
1. Introduction
Accordingly, in this paper, we propose leveraging existing real-time talking portrait generation techniques to create an interactive avatar and evaluate its potential for improving perceived realism and interaction quality.
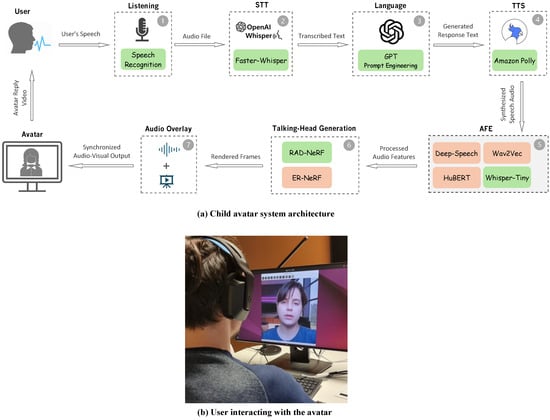
- Integrating a complete AI-based avatar system combining GPT-3 for conversations, Speech-To-Text (STT), Text-To-Speech (TTS), AFE, and talking portrait synthesis (Figure 1) for full end-to-end experiments.
Evaluating and comparing talking-head synthesis models.
Evaluation and comparison of four AFE models using two open-source talking-head frameworks across three datasets.
Modifying Whisper for efficient and accelerated AFE in talking portrait systems.
Assessing and discussing the best combinations of talking portrait synthesis systems and AFE systems.
2. Related Work
The development and research of our avatar is touching upon two main areas: virtual avatars for interviewer training and real-time talking portrait synthesis. Notably, avatar systems provide the interactive framework necessary for dynamic user engagement, while talking portrait synthesis improves visual and auditory realism. Together, these technologies address both interaction logic and expressive fidelity, forming a synergistic foundation for our solution. This integration is vital for achieving a immersive user experience.
2.1. Virtual Avatar for Interview Training
2.2. Talking Portrait Synthesis
In recent years, real-time audio-driven talking portrait synthesis has gained significant attention, driven by applications in digital humans, virtual avatars, and video conferencing. Several approaches have been proposed to balance visual quality, synchronization, and computational efficiency.
In the following, we discuss recent advancements in real-time audio-driven talking portrait synthesis, which build on these foundational methods to improve computational efficiency while maintaining synchronization and visual quality.
3. Methodology
This section introduces the AFE models Deep-Speech 2, Wav2Vec 2.0, HuBERT, and Whisper, which we compare in this study, and outlines the interactive avatar’s system architecture.
3.1. Audio Feature Extraction
3.1.1. Deep-Speech 2
3.1.2. Wav2Vec 2.0
3.1.3. HuBERT
3.1.4. Whisper
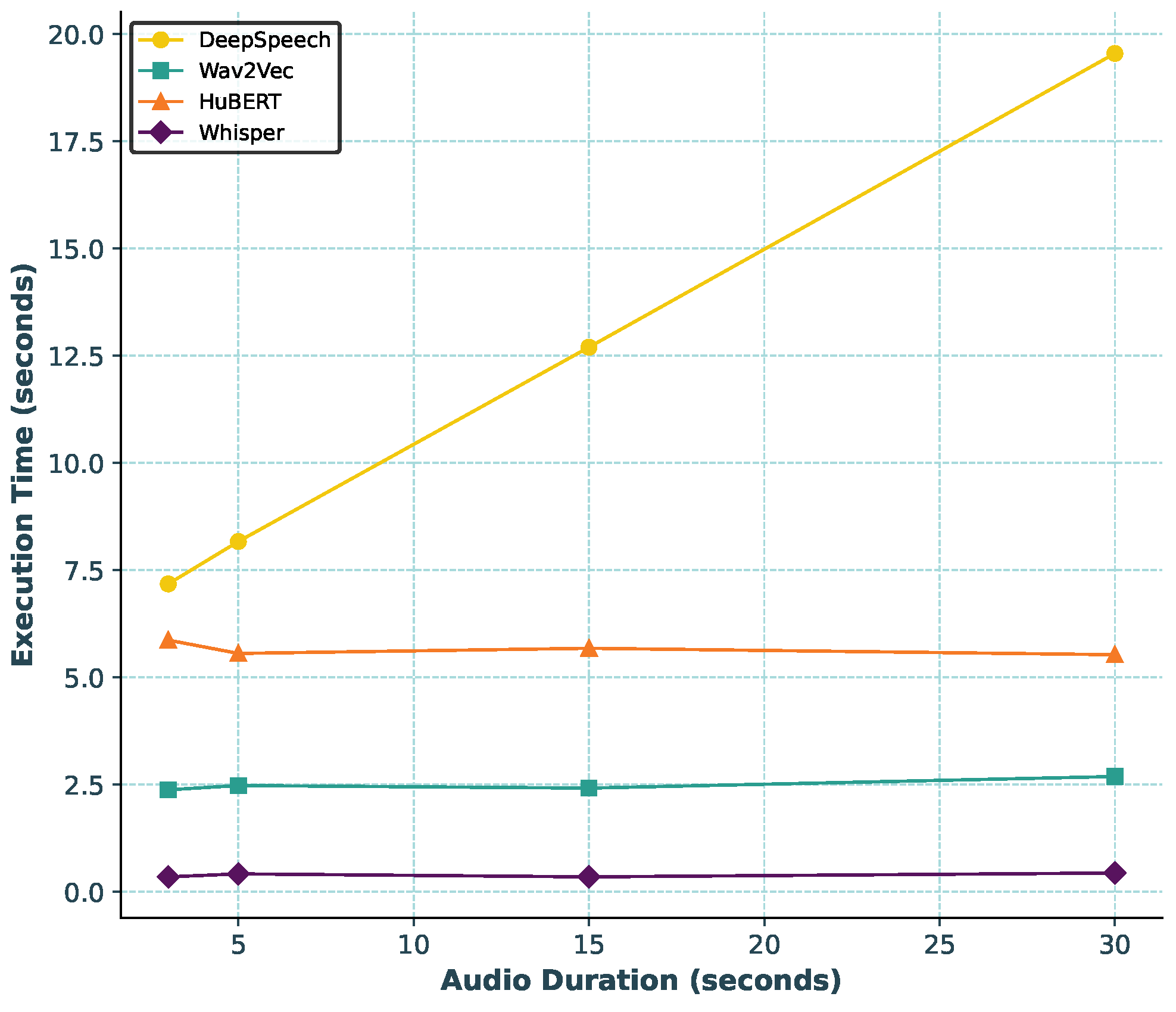
The Whisper model’s design has demonstrated a substantial 80–90% reduction in processing times compared to alternative models like Deep-Speech, Wav2Vec, and HuBERT, particularly for longer audio clips.
where E has shape , with T representing the number of time steps aligned to the visual frames, and as the dimensionality of the feature embedding space. Synchronization with a 25 FPS visual frame rate is achieved by applying a sliding window with parameters , stride , and padding , yielding a final feature matrix with shape . This setup ensures precise temporal alignment across 750 frames over 30 s, enhancing the real-time accuracy and fluidity of interactions in talking-head applications.
3.2. System Architecture
The Listening module is the entry point of the system, where user speech is captured through a button-based recording process. Users click to start recording their voice input and click again to stop, saving the recorded audio file. During this recording phase, the avatar remains in a listening state, utilizing a pre-rendered video based on an empty audio file where it exhibits natural, non-verbal behaviors such as blinking and subtle movements while remaining silent. This module employs a speech recognition system to continuously listen for spoken input from the user, initiating the conversion process by passing the audio data to the speech-to-text module.
4. Experiments
This section rigorously evaluates various AFE models across two frameworks, focusing on model efficiency, synchronization accuracy, and responsiveness.
4.1. Experimental Setup
In this section, our datasets, hardware, and configurations are outlined for evaluating AFE model performance in real-time talking portrait synthesis.
4.1.1. Dataset
4.1.2. System Configuration
Experiments are conducted on a machine with a 12th Gen Intel(R) Core(TM) i9-12900F CPU, 31 GiB of RAM, and an NVIDIA RTX 4090 GPU with 24 GiB of VRAM, running CUDA 12.4 on an Ubuntu operating system.
4.2. Real-Time Talking-Head Speed Analysis
4.3. AFE Analysis
4.3.1. AFE Speed Analysis
4.3.2. AFE Quality Analysis
To further validate utilizing Whisper as AFE, we conduct an evaluation of the system’s rendering quality across various settings. In the self-driven setting, where the ground truth data correspond to the same identity as the generated output, we utilize the widely recognized quantitative metrics to assess the quality of portrait reconstruction. These metrics are standard in the field and provide a comprehensive assessment of both visual fidelity and synchronization, ensuring alignment with the established evaluation practices:
- Peak Signal-to-Noise Ratio (PSNR): This metric measures the fidelity of the reconstructed image relative to the ground truth. The PSNR is calculated as
where is the maximum possible pixel value of the image, and MSE is the Mean Squared Error between the reconstructed and ground truth images.
- Structural Similarity Index Measure (SSIM): SSIM evaluates the structural similarity by considering the luminance, contrast, and structure. The formula is
where and are the average intensities, and are variances, and is the covariance between images x and y. and are constants for stability.
- Learned Perceptual Image Patch Similarity (LPIPS) [47]: Measures the perceptual similarity between the generated and ground truth images by calculating the distance between feature representations extracted from a deep neural network. This metric captures differences in visual features that align more closely with human perception than simple pixel-wise comparisons, making it useful for assessing image quality in terms of perceptual fidelity:
where represents the feature representation of image x extracted by a neural network (e.g., AlexNet), and are the predicted and ground truth images respectively, and N is the number of patches or feature points compared.
- Landmark Distance (LMD) [48]: This metric measures the geometric accuracy of facial landmarks by calculating the Euclidean distance between corresponding landmark points in the generated and ground truth images:
where and are the coordinates of the i-th landmark in the predicted and ground truth images, respectively, and N is the total number of landmarks.
- Fréchet Inception Distance (FID) [49]: FID assesses the similarity between distributions of real and generated images. The formula is
where and represent the mean and covariance of features for real images, and and represent those for generated (images).
- Action Units Error (AUE) [50]: AUE measures the accuracy of lower facial muscle movements by calculating the squared differences in action unit intensities between the generated and ground truth images. In this study, we specifically evaluate the lower face region, which is relevant for expressions related to speech and emotion:
where and are the intensities of the i-th action unit in the lower face region for the predicted and ground truth data, respectively, and N is the total number of lower face action units evaluated.
- SyncNet Confidence Score (Sync) [51]: Measures the lip-sync accuracy by evaluating the alignment between audio and lip movements in generated talking-head videos. This metric utilizes SyncNet, which calculates a confidence score based on the similarity between the embeddings of audio and video frames:
where and are the embeddings for the i-th video and audio frames, respectively, computed by SyncNet. This formula calculates the cosine similarity between the embeddings, giving a score between 0 and 1 for each frame pair. N is the total number of frame pairs evaluated, and higher average values indicate better lip-sync quality.
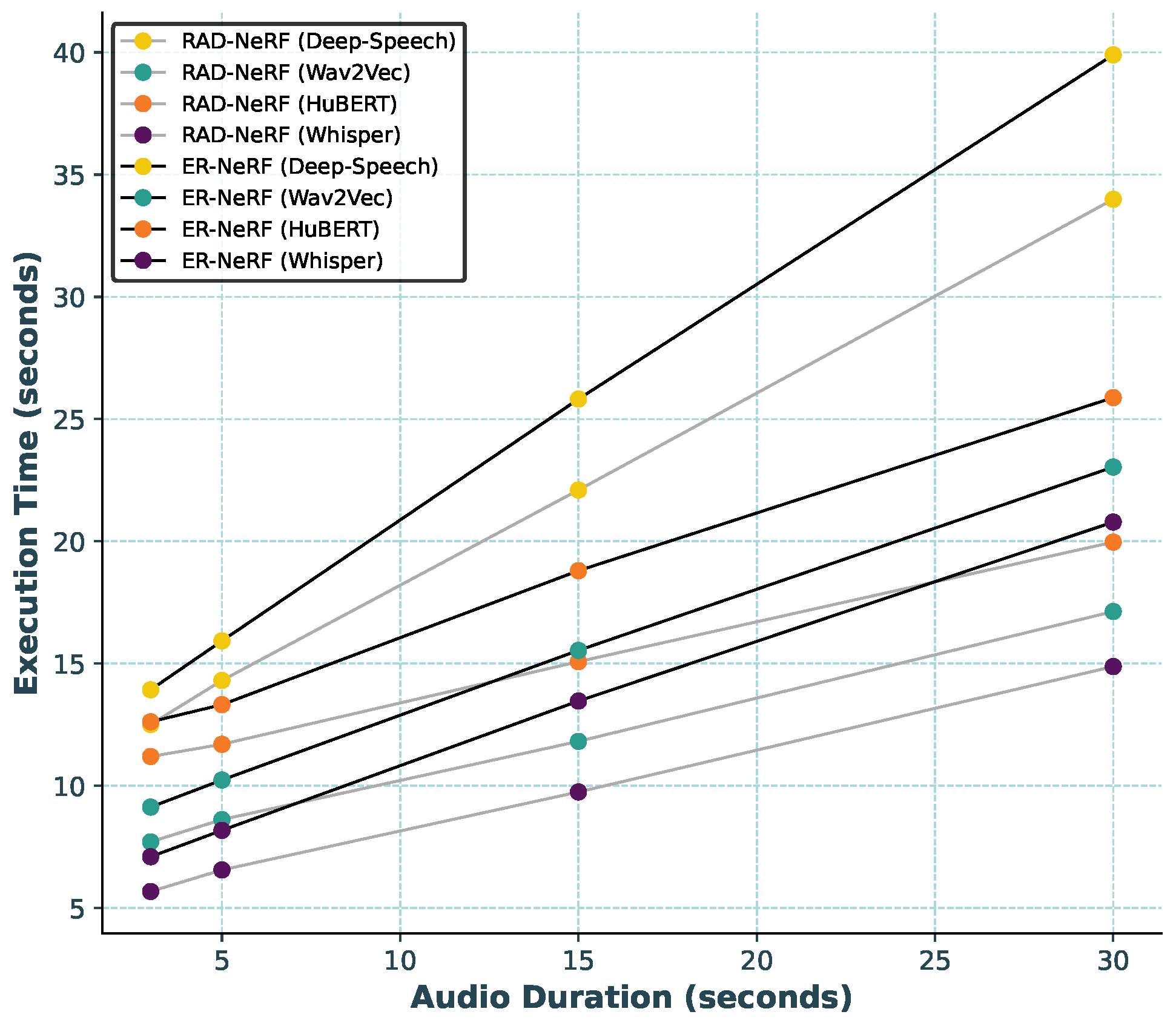
Our experimental results reveal that HuBERT consistently underperforms in lip synchronization, with the lowest Sync scores among all the models tested. Given these results, particularly the poor performance in cross-driven settings (e.g., Sync scores as low as 0.564), HuBERT appears inadequate for applications requiring precise lip-sync. Future work should consider incorporating subjective evaluations to further assess the perceptual quality and user satisfaction, which may provide a more thorough understanding of its limitations.
ER-NeRF and RAD-NeRF demonstrate varying degrees of fidelity across the AFEs, particularly in achieving accurate lip-sync with the audio input. Generally, Whisper achieves the closest approximation to ground truth across both ER-NeRF and RAD-NeRF, exhibiting strong performance in synchronizing lip movements with audio, especially during pronounced lip articulations, such as the wide-open mouth movements observed when pronouncing sounds like “wa.” This precise alignment enhances the realism of the output, particularly in sequences requiring dynamic mouth shapes.
Wav2vec and HuBERT provide reasonable approximations but show slight misalignments in lip-sync. Deep-Speech, while effective, displays the greatest variance from ground truth, with notable lip-sync discrepancies, indicating less robust performance in these NeRF-based reconstructions.
4.4. System Responsiveness Analysis
To evaluate the system’s responsiveness, we test various lengths of avatar answers. This approach allows us to assess how the system handles different interaction complexities, ranging from brief exchanges like “Hi” and “I’m OK” to more extended dialogues, such as “Um… at Jenny’s house, we play a lot. It’s nice there… but, well, I don’t really like talking about the pool. It wasn’t very fun last time”. The results indicate that while the overall system performs efficiently, the frame rendering stages are identified as the most time-consuming, due to the computational demands of generating high-quality, real-time visual output that matches the synchronized audio input.
Conversely, the integration of the Whisper model as the AFE component proves to be much faster than the conventional AFE models. Whisper’s improved processing speed has substantially reduced the time required to extract and synchronize audio features, contributing to a faster overall system performance.
5. Discussion and Future Work
However, despite Whisper’s efficiency, the overall system still experiences latency due to other computationally intensive components, such as frame rendering. This issue becomes more pronounced when changes in hardware specifications significantly affect the frame rendering time of talking-head generation models. Addressing these bottlenecks and further exploring system scalability across diverse hardware configurations are essential steps toward improving real-world applicability and robustness.
Moreover, although Whisper has demonstrated significant advantages in two real-time talking-head synthesis models, its adoption should not be presumed universally effective across all models or contexts. Each talking-head generation model leverages unique strategies and architectures tailored to specific applications, which may necessitate alternative feature extraction approaches. The diversity in model designs underscores the importance of contextual considerations when selecting feature extraction methods. Nevertheless, Whisper’s robust real-time capabilities suggest potential for future integration as a preprocessing step in emerging systems, particularly those prioritizing real-time performance. Such integration could streamline audio processing pipelines, enhancing efficiency without compromising synchronization or quality. This outlook provides a promising direction for optimizing real-time systems while acknowledging the necessity for model-specific customization.
Another limitation of the current work is the absence of a robust framework for handling errors or implementing fallback mechanisms across the modular pipeline components. In modular systems, individual component failures can propagate through the pipeline, potentially compromising both system reliability and real-time performance. To address these challenges, future research should prioritize the development of dynamic error detection and mitigation strategies.
Furthermore, conducting broader user studies with professionals in the field could provide a deeper understanding of the system’s impact on practical outcomes, such as user training and engagement. Expanding this research to include real-world evaluations with subjective user feedback will offer valuable insights into perceived realism, usability, and overall user satisfaction. Incorporating user-centric metrics will provide a more comprehensive view of the system’s effectiveness in high-engagement applications, such as investigative interview training. Through these advancements, AI-driven avatars may achieve greater utility and realism, enhancing their role as effective tools in training applications.
Ethical Considerations
Despite these challenges, AI avatars offer unique opportunities for societal good. They provide CPS workers with realistic, interactive training tools that avoid involving real children, thus eliminating ethical dilemmas and ensuring victim privacy. Additionally, they can anonymize sensitive victim data, preserving dignity and confidentiality. To balance the benefits and risks, a multidisciplinary approach is important. Collaboration among technologists, legal experts, child protection professionals, and ethicists can ensure AI technologies are leveraged responsibly. Developing robust detection systems to identify misuse, alongside legal frameworks to regulate the deployment of such technology, is essential for protecting vulnerable populations.
6. Conclusions
This study addressed the latency challenges associated with AFE, which has hindered the practical deployment of real-time talking portrait systems in real-world applications. By integrating the Whisper model—a high-performance ASR system—into our framework, we achieved notable reductions in processing delays. These optimizations not only increased the overall responsiveness of the interactive avatars but also improved the accuracy of lip-syncing, making them more applicable for immersive training applications.
Our findings affirm Whisper’s capability to meet real-time demands, particularly in applications requiring responsive interactions and minimal delay. This efficiency is important for training environments such as CPS, where timely and realistic interactions can greatly impact training efficacy. By achieving these improvements, Whisper-integrated systems emerge as promising solutions for a variety of real-time applications, including virtual assistants, remote education, and digital customer service platforms.
Author Contributions
Conceptualization, P.S., S.A.S., V.T., S.S.S., M.A.R. and P.H.; methodology, P.S., S.A.S., V.T. and P.H.; software, P.S., S.A.S. and S.G.; validation, P.S., S.A.S. and S.G.; formal analysis, P.S.; investigation, P.S.; resources, P.H. and M.A.R.; data curation, P.S. and S.A.S.; writing—original draft preparation, P.S., S.A.S. and P.H.; writing—review and editing, P.S., S.A.S., V.T., S.G., S.S.S., D.J., M.A.R. and P.H.; visualization, P.S. and S.A.S.; supervision, V.T., S.S.S., D.J., M.A.R. and P.H.; project administration, P.S. and P.H.; funding acquisition, M.A.R. and P.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Research Council of Norway grant number #314690.
Institutional Review Board Statement
Ethical approval has been obtained from The Norwegian Agency for Shared Services in Education and Research.
Informed Consent Statement
Informed consent for participation was obtained from all subjects involved in the study.
Data Availability Statement
Conflicts of Interest
Author Saeed S. Sabet was employed by the company Forzasys. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Chernikova, O.; Heitzmann, N.; Stadler, M.; Holzberger, D.; Seidel, T.; Fischer, F. Simulation-based learning in higher education: A meta-analysis. Rev. Educ. Res. 2020, 90, 499–541. [Google Scholar] [CrossRef]
- Crompton, H.; Bernacki, M.; Greene, J.A. Psychological foundations of emerging technologies for teaching and learning in higher education. Curr. Opin. Psychol. 2020, 36, 101–105. [Google Scholar] [CrossRef] [PubMed]
- Lamb, M.E. Difficulties translating research on forensic interview practices to practitioners: Finding water, leading horses, but can we get them to drink? Am. Psychol. 2016, 71, 710. [Google Scholar] [CrossRef] [PubMed]
- Powell, M.B. Designing effective training programs for investigative interviewers of children. Curr. Issues Crim. Justice 2008, 20, 189–208. [Google Scholar] [CrossRef]
- Lamb, M.E.; Orbach, Y.; Hershkowitz, I.; Esplin, P.W.; Horowitz, D. A structured forensic interview protocol improves the quality and informativeness of investigative interviews with children: A review of research using the NICHD Investigative Interview Protocol. Child Abuse Negl. 2007, 31, 1201–1231. [Google Scholar] [CrossRef] [PubMed]
- Lyon, T.D. Interviewing children. Annu. Rev. Law Soc. Sci. 2014, 10, 73–89. [Google Scholar] [CrossRef]
- Lamb, M.E.; Brown, D.A.; Hershkowitz, I.; Orbach, Y.; Esplin, P.W. Tell Me What Happened: Questioning Children About Abuse; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Powell, M.B.; Brubacher, S.P.; Baugerud, G.A. An overview of mock interviews as a training tool for interviewers of children. Child Abuse Negl. 2022, 129, 105685. [Google Scholar] [CrossRef] [PubMed]
- Salehi, P.; Hassan, S.Z.; Baugerud, G.A.; Powell, M.; Johnson, M.S.; Johansen, D.; Sabet, S.S.; Riegler, M.A.; Halvorsen, P. A theoretical and empirical analysis of 2D and 3D Virtual Environments in Training for Child Interview Skills. IEEE Access 2024, 12, 131842–131864. [Google Scholar] [CrossRef]
- Salehi, P.; Hassan, S.Z.; Shafiee Sabet, S.; Astrid Baugerud, G.; Sinkerud Johnson, M.; Halvorsen, P.; Riegler, M.A. Is more realistic better? A comparison of game engine and gan-based avatars for investigative interviews of children. In Proceedings of the 3rd ACM Workshop on Intelligent Cross-Data Analysis and Retrieval, Newark, NJ, USA, 27–30 June 2022; pp. 41–49. [Google Scholar]
- Mildenhall, B.; Srinivasan, P.P.; Tancik, M.; Barron, J.T.; Ramamoorthi, R.; Ng, R. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 2021, 65, 99–106. [Google Scholar] [CrossRef]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Hsu, W.N.; Tsai, Y.H.H.; Bolte, B.; Salakhutdinov, R.; Mohamed, A. HuBERT: How much can a bad teacher benefit ASR pre-training? In Proceedings of the ICASSP 2021–2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; pp. 6533–6537. [Google Scholar]
- Chakhtouna, A.; Sekkate, S.; Abdellah, A. Unveiling embedded features in Wav2vec2 and HuBERT msodels for Speech Emotion Recognition. Procedia Comput. Sci. 2024, 232, 2560–2569. [Google Scholar] [CrossRef]
- Schubert, M.E.; Langerman, D.; George, A.D. Benchmarking Inference of Transformer-Based Transcription Models with Clustering on Embedded GPUs. IEEE Access 2024, 12, 123276–123293. [Google Scholar] [CrossRef]
- Chakravarty, A. Deep Learning Models in Speech Recognition: Measuring GPU Energy Consumption, Impact of Noise and Model Quantization for Edge Deployment. arXiv 2024, arXiv:2405.01004. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust speech recognition via large-scale weak supervision. In Proceedings of the International Conference on Machine Learning. PMLR, Honolulu, HI, USA, 23–29 July 2023; pp. 28492–28518. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in english and mandarin. In Proceedings of the International Conference on Machine Learning. PMLR, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Salehi, P. Whisper AFE for Talking Heads Generation, Version 1.0.0. 2024. Available online: https://github.com/pegahs1993/Whisper-AFE-TalkingHeadsGen (accessed on 20 February 2025).
- Dalli, K.C. Technological Acceptance of an Avatar Based Interview Training Application: The Development and Technological Acceptance Study of the AvBIT Application. 2021. Available online: http://urn.kb.se/resolve?urn=urn:nbn:se:lnu:diva-107108 (accessed on 20 January 2025).
- Røed, R.K.; Powell, M.B.; Riegler, M.A.; Baugerud, G.A. A field assessment of child abuse investigators’ engagement with a child-avatar to develop interviewing skills. Child Abuse Negl. 2023, 143, 106324. [Google Scholar] [CrossRef]
- Benson, M.S.; Powell, M.B. Evaluation of a comprehensive interactive training system for investigative interviewers of children. Psychol. Public Policy Law 2015, 21, 309. [Google Scholar] [CrossRef]
- Pompedda, F. Training in Investigative Interviews of Children: Serious Gaming Paired with Feedback Improves Interview Quality. Doctoral Dissertation, Åbo Akademi University, Turku, Finland, 2018. [Google Scholar]
- Krause, N.; Gewehr, E.; Barbe, H.; Merschhemke, M.; Mensing, F.; Siegel, B.; Müller, J.L.; Volbert, R.; Fromberger, P.; Tamm, A.; et al. How to prepare for conversations with children about suspicions of sexual abuse? Evaluation of an interactive virtual reality training for student teachers. Child Abuse Negl. 2024, 149, 106677. [Google Scholar] [CrossRef] [PubMed]
- Meng, M.; Zhao, Y.; Zhang, B.; Zhu, Y.; Shi, W.; Wen, M.; Fan, Z. A Comprehensive Taxonomy and Analysis of Talking Head Synthesis: Techniques for Portrait Generation, Driving Mechanisms, and Editing. arXiv 2024, arXiv:2406.10553. [Google Scholar]
- Lu, Y.; Chai, J.; Cao, X. Live speech portraits: Real-time photorealistic talking-head animation. ACM Trans. Graph. (ToG) 2021, 40, 1–17. [Google Scholar] [CrossRef]
- Chung, Y.A.; Glass, J. Generative pre-training for speech with autoregressive predictive coding. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 3497–3501. [Google Scholar]
- Ji, X.; Lin, C.; Ding, Z.; Tai, Y.; Yang, J.; Zhu, J.; Hu, X.; Zhang, J.; Luo, D.; Wang, C. RealTalk: Real-time and Realistic Audio-driven Face Generation with 3D Facial Prior-guided Identity Alignment Network. arXiv 2024, arXiv:2406.18284. [Google Scholar]
- Kerbl, B.; Kopanas, G.; Leimkühler, T.; Drettakis, G. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Trans. Graph. 2023, 42, 1–25. [Google Scholar] [CrossRef]
- Chen, B.; Hu, S.; Chen, Q.; Du, C.; Yi, R.; Qian, Y.; Chen, X. GSTalker: Real-time Audio-Driven Talking Face Generation via Deformable Gaussian Splatting. arXiv 2024, arXiv:2404.19040. [Google Scholar]
- Cho, K.; Lee, J.; Yoon, H.; Hong, Y.; Ko, J.; Ahn, S.; Kim, S. GaussianTalker: Real-Time Talking Head Synthesis with 3D Gaussian Splatting. In Proceedings of the ACM Multimedia 2024, Melbourne, Australia, 28 October–1 November 2024. [Google Scholar]
- Tang, J.; Wang, K.; Zhou, H.; Chen, X.; He, D.; Hu, T.; Liu, J.; Zeng, G.; Wang, J. Real-time neural radiance talking portrait synthesis via audio-spatial decomposition. arXiv 2022, arXiv:2211.12368. [Google Scholar]
- Guo, Y.; Chen, K.; Liang, S.; Liu, Y.J.; Bao, H.; Zhang, J. Ad-nerf: Audio driven neural radiance fields for talking head synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 5784–5794. [Google Scholar]
- Li, J.; Zhang, J.; Bai, X.; Zhou, J.; Gu, L. Efficient region-aware neural radiance fields for high-fidelity talking portrait synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 7568–7578. [Google Scholar]
- Ye, Z.; He, J.; Jiang, Z.; Huang, R.; Huang, J.; Liu, J.; Ren, Y.; Yin, X.; Ma, Z.; Zhao, Z. Geneface++: Generalized and stable real-time audio-driven 3d talking face generation. arXiv 2023, arXiv:2305.00787. [Google Scholar]
- Ye, Z.; Zhang, L.; Zeng, D.; Lu, Q.; Jiang, N. R2-Talker: Realistic Real-Time Talking Head Synthesis with Hash Grid Landmarks Encoding and Progressive Multilayer Conditioning. arXiv 2023, arXiv:2312.05572. [Google Scholar]
- Schuster, M.; Paliwal, K.K. Bidirectional recurrent neural networks. IEEE Trans. Signal Process. 1997, 45, 2673–2681. [Google Scholar] [CrossRef]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 716–731. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian error linear units (gelus). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Baevski, A.; Schneider, S.; Auli, M. vq-wav2vec: Self-supervised learning of discrete speech representations. arXiv 2019, arXiv:1910.05453. [Google Scholar]
- Jegou, H.; Douze, M.; Schmid, C. Product quantization for nearest neighbor search. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 117–128. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An asr corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar]
- Kahn, J.; Riviere, M.; Zheng, W.; Kharitonov, E.; Xu, Q.; Mazaré, P.E.; Karadayi, J.; Liptchinsky, V.; Collobert, R.; Fuegen, C.; et al. Libri-light: A benchmark for asr with limited or no supervision. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 7669–7673. [Google Scholar]
- Joshi, M.; Chen, D.; Liu, Y.; Weld, D.S.; Zettlemoyer, L.; Levy, O. Spanbert: Improving pre-training by representing and predicting spans. Trans. Assoc. Comput. Linguist. 2020, 8, 64–77. [Google Scholar] [CrossRef]
- Ye, Z.; Jiang, Z.; Ren, Y.; Liu, J.; He, J.; Zhao, Z. Geneface: Generalized and high-fidelity audio-driven 3D talking face synthesis. arXiv 2023, arXiv:2301.13430. [Google Scholar]
- Amazon Web Services. AWS Polly. Web Services. Amazon. 2024. Available online: https://aws.amazon.com/polly/ (accessed on 28 September 2024).
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 586–595. [Google Scholar]
- Chen, L.; Li, Z.; Maddox, R.K.; Duan, Z.; Xu, C. Lip movements generation at a glance. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 520–535. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6626–6637. [Google Scholar]
- Baltrušaitis, T.; Robinson, P.; Morency, L.P. Openface: An open source facial behavior analysis toolkit. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Chung, J.S.; Zisserman, A. Out of time: Automated lip sync in the wild. In Proceedings of the Computer Vision–ACCV 2016 Workshops: ACCV 2016 International Workshops, Taipei, Taiwan, 20–24 November 2016; pp. 251–263. [Google Scholar]
- Attig, C.; Rauh, N.; Franke, T.; Krems, J.F. System latency guidelines then and now–is zero latency really considered necessary? In Proceedings of the Engineering Psychology and Cognitive Ergonomics: Cognition and Design: 14th International Conference, EPCE 2017, Vancouver, BC, Canada, 9–14 July 2017; pp. 3–14. [Google Scholar]
- Forch, V.; Franke, T.; Rauh, N.; Krems, J.F. Are 100 ms fast enough? Characterizing latency perception thresholds in mouse-based interaction. In Proceedings of the Engineering Psychology and Cognitive Ergonomics: Cognition and Design: 14th International Conference, EPCE 2017, Vancouver, BC, Canada, 9–14 July 2017; pp. 45–56. [Google Scholar]
- Meskys, E.; Kalpokiene, J.; Jurcys, P.; Liaudanskas, A. Regulating deep fakes: Legal and ethical considerations. J. Intellect. Prop. Law Pract. 2020, 15, 24–31. [Google Scholar] [CrossRef]
- Hu, H. Privacy Attacks and Protection in Generative Models. 2023. Available online: https://hdl.handle.net/10993/58928 (accessed on 20 February 2025).
- Kugler, M.B.; Pace, C. Deepfake privacy: Attitudes and regulation. Northwestern Univ. Law Rev. 2021, 116, 611. [Google Scholar] [CrossRef]
(a) System architecture of the interactive child avatar, detailing the integration of key modules: (1) Listening, (2) STT, (3) Language Processing, (4) TTS, (5) AFE, (6) Frames Rendering, and (7) Audio Overlay. This setup simulates natural conversation, allowing the user to interact with the avatar as if communicating with a real person. (b) User interaction with the child avatar system.
Figure 1.
(a) System architecture of the interactive child avatar, detailing the integration of key modules: (1) Listening, (2) STT, (3) Language Processing, (4) TTS, (5) AFE, (6) Frames Rendering, and (7) Audio Overlay. This setup simulates natural conversation, allowing the user to interact with the avatar as if communicating with a real person. (b) User interaction with the child avatar system.
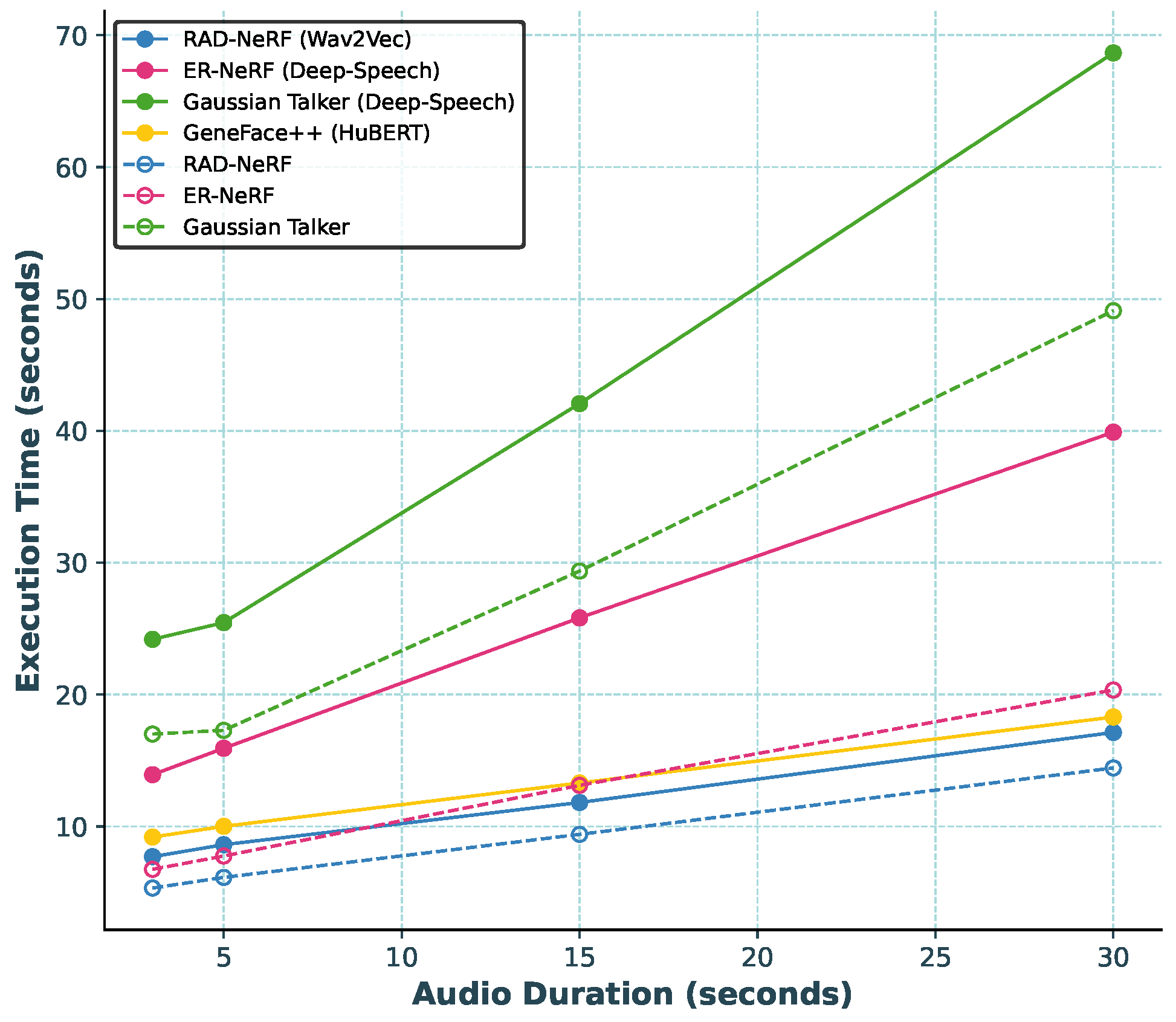
Execution time comparison of open-source real-time talking-head generation models, including RAD-NeRF [32], ER-NeRF [34], Gaussian Talker [31] and GeneFace++ [35]. The solid lines represent execution times excluding AFE, while the dashed lines indicate execution times that include AFE.
Execution time comparison of different AFE models, including Deep-Speech [18], Wav2Vec [12], HuBERT [13], and Whisper [17].
Quality comparison: Examples of visualizations of RAD-NeRF [32] under the self-driven setting, based on two frames extracted from each video illustrating typical challenges. Yellow boxes highlight areas of noisy image quality, while red boxes indicate regions with inaccurate lip synchronization.
Quality comparison: Examples of visualizations of RAD-NeRF [32] under the self-driven setting, based on two frames extracted from each video illustrating typical challenges. Yellow boxes highlight areas of noisy image quality, while red boxes indicate regions with inaccurate lip synchronization.

Quality comparison: Examples of visualizations of ER-NeRF [34] methods under the self-driven setting, based on two frames extracted from each video illustrating typical challenges. Yellow boxes highlight areas of noisy image quality, while red boxes indicate regions with inaccurate lip synchronization.
Quality comparison: Examples of visualizations of ER-NeRF [34] methods under the self-driven setting, based on two frames extracted from each video illustrating typical challenges. Yellow boxes highlight areas of noisy image quality, while red boxes indicate regions with inaccurate lip synchronization.

Table 1.
Quantitative comparison of face reconstruction quality under self-driven synthesis on the same identity’s test set. The arrows in the metric names indicate the preferred trend for each metric: ↑ denotes that higher values are better, ↓ signifies that lower values are preferable.
Table 1.
Quantitative comparison of face reconstruction quality under self-driven synthesis on the same identity’s test set. The arrows in the metric names indicate the preferred trend for each metric: ↑ denotes that higher values are better, ↓ signifies that lower values are preferable.
| Methods | AFE | Dataset | PSNR ↑ | SSIM ↑ | LPIPS ↓ | LMD ↓ | FID ↓ | AUE ↓ | Syncconf ↑ |
|---|---|---|---|---|---|---|---|---|---|
| RAD-NeRF [32] | Deep-Speech | Obama | 27.14 | 0.9304 | 0.0738 | 2.675 | 31.29 | 1.995 | 7.171 |
| Donya | 27.79 | 0.9045 | 0.0917 | 2.750 | 12.82 | 1.911 | 4.720 | ||
| Shaheen | 30.13 | 0.9314 | 0.0697 | 3.199 | 33.05 | 2.837 | 7.330 | ||
| Mean | 28.35 | 0.9221 | 0.0784 | 2.874 | 25.72 | 2.247 | 6.407 | ||
| HuBERT | Obama | 26.58 | 0.9261 | 0.0769 | 2.762 | 28.78 | 2.006 | 0.563 | |
| Donya | 28.05 | 0.9071 | 0.0868 | 2.518 | 14.25 | 2.511 | 0.365 | ||
| Shaheen | 30.45 | 0.9332 | 0.0729 | 3.050 | 35.96 | 3.229 | 0.494 | ||
| Mean | 28.36 | 0.9221 | 0.0788 | 2.776 | 26.33 | 2.582 | 0.474 | ||
| Wav2Vec | Obama | 26.59 | 0.9268 | 0.0785 | 2.696 | 15.15 | 1.707 | 6.744 | |
| Donya | 27.12 | 0.8972 | 0.0845 | 2.726 | 24.58 | 1.531 | 4.820 | ||
| Shaheen | 30.08 | 0.9306 | 0.0698 | 3.221 | 34.77 | 2.966 | 7.946 | ||
| Mean | 27.93 | 0.9182 | 0.0776 | 2.881 | 24.83 | 2.068 | 6.503 | ||
| Whisper | Obama | 26.10 | 0.9231 | 0.0723 | 2.573 | 12.67 | 1.693 | 7.143 | |
| Donya | 28.65 | 0.9138 | 0.0844 | 2.640 | 26.85 | 1.504 | 5.269 | ||
| Shaheen | 30.05 | 0.9303 | 0.0660 | 3.045 | 29.44 | 2.696 | 8.488 | ||
| Mean | 28.07 | 0.9224 | 0.0761 | 2.826 | 24.04 | 1.964 | 6.966 | ||
| ER-NeRF [34] | Deep-Speech | Obama | 26.44 | 0.9339 | 0.0441 | 2.561 | 7.14 | 1.923 | 7.201 |
| Donya | 28.91 | 0.9165 | 0.0605 | 2.647 | 14.59 | 1.874 | 4.722 | ||
| Shaheen | 29.92 | 0.9267 | 0.0450 | 2.900 | 16.10 | 2.668 | 8.215 | ||
| Mean | 28.16 | 0.9257 | 0.0689 | 2.7932 | 20.92 | 2.155 | 6.712 | ||
| HuBERT | Obama | 26.30 | 0.9297 | 0.0473 | 2.758 | 8.33 | 1.711 | 0.300 | |
| Donya | 24.20 | 0.7826 | 0.1255 | 2.545 | 49.81 | 2.284 | 0.408 | ||
| Shaheen | 30.45 | 0.9322 | 0.0420 | 2.852 | 16.56 | 3.172 | 0.434 | ||
| Mean | 26.98 | 0.8815 | 0.0716 | 2.718 | 24.90 | 2.389 | 0.380 | ||
| Wav2Vec | Obama | 25.59 | 0.9268 | 0.0497 | 2.645 | 8.83 | 1.704 | 6.616 | |
| Donya | 24.21 | 0.7777 | 0.1509 | 2.754 | 68.20 | 1.730 | 4.403 | ||
| Shaheen | 29.81 | 0.9245 | 0.0470 | 3.003 | 15.59 | 2.948 | 7.917 | ||
| Mean | 26.53 | 0.8763 | 0.0825 | 2.800 | 30.87 | 2.127 | 6.312 | ||
| Whisper | Obama | 26.30 | 0.9314 | 0.0462 | 2.501 | 8.06 | 1.797 | 7.647 | |
| Donya | 27.36 | 0.9020 | 0.0641 | 2.516 | 14.67 | 1.852 | 5.704 | ||
| Shaheen | 30.20 | 0.9305 | 0.0434 | 2.935 | 15.61 | 3.030 | 8.575 | ||
| Mean | 28.12 | 0.9213 | 0.0654 | 2.7640 | 19.29 | 2.226 | 7.308 |
Table 2.
Quantitative comparison of audio–lip synchronization under the cross-driven setting. The arrows in the metric names indicate the preferred trend for each metric: ↑ denotes that higher values are better, ↓ signifies that lower values are preferable.
Table 2.
Quantitative comparison of audio–lip synchronization under the cross-driven setting. The arrows in the metric names indicate the preferred trend for each metric: ↑ denotes that higher values are better, ↓ signifies that lower values are preferable.
| Methods | AFE | Dataset | Syncconf ↑ Synthetic | Syncconf ↑ Natural |
|---|---|---|---|---|
| RAD-NeRF [32] | Deep-Speech | Obama | 6.581 | 6.489 |
| Donya | 4.208 | 3.576 | ||
| Shaheen | 6.319 | 5.840 | ||
| Mean | 5.702 | 5.301 | ||
| HuBERT | Obama | 5.109 | 0.548 | |
| Donya | 4.750 | 0.680 | ||
| Shaheen | 6.670 | 0.741 | ||
| Mean | 5.509 | 0.656 | ||
| Wav2Vec | Obama | 6.851 | 7.388 | |
| Donya | 4.593 | 5.017 | ||
| Shaheen | 6.837 | 7.303 | ||
| Mean | 6.093 | 6.569 | ||
| Whisper | Obama | 6.884 | 7.137 | |
| Donya | 4.628 | 5.742 | ||
| Shaheen | 6.347 | 7.052 | ||
| Mean | 5.953 | 6.643 | ||
| ER-NeRF [34] | Deep-Speech | Obama | 7.306 | 7.224 |
| Donya | 5.054 | 4.851 | ||
| Shaheen | 6.505 | 6.074 | ||
| Mean | 6.323 | 6.050 | ||
| HuBERT | Obama | 5.542 | 0.614 | |
| Donya | 4.822 | 0.480 | ||
| Shaheen | 7.068 | 0.581 | ||
| Mean | 5.810 | 0.558 | ||
| Wav2Vec | Obama | 7.219 | 7.428 | |
| Donya | 4.115 | 4.155 | ||
| Shaheen | 7.145 | 7.242 | ||
| Mean | 6.159 | 6.275 | ||
| Whisper | Obama | 7.399 | 8.247 | |
| Donya | 4.651 | 6.486 | ||
| Shaheen | 6.148 | 7.093 | ||
| Mean | 6.066 | 7.275 |
Execution time analysis of each component in the system architecture as depicted in Figure 1. AA Tokens: number of tokens in the avatar’s answer. AA Duration (s): length of the avatar’s answer in seconds.
Execution time analysis of each component in the system architecture as depicted in Figure 1. AA Tokens: number of tokens in the avatar’s answer. AA Duration (s): length of the avatar’s answer in seconds.
| AA Tokens | AA Duration (s) | STT | Language | TTS | AFE | Frame Rendering | Audio Overlay | SUM | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.41 | Exe. Time (s) | 0.06 | 0.80 | 0.22 | 0.29 | 4.05 | 0.14 | 5.56 |
| % of Total | 1.08% | 14.39% | 3.96% | 5.22% | 72.84% | 2.52% | 100% | ||
| 8 | 1.69 | Exe. Time (s) | 0.07 | 0.96 | 0.33 | 0.28 | 4.75 | 0.16 | 6.55 |
| % of Total | 1.07% | 14.66% | 5.04% | 4.27% | 72.52% | 2.44% | 100% | ||
| 14 | 3.63 | Exe. Time (s) | 0.07 | 2.45 | 0.44 | 0.28 | 5.45 | 0.14 | 8.83 |
| % of Total | 0.79% | 27.74% | 4.98% | 3.17% | 61.71% | 1.59% | 100% | ||
| 21 | 5.08 | Exe. Time (s) | 0.1 | 2.27 | 0.44 | 0.28 | 5.88 | 0.17 | 9.14 |
| % of Total | 1.09% | 24.83% | 4.81% | 3.06% | 64.36% | 1.86% | 100% | ||
| 30 | 6.55 | Exe. Time (s) | 0.06 | 2.76 | 0.49 | 0.27 | 6.58 | 0.15 | 10.31 |
| % of Total | 0.58% | 26.77% | 4.75% | 2.62% | 63.84% | 1.45% | 100% | ||
| 39 | 9.55 | Exe. Time (s) | 0.09 | 1.95 | 0.78 | 0.28 | 7.52 | 0.18 | 10.8 |
| % of Total | 0.83% | 18.06% | 7.22% | 2.59% | 69.63% | 1.67% | 100% | ||
| 50 | 12.16 | Exe. Time (s) | 0.07 | 2.08 | 0.55 | 0.28 | 8.65 | 0.18 | 11.81 |
| % of Total | 0.59% | 17.61% | 4.66% | 2.37% | 73.24% | 1.52% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Source link
Pegah Salehi www.mdpi.com