
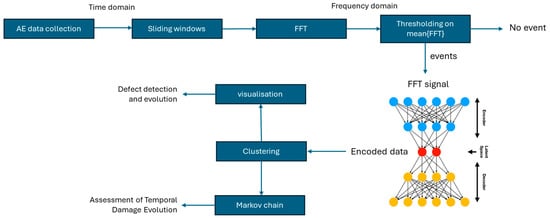
2. Materials and Methods
2.1. Experimental Setup
CFRP coupons manufactured using the resin infusion process were used in mechanical tensile and three-point flexural tests that were carried out as part of the Horizon 2020 Carbo4Power project. Collection of the AE data utilized for initial analysis and as input for model creation was completed through monitoring during the mechanical tests. Specific focus was placed upon CFRP, which have been employed for the reinforcing spar during WTB manufacturing. The reinforcing spar is the main load-bearing component of the WTB. The intended role of the material guided the selection of mechanical testing, ensuring that the applied loading conditions closely replicate those expected in real-world applications. From the AE data captured during tensile and flexural testing, it was possible to establish the relationship between AE response and associated damage mechanisms developing from the healthy condition of the material up to its final failure.
Tensile testing was performed using an electro-mechanical testing machine manufactured by Zwick Roell, model 1484, with a 200 kN load cell. The extensometer length was set to 10 mm, and the crosshead movement speed was set to 2 mm/min. Test coupons with dimensions 250 mm long by 25 mm wide were used for the tensile tests, with a thickness range of 1.03–1.33 mm. These had a laminated layered structure with fiber direction of [0/45/QRS/−45/90], where the QRS are Quantum Resistive Sensors in the shape of wires with a diameter comparable to that of the fibers. QRS were internally positioned, interlaminar sensors for direct measurement of strain, temperature, and humidity developed as part of the Carbo4Power project. End-tabs were used to allow for the proper application of the grip force during loading. Three-point bending testing was carried out using a Dartec Universal Mechanical Testing Machine, with a 50 kN load cell and a crosshead movement speed of 1 mm/min. Test coupons with dimensions 150 mm long by 25 mm wide and a thickness range of 1.15–1.32 mm. Again, these example coupons were of a layered laminated structure, with a layup of [0/QRS/45/−45/90]; due to the nature of the specific mechanical testing, no end tabs were required.
2.2. Data Collection
2.3. Signal Pre-Processing and FFT Transformation for Time-to-Frequency Domain Analysis
After applying the FFT to each windowed signal, the mean FFT is computed to create a representative frequency spectrum. Each transformation yields 100 frequency components, determined by the sampling rate and window length. To retain only the most relevant frequency components and suppress noise, a thresholding technique is used. The threshold for frequency-domain event selection was determined through an empirical sensitivity analysis using the statistical properties of the noise level in the dataset. The analysis considered the mean and standard deviation of the background noise, along with percentile-based thresholds, to establish a threshold that effectively filtered out insignificant fluctuations while preserving relevant AE events. The threshold selection was refined within the range [0.0050–0.0126], corresponding to the 99.9th to 99.99th percentiles of the signal. A grid search was performed within this range, starting from 0.0050 with a step size of 0.001, evaluating the separation between noise and meaningful AE events at each step. The selected threshold (0.01) ensures that only the most critical frequencies, those indicating potential damage, are passed on to the next phase of the analysis. Specifically, frequency components exceeding the 0.01 threshold in the mean FFT spectrum are retained, while lower-amplitude components are discarded. This reduces data dimensionality and ensures that only the most informative frequencies are passed to the autoencoder. By emphasizing significant signals and suppressing noise, the thresholding process enhances damage detection accuracy, making the subsequent analysis more robust and focused on critical frequency behaviors over time. As a result of this process, a total of 2,099,313 AE events were identified and selected for further analysis from the data collected across all 9 specimens, with each event represented by a time segment of 200 time samples and its corresponding frequency representation consisting of 100 frequency components.
2.4. Learning Compact Representations Through Deep Autoencoder Networks
The autoencoder architecture consists of two main components: the encoder and the decoder. The encoder is responsible for mapping the high-dimensional input data to a lower-dimensional latent space. During this process, the encoder learns to identify key features in the data that are essential for representing the underlying structure of the signals, effectively reducing the dimensionality of the input. The dimensionality of the latent space is determined through hyperparameter tuning, ensuring that it is compact enough to be efficient, yet large enough to retain critical information about the damage-related frequency components. Once the data have been compressed into the latent space, the decoder is tasked with reconstructing the original input data from this lower-dimensional representation. The decoder mirrors the encoder, gradually upscaling the compressed data back into its original high-dimensional form. The success of this reconstruction is measured by the reconstruction error, which quantifies the difference between the original input and the reconstructed output. The goal of training is to minimize this error, ensuring that the latent space captures the most informative features of the data with minimal loss of fidelity.
The training process involves iteratively adjusting the weights of the encoder and decoder through backpropagation. The autoencoder is trained using mean squared error (MSE) as the loss function, which measures the average squared differences between the input and reconstructed output. By minimizing MSE, the autoencoder learns to effectively encode the “thresholded” FFT data in a way that preserves its key characteristics while discarding irrelevant noise and redundant information. During the training process, Bayesian optimization was employed to fine-tune the hyperparameters of the autoencoder. This optimization process explored various configurations, including the size of the latent space, the regularization terms, and the number of training epochs, to find the optimal settings that resulted in the lowest reconstruction error. The use of L2 weight regularization and sparsity constraints ensured that the autoencoder did not overfit the training data, promoting a more generalized model that performs well on unseen data.
The autoencoder’s architecture is designed with several key hyperparameters that control its performance. These included the following: (i) L2 weight regularization to prevent overfitting by penalizing large weights; (ii) sparsity regularization to enforce a constraint that encourages the latent space to have a sparse representation, meaning that only a few neurons are activated for any given input; (iii) sparsity proportion, which controlled the degree of sparsity in the latent representation; (iv) encoding dimension, which determined the size of the latent space and, therefore, the degree of compression; and (v) maximum number of epochs, which defined the number of training iterations. The optimal values of these hyperparameters were identified using Bayesian optimization, which efficiently searched for the best combination of parameters by balancing exploration and exploitation of the hyperparameter space. This process minimized the reconstruction error and ensured that the autoencoder learned an optimal latent space representation of the normalized FFT data.
where n is the number of frequency components in each FFT vector. A low reconstruction error indicates that the autoencoder has effectively learned to compress and reconstruct the key features of the data. To ensure model generalization, we applied a Leave-One-Experiment-Out (LOEO) cross-validation approach, training on 8 out of 9 experiments while using the remaining one for testing, repeating this process 9 times. Since the duration of each experiment varies, the number of AE events in the training and testing sets was not fixed. However, on average, approximately 90% of the total 2,099,313 AE events were used for training, while the remaining 10% were allocated for testing in each cross-validation fold. This ensured that the model was trained on a diverse set of AE signals while being evaluated on previously unseen data, improving its generalization ability and robustness. In addition to the quantitative evaluation, qualitative assessment was also performed by visualizing the reconstructed signals alongside the original FFT data. This visual comparison helped to ensure that the shape of the FFT, which was critical for clustering, has been preserved during the dimensionality reduction process.
2.5. Clustering in the Latent Space
Once the autoencoder has performed the dimensionality reduction, the next important step was clustering the latent representations of the AE data. Clustering helped reveal hidden patterns in the latent space, which can correspond to different damage-related events. This section explained the clustering methodology, evaluated its performance, and provided a theoretical background along with result visualizations. The latent space generated by the autoencoder reduced the normalized FFT-transformed AE data into a lower-dimensional space that preserved the most critical features. Each point in the latent space corresponded to a windowed segment of the AE signal, representing the key signal characteristics captured by the autoencoder.
where is the distance to the nearest centroid already chosen. This initialization improved the likelihood of finding globally optimal clustering. After determining the optimal clusters, we were able to classify new AE signals. For a new set of encoded features , each data point was assigned to the closest cluster centroid from the original clustering.
where is the encoded feature for a new data point and is the centroid of the -th cluster from the original k-means model.
2.6. Visualization
where n is the number of frequency components. The points are then plotted against time , with different colors representing clusters. In addition to the latent space clusters, we plotted the accumulated mean frequency for each cluster over time. The following expression is the cumulative sum of the mean frequency content for signals within each cluster:
where is the set of signals in cluster
2.7. Temporal Damage Evolution Using Markov Chain Analysis
where is the number of transitions from cluster to and is the total number of transitions from cluster i to any other cluster, ensuring that the probabilities in each row of the matrix sum to 1.
This formulation allows us to calculate the relative likelihood of transitioning between clusters, effectively capturing the progression from one damage state to another, as well as the likelihood of remaining in the same state (self-transitions). The higher the value of , the more likely it is that an AE signal moves from state i to state j, while low values indicate rare transitions or relatively stable states. The transition matrix is visualized as a state transition diagram. The state transition diagram is a graphical representation of the clusters and the transitions between them. Each node in the diagram represents a cluster, while the arrows between nodes indicate the direction and magnitude of transitions between states. The thickness of each arrow is proportional to the transition probability between clusters, with thicker arrows indicating more frequent transitions. Self-transitions are also represented by loops at each node, indicating the probability that a signal remains in the same cluster (damage state) over time. This diagram provides a clear view of the overall flow between different damage stages, allowing for an easy interpretation of how the system evolves.
The Markov chain analysis offers valuable insights into the temporal progression of damage in CFRP structures. By examining the transition probabilities, we can make several important observations:
Clusters with high self-transition probabilities (i.e., large values of ) are considered stable states. These clusters represent damage stages that persist for longer periods before transitioning to another state. For instance, if the probability of staying within Cluster 1 is high, it suggests that this stage of damage is more prolonged or stable.
The transition probabilities between clusters reveal how damage evolves over time. For example, a high probability of transitioning from Cluster 1 to Cluster 2 would indicate that damage is progressing from an early-stage or less severe state (Cluster 1) to a more advanced or severe stage (Cluster 2). These transitions are critical for understanding how damage accumulates and the speed at which it progresses.
The Markov chain also allows for the analysis of reversibility in damage progression. If there is a significant probability of transitioning back from Cluster 2 to Cluster 1, this could suggest that certain damage processes may stabilize or revert under certain conditions, such as cyclical loads. This could be indicative of periods where the structure is subjected to temporary stress without permanent damage progression.
By modeling the system as a Markov chain, we can use the transition probabilities to forecast future states of the system. For instance, if there is a high probability of transitioning from a stable damage state to a more critical one, maintenance activities can be scheduled pre-emptively, reducing the risk of unexpected failures.
2.8. Assignment of Frequency Ranges for Damage Mechanisms
For the assessment of damage using the frequency components contained within a given AE event signal, it is important that the identified peaks and features can be properly attributed to their respective sources and hence, related damage mechanisms. The relationship between energy and frequency is well established, with observed damage mechanisms within an FRP also generating signals with distinctive energy content, which is dependent on the relative interfacial strength. When assessing damage mechanisms, attempting to characterize them using a specific frequency value can result in significant inaccuracies, particularly since the propagation of the wave with increasing distance from the source will result in signal attenuation but also frequency dispersion. Hence, assigning ranges to the associated frequencies from observations of the transformed spectra can contribute to the correct identification of the damage mechanism affecting a particular FRP component during damage initiation and subsequent evolution. Accurately assigning the frequency ranges associated with different damage mechanisms will allow the effective damage mechanism identification and monitoring of damage initiation and evolution in FRP components.
The extraction of peak frequency allows for the assessment of the primary contributing phase within the captured waveform. Hence, information on the dominant damage mode for a given identified AE event can be obtained. Knowing the usual damage progression within the tensile loading of the test coupons also assists in the assignment of damage modes to the bands, which can be seen to be present. Based on the damage mechanisms in FRPs, five distinct bands are expected to arise, one for each of the primary damage mechanisms.
3. Results
This section presents the results of our analysis of AE signals using frequency-domain transformations, autoencoder-based representation learning, and clustering techniques. Additionally, we present the outcomes of applying Markov chain analysis to model the temporal evolution of damage, offering insights into the progression of damage states over time.
3.1. Damage Detection
Subplot (c) demonstrates how the transition to the frequency domain allows the detection of subtle but significant events that may be difficult to isolate in the time domain. In this case, the presence of dominant frequencies points to specific damage signatures, which are not as clearly discernible in the raw time-domain signals due to normal oscillations ranging between −0.005 and 0.005, making it challenging to distinguish damage-related events from background noise. This sensitivity to specific frequency components allows for much earlier and more precise detection of defects compared to time-domain-only analysis. The subplot (d), which represents a period without any detected AE event, shows how the frequency domain remains insightful even in quieter scenarios. While the time-domain signal still shows a minor fluctuation (with a peak value lower than −0.005), the frequency-domain plot reveals no significant peaks, indicating that no meaningful AE events are present. This clear distinction helps reduce false positives, as the frequency-domain analysis can filter out inconsequential noise and focus on genuine event signatures.
The transition from the time domain to the frequency domain significantly enhances the detection sensitivity for damage events. In this case, the use of mean FFT analysis reveals amplitude differences across various windows, providing a clearer view of the frequency components contributing to defect events. Traditional time-domain analysis may not be able to detect these subtle changes, but frequency-domain methods allow the identification of small amplitude deviations that could be indicative of evolving damage. The chosen threshold of 0.01 acts as a critical marker to highlight significant anomalies or events. In the presented experiment, most of the data points remain below the threshold, indicating normal or less significant frequency variations. However, there are distinct peaks that surpass the threshold, signaling potential damage events. This method not only detects events but also reduces the chance of false positives by focusing on those exceeding the defined amplitude difference threshold.
3.2. Representation Learning Results
The Sparsity Regularization (0.26843) and Sparsity Proportion (0.27307) parameters further control the sparsity of the encoded representations. These values suggest that the model is encouraged to learn compact representations by activating fewer neurons in the latent space, thus making the encoded data more concise and focused on the essential features. The encoding dimension of 76 specifies the size of the latent space, determining the number of features retained after compression. This dimensionality is sufficient for the model to effectively represent the high-dimensional input data while still significantly reducing its size. The training process was allowed to run for 293 epochs, which indicates that the model was given ample time to converge to an optimal solution, allowing it to iteratively improve its performance. The performance of the autoencoder is assessed through two key metrics. The global MSE is quite low at 0.0017259, suggesting that the model performs well in reconstructing the input data, with minimal deviation between the original and reconstructed data. This low reconstruction error demonstrates that the model is successfully capturing the key patterns in the data. Similarly, the global R-squared (R2) value of 0.94774 shows that the model explains a very high proportion (about 94.77%) of the variance in the input data. This high R2 value is a strong indicator of the autoencoder’s ability to retain the most important information while compressing the data into a lower-dimensional space.
3.3. Clustering Results and Visualization
3.4. Damage Evolution Assessment
The transition probabilities between the two clusters are also highly informative. The probability of transitioning from Cluster 1 to Cluster 2 is 0.2, indicating a moderate likelihood that the system will move from Cluster 1 to Cluster 2 over time. This transition could signify a shift from an early-stage damage mode (associated with Cluster 1) to a more advanced or severe state (represented by Cluster 2). On the other hand, the probability of returning from Cluster 2 to Cluster 1 is 0.46, which suggests that even after entering a more advanced damage state, there is still a significant likelihood of reverting to an earlier stage of damage, possibly due to cyclical load conditions or fluctuations in the severity of the damage. The Markov chain representation in this figure is particularly valuable for predictive maintenance and damage progression tracking in SHM systems. By understanding the transition dynamics between different damage states, operators can forecast the likelihood of progression from one damage mode to another. For instance, a high self-transition probability for Cluster 1 suggests that the system will likely remain in a less severe state for extended periods, providing more time for monitoring before significant damage occurs. However, the moderate likelihood of transitioning to Cluster 2 indicates that operators should remain vigilant for potential shifts toward more critical damage.
4. Discussion
The methodology presented in this work introduces a novel approach to SHM by integrating frequency-domain analysis with deep learning techniques. By transforming AE signals from the time domain to the frequency domain using FFT, critical frequency components related to various damage types are revealed, enabling more accurate identification and tracking of damage evolution over time. The application of deep autoencoders for dimensionality reduction ensures that the high-dimensional data are effectively compressed while preserving essential information, facilitating the use of clustering techniques to categorize different damage states. This combination of FFT, autoencoder-based representation learning, and Markov chain analysis for temporal damage progression offers significant advancements over traditional SHM systems, allowing for early detection, precise damage classification, and predictive maintenance strategies that extend the lifespan of critical components.
The frequency-domain approach is well-suited for scenarios where subtle or gradual damage is expected to evolve over time. By monitoring the evolution of different damage-related frequency components, this method can provide real-time feedback on the health of structures or materials, such as wind turbine blades, as mentioned in prior tasks. This proactive monitoring ensures that damage is detected early, potentially preventing catastrophic failures. From the experimental results, we observe that there are multiple points where the amplitude difference spikes above the threshold, particularly around indices close to 4 × 104. These spikes indicate the occurrence of significant events that are likely to represent damage or anomalies detected by the system. The clustering of such events in certain regions suggests periods of heightened activity or damage evolution, which could be investigated further to understand the underlying causes. This figure demonstrates the efficacy of using AI-based tools to automate the detection of damage events by applying frequency-domain transformations and thresholding techniques. The ability to track these events with a predefined threshold ensures that the detection process is not only more sensitive but also more precise, allowing for earlier and more accurate damage identification compared to state-of-the-art commercial systems.
These results highlight the autoencoder’s effectiveness in learning compressed representations while maintaining a low level of information loss. The low MSE (0.0017259) and high R2 values (0.94774) confirm that the model is capable of both reducing dimensionality and preserving the critical characteristics of the data for accurate reconstruction. The selected hyperparameters, particularly those controlling sparsity, ensure that the latent space is used efficiently, capturing meaningful variations in the data and avoiding overfitting. This balance between model capacity and regularization is essential in ensuring the generalizability of the model across different datasets. In practice, these results suggest that the autoencoder can be highly effective in real-world applications such as defect detection or system health monitoring, where dimensionality reduction and signal reconstruction are key. The model’s ability to compress high-dimensional data while minimizing reconstruction error makes it a valuable tool for scenarios where efficient processing of large datasets is required. Additionally, the sparsity and encoding dimension allow the model to distill important features from noisy or redundant data, ensuring robust performance across a range of use cases. Building on these findings, future work will explore alternative architectures such as CAEs and VAEs to further assess trade-offs in reconstruction accuracy, interpretability, and generalization, particularly in capturing spatial and probabilistic variations in AE signals.
Clustering was performed using K-means++ initialization to ensure a more stable and well-spread selection of initial cluster centroids, reducing the risk of poor local minima and enhancing clustering consistency. The Euclidean distance metric was used to compute cluster assignments, as it is computationally efficient and commonly applied in unsupervised learning tasks. However, we acknowledge that alternative distance metrics, such as cosine similarity or Mahalanobis distance, could yield different cluster formations, particularly in high-dimensional latent spaces. Future work will explore the influence of different distance metrics on cluster separation and damage characterization.
The implications of the clustering analysis for SHM systems are profound, especially in advancing the field of predictive maintenance. By leveraging the frequency-domain clustering technique, SHM systems can move beyond simple damage detection to offer a deeper understanding of how damage evolves over time, thus enhancing decision-making and maintenance planning. Firstly, this analysis allows for multi-stage damage tracking, where the system is capable of distinguishing between different levels of structural degradation. By categorizing damage into clusters, SHM systems can not only detect damage but also assess its severity. This opens up the possibility of prioritizing maintenance tasks based on the urgency of the damage progression. For example, signals belonging to a cluster associated with early-stage damage could prompt periodic monitoring, while signals from more severe damage clusters would trigger immediate intervention.
While the methodology was validated in a controlled lab environment, its applicability to in situ SHM requires consideration of real-world factors such as environmental noise and boundary condition variations. The selection of FFT-based analysis aims to mitigate these influences by focusing on robust frequency-domain features, which can generalize across different structural scales. Additionally, the unsupervised feature extraction approach enables adaptability to complex, large-scale components where predefined damage classifications may not be available. To bridge the gap between laboratory and field applications, future work should explore the implementation of this methodology in real-world scenarios, incorporating additional testing on full-scale structures under operational conditions. This would allow for assessing the robustness of the approach in detecting and tracking damage evolution in situ, further validating its effectiveness for SHM applications.
In practical terms, this analysis can be incorporated into predictive models to enhance maintenance scheduling. By continuously monitoring the system’s state transitions, SHM systems can forecast future states, providing early warnings of potential damage progression and enabling more proactive, condition-based maintenance strategies. Moreover, the ability to return from Cluster 2 to Cluster 1 could offer opportunities to temporarily stabilize the system, preventing further deterioration before repairs are necessary. In conclusion, the state transition diagram provides a useful approximation of damage evolution, offering insights into how damage states transition over time. However, the memoryless assumption of the Markov model means that it does not fully capture the long-term dependencies or cumulative effects that influence structural degradation. While this approach helps in detecting trends and estimating transition probabilities, it should be viewed as a proxy rather than a complete representation of damage progression dynamics. Higher-order Markov models or machine learning-based sequence models could be potentially incorporated to better account for the history of damage evolution. Despite these limitations, the results demonstrate the potential of using Markov chains as a practical and interpretable tool for predictive maintenance and optimizing intervention strategies.
Finally, this approach contributes to the optimization of resource allocation. With a clearer understanding of the different stages of damage and their progression, maintenance efforts can be better focused, avoiding unnecessary interventions on healthy or lightly damaged parts. This not only reduces operational costs but also extends the lifespan of critical components, thereby improving overall system reliability. Overall, the clustering analysis provides a robust framework for advancing SHM systems from reactive to predictive and condition-based maintenance strategies. It enables early detection, tracks damage progression, correlates damage with specific causes, and informs strategic planning, all of which significantly improve the efficiency and effectiveness of structural monitoring.
Source link
Serafeim Moustakidis www.mdpi.com
