
1. Introduction
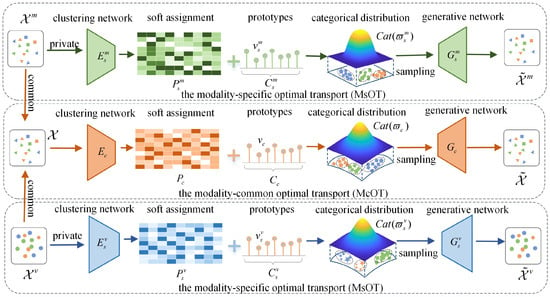
To address this challenge, an optimal-transport-based multimodal clustering method (OTMC) is proposed to conduct multimodal clustering structure mining based on the optimal-transport (OT) theory, which ensures clustering-friendly discriminative structures when fusing complementary modality information with heterogeneous distributions. Specifically, multimodal clustering is defined as a map from multimodal data measures to clustering prototype set measures in OTMC, which utilizes the Wasserstein distance to obtain clear discriminative structures from heterogeneous information with no intersection of data distributions in different modalities. Furthermore, OTMC is decomposed into a modality-specific OT (MsOT) and a modality-common OT (McOT) within a consistent constraint, to disentangle the transportation of private and shared information of each modality. In addition, a generative transport plan is designed to derive the variational solution to OT, which can effectively search the map with a minimal transport cost for mining intrinsic patterns. Finally, although designed for all data with heterogeneous distributions in different modalities, e.g., text and video, OTMC is conducted on four real-world benchmark image datasets in extensive experiments to validate its superiority on high-dimension data.
The main contributions of this paper are as follows:
An innovative weak-notion distance metric-based method is designed to measure differences between the manifold structures of data collected from diverse devices, which ensures the full fusion of complementary information from data with heterogeneous distributions.
Multimodal clustering is innovatively modeled using an optimal-transport-based multimodal clustering method (OTMC), which can capture fusion information with clear discriminative structures from heterogeneous modalities for mining intrinsic patterns.
A variational solution is derived to solve OT based on a generative transport plan, which can precisely match the transport map for transporting the multimodal data to clustering prototypes in OTMC.
Extensive experiments are conducted on four real-world benchmark datasets, which verify the superiority of OTMC compared with other methods in multimodal clustering, helped by never relying on the phantom of heterogeneous manifold intersections. In particular, OTMC obtains 92.15% ACC, 84.96% NMI, and 83.35% ARI on Handwritten, improving by 2.25%, 2.82%, and 3.28%, respectively.
2. Related Work
The deep fusion methods above extracted generalized fusion representations and then performed vanilla single-modality clustering methods to mine patterns, which may disconnect fusion representation learning and clustering partition, causing suboptimal fusion representations for clustering partition. The deep clustering methods above combined fusion representation learning and clustering partition into a joint optimization strategy for mining clustering structures in an end-to-end manner. However, they still relied on strong-notion distances to fuse crossmodal complementary knowledge, which limited their clustering performance. In contrast, optimal transport can define multimodal clustering as a map from multimodal data measures to clustering prototype set measures, which avoids representation-partition disconnections and dependency on the intersection of data distributions in different modalities.
Through the comparison between optimal transport and clustering, it can be seen that a difference between optimal transport and clustering is that optimal transport ex-changes the operation form for the lowest cost. That is, for any two mappings that map data points to cluster centers, optimal transport chooses the one with lowest cost and does not consider how it works. In a sense, optimal transport is more flexible and difficult than clustering. Thus, the solution to optimal transport can be used in clustering. In multimodal clustering, dividing the data into modality-specific and modality-common components is a standard approach. OTMC further distinguishes itself by incorporating the concept of optimal transport into this framework. Specifically, OTMC extends the rationale for optimal transport by partitioning it into modality-common and modality-specific components as well. This allows OTMC to better capture the intrinsic relationships both within and across modalities, offering a more nuanced representation of the data. In addition, there are diverse opinions about how to evaluate the quality of a clustering algorithm so that many metrics are proposed. If the objective of clustering is just minimizing the sum of distances in each cluster in k-means, no more problems appear. So, in this context, our method is a beneficial step toward providing a new direction for clustering, i.e., evaluating clustering quality based on transport cost.
4. The Variational Generative Solution to OTMC
In this section, a variational generative solution to OT is derived, and then, it is generalized to multimodal scenarios for optimizing data partitioning within an optimal-transport clustering network.
4.1. Variational Generative Solution
The variational generative solution learns the generative relationship between data and prototypes by constructing the joint distribution , which provides a theoretically accurate analytical solution to OT. Specifically, , where stands for the data distribution and denotes the cluster conditional distribution. Since the OT that transports the multimodal data to the clustering prototypes is actually finding the optimal prototype for each data point , which is fitting the cluster conditional distribution , the joint distribution has the same solution as OT.
where stands for the coupling cost between and . The optimal coupling solution is obtained by reaching the infimum of the total coupling cost over the product space .
where is the ground transport cost between and . After fitting the categorical prior distribution and the generative conditional distribution , can be obtained via the Bayesian rule.
4.2. The Variational Generative Solution to OTMC
where is the generative transport map of the -th modality, and generates instances from the categorical distribution, which can retain the real underlying structure information under the supervision of multimodal data. The generative transport plan and the categorical distribution can jointly learn the private data structure information and clustering information of the -th modality.
where indicates the -th modality, and the objective function fully captures inherent information of the -th modality by jointly learning structure differences between data and semantic information within data.
where is the generative transport map for all modalities, which can generate data of all modalities from the common categorical distribution to capture common semantics of data.
The objective function effectively preserves common information in multimodal data by jointly optimizing the structure differences of all modalities and crossmodal semantic information.
where denotes the consistent constraint of categorical prior distributions and , which enables MsOT and McOT to have the same transport target, so that the results of the two transport schemes tend to be the same. It is implemented by the KL-divergence penalty between and .
4.3. Multimodal OT Clustering Network
Although they attract much attention from researchers, generative adversarial networks (GANs) involve performance-unstable and computation-expensive adversarial training. Hence, to implement OTMC, a multimodal OT clustering network is designed within a deep neural network architecture which contains a generative network and a clustering network, instead of a GAN. The generative network implements the generative transport plan together with the categorical distribution , and the clustering network produces final assignment results from multimodal data.
where is the -th instance from the -th modality; is the -th clustering prototype of the -th modality; and can be interpreted as the possibility that the -th instance is divided into the -th cluster. To guide the learning of networks, a target distribution is introduced, and the KL-divergence between and the soft-assignment matrix is used as the objective function:
where is the target assignment possibility of the -th instance to the -th clustering prototype. This objective function guides network learning by aligning the soft assignment to the target probability distribution.
where denotes the KL-divergence between two assignment matrices. The first term guides the network to learn the clustering information within each modality, the second term is the consistency constraint of modality-specific and modality-common clustering information, and the last term guides the network to capture the clustering information over all modalities. Finally, the soft-assignment matrix is used as the cluster assignment matrix.
where is the categorical distribution of the -th modality with parameter . To update the parameter of the generative network and the categorical distribution parameter , the topological reconstruction loss between the generative data and the original data is used as a guide, namely,
where represents the topological reconstruction loss based on optimal transport to measure the differences in manifold structures between original and reconstructed data. The network structure and loss of the generative network of McOT are similar to those of MsOT. So, the total objection function of generative networks can be written as follows:
where the purpose of the first term is to optimize the categorical distribution and generative network within the modality, and the purpose of the second term is to optimize over all modalities, capturing the data structure information within and between modalities, respectively.
4.4. The Overall Loss
where denotes the trade-off parameter for balancing the topological reconstruction loss and clustering pattern mining loss , and is used to optimize the multimodal OT clustering network via the stochastic gradient descent strategy, which effectively boosts the performance of multimodal clustering:
where
and
denote the parameter and the learning rate of the multimodal OT clustering network at time step
, respectively, and
denotes the gradient at time step
. The overall optimization algorithm is shown in Algorithm 1.
| Algorithm 1. Multimodal OT clustering network. |
| Input: Multimodal dataset and convergence criteria thr. Output: Soft-clustering-assignment matrix and the parameters of clustering network , generative network categorical distribution . Initialize: modality-specific categorical distributions modality-common categorical distribution parameters of modality-specific clustering networks , parameters of modality-common clustering network , parameters of modality-specific generative networks , and parameters of modality-common generative network while convergence criteria thr is not reached by Equation (19) do for each do Sample data in the -th modality . Generate the -th modality soft-assignment matrix according to Equation (13). Update by minimizing Equation (14). Sample modality-specific clustering prototypes from . Generate the -th modality reconstructed data according to Equation (16). Update and by minimizing Equation (17). end Sample multimodal data . Generate modality-common soft-assignment matrix . Update modality-common clustering network by minimizing Equation (15). Sample modality-common clustering prototypes from . Generate multimodal reconstructed data. Update modality-common generative network by minimizing Equation (18). Update all network parameters by minimizing Equation (19) according to Equation (20). end |
6. Conclusions
A multimodal clustering method based on optimal transport (OTMC) is designed in this paper to mine intrinsic patterns from the fusion information of multimodal data. It utilizes the weak-notion distance to measure the differences among heterogeneous manifolds, which overcomes the fragile assumption on strict overlaps between data manifolds in previous MC methods. In particular, multimodal clustering is defined as the transport mapping between multimodal data and clustering prototypes, which effectively fuses the complementary information in multimodal data. Then, the variational solution to OT is derived based on a generative transport plan, which utilizes fusion information to produce accurate clustering patterns. Afterwards, a multimodal OT clustering network is designed to achieve the above definition. Finally, extensive experiments illustrate the superiority of OTMC.
The possible future directions of this research are three-fold: First, in current OTMC, the transport plan is completely implemented by a deep neural network. Hence, the performance of OTMC heavily depends on the degree of fitting between the deep neural network and the real transport plan, which introduces uncertainty and may be a potential limitation. In the future, a variational solution with more compact margins will be explored to address this dependence and achieve a more precise map for pattern mining. Second, the performance of OTMC on different types of multimodal datasets, especially those with varying degrees of distribution overlap or complementarity across modalities via feature engineering, will be checked to further verify the theoretical basis of OTMC. Third, OTMC will be tried in other multimodal data learning cases such as graph data classification and time series prediction.
Source link
Zheng Yang www.mdpi.com