reproductive efforts [
47], acoustic information is highly valuable, because it relates to a reproductively active population. In the future, such calls might also be used to assess the status of populations, as the calls are related to the size [
39] and potentially health status of individuals.
Source link
Lukas Landler www.mdpi.com