
1. Introduction
A brilliant, comfortable, personalized driving experience is the future direction of intelligent cockpit development. Multimodal human–computer interaction technology is one of the core driving forces for developing intelligent cockpits. This study explores the application of multimodal human–computer interaction in future intelligent cockpits. In a gaze+EEG multimodal interaction, the gaze provides a clear visual focus, and the EEG reflects the cognitive state of the manipulator. This interaction method can understand the user’s intention more comprehensively and improve the accuracy of the interaction. However, in current practical applications, we must address issues such as integrating eye tracking with brain–computer interface devices, system latency, and user adaptability. Nonetheless, the multimodal human–computer interaction technology of gaze+EEG still has a lot of potential for development and application in the future because it can enhance the level of cockpit intelligence and user experience.
2. Related Work
2.1. Gaze+Speech Combination
Multimodal interaction based on gaze and speech is superior to unimodal interaction. However, it still has many disadvantages. For example, when using voice to interact, speech control systems often need to infer the meaning expressed by users based on the context due to the inherent ambiguity of human language. In situations where semantic contexts are uncertain, the error accuracy is high. Interference may also occur in voice input among multiple users. And the privacy of voice input cannot be guaranteed.
2.2. Gaze+Posture Combination
Add gestures or head poses as input commands to the computer in the gaze interaction, and it becomes a multimodal human–computer interaction. Related studies are as follows.
When using hand gestures or head posture confirmation interaction, users have to keep their hands or heads in the detection area space all the time. In addition, the user is easily fatigued by making hand gestures and head movements for a long time.
2.3. Gaze+EEG Combination
One key goal in the research of aviation human–computer interaction systems is to improve the efficiency of human–computer interaction in aircraft cockpit intelligent assistive interaction systems. Gaze+EEG multimodal interaction can reduce the operator’s hand operation and speed up the HCI. The interaction target’s size and motion state dramatically impact the accuracy of existing gaze+EEG multimodal interaction techniques. This paper uses a deep learning network to extract features from eye movement and EEG data to improve the performance of the multimodal human–computer interaction to solve this problem.
3. Methods
3.1. Multimodal Interaction Processes for Target Selection
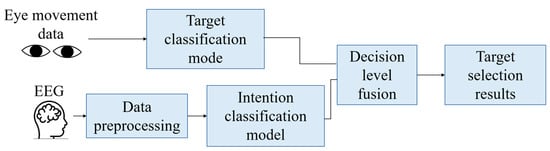
The purpose of multimodal interaction modeling is to complete the interaction task of target selection between the operator and the simulated interaction interface. The designed interaction interface is the screen of the radar system in the aircraft. The display screen shows multiple targets, and the operator “locks” the object with their gaze and then “confirms” the currently locked target with EEG.
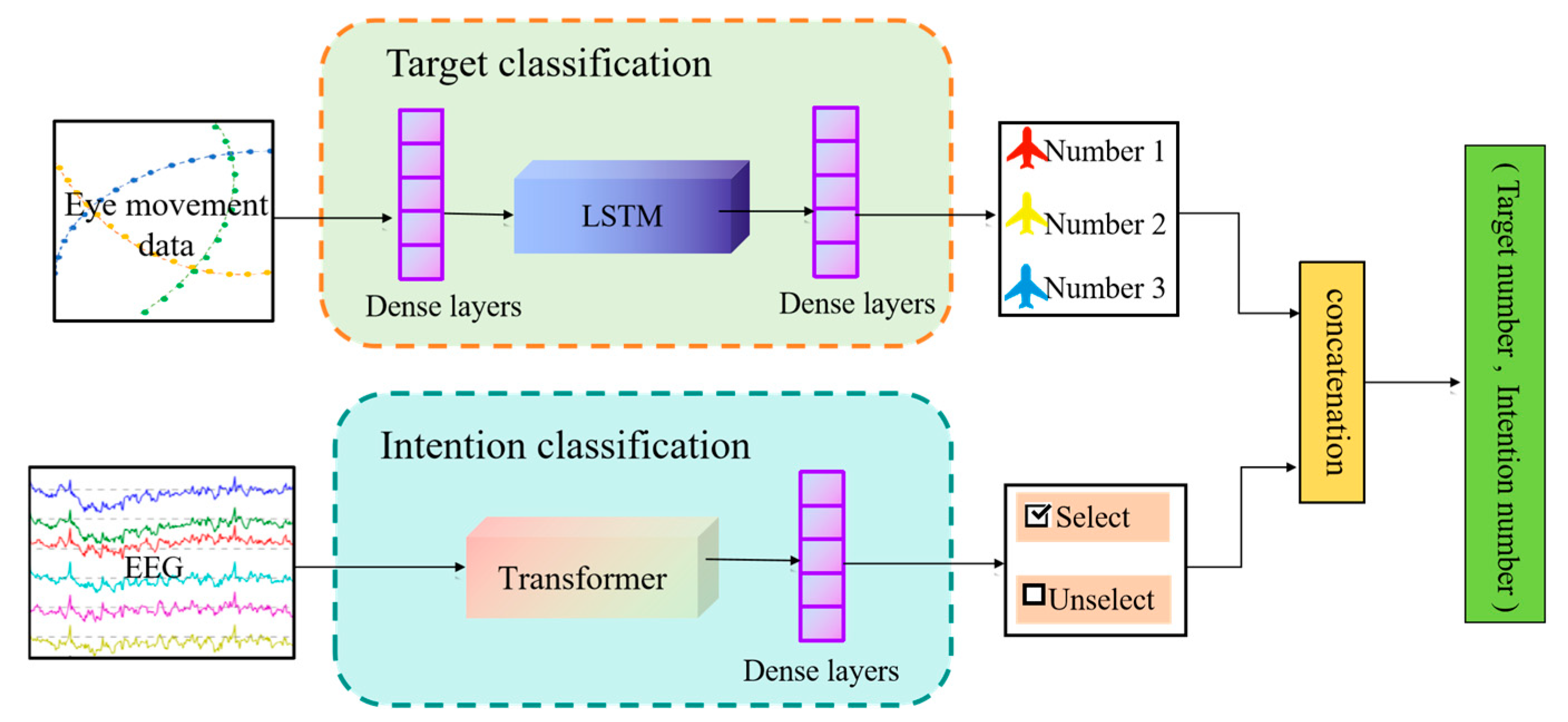
3.2. Multi-Modal Interaction Model Based on LSTM and Transformer
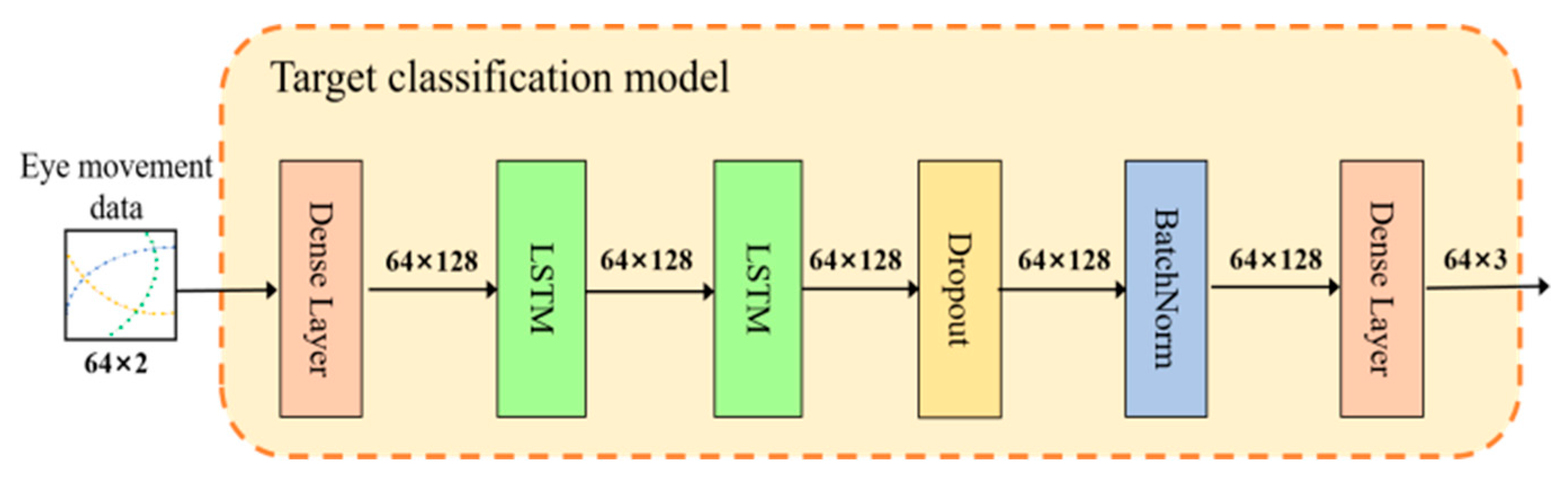
3.3. Target Classification Model
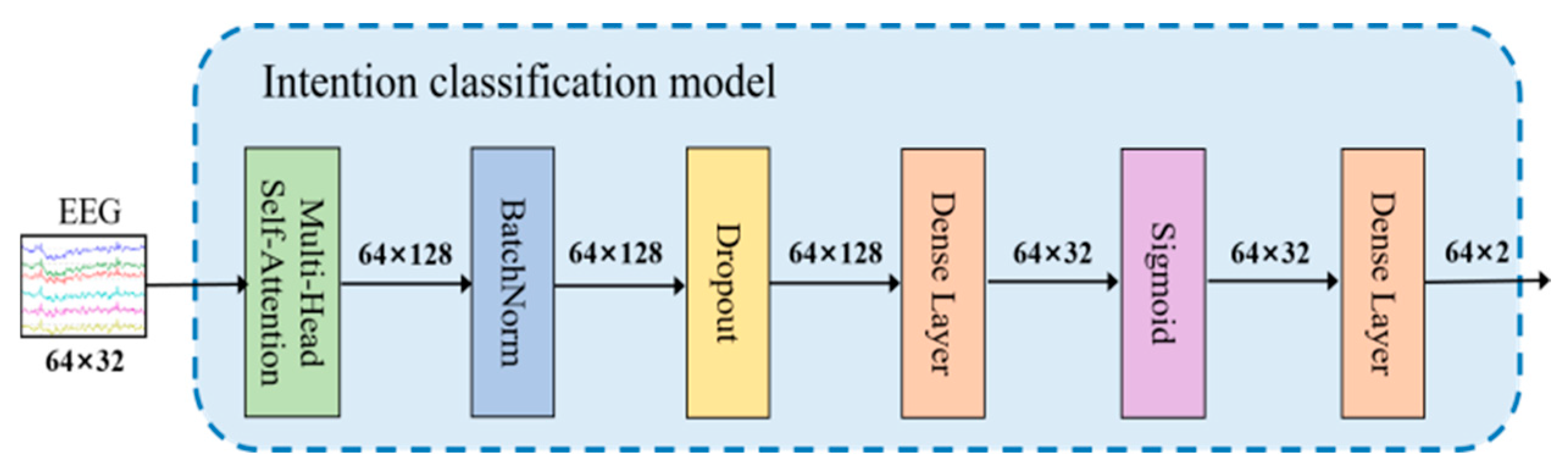
3.4. Intention Classification Model
4. Experimental Design and Analysis of Results
4.1. Experimental Design
4.1.1. Experimental Objects
To collect eye movement data and EEG for the experiment, we recruited 10 males aged 21 to 25. All subjects had normal vision and no history of psychiatric disorders. Before the experiment, each subject was informed of the details of the experimental procedure and signed an informed consent form. We have established strict confidentiality measures to ensure the privacy and data security of the subjects. In addition, our institution’s ethics committee has reviewed and approved this study.
4.1.2. Experimental Devices
We collected EEG data using an ErgoLAB EEG measurement system acquired by the team. The system was configured with an EEG cap using a 10-10 international standard lead system layout of electrodes. The conduction medium for each electrode was a wet sponge. The EEG instrument was capable of recording 32-lead EEG data. The sampling frequency of the EEG signals was 256 Hz.
4.1.3. Experimental Process
Prolonged experiments may cause subjects to lose concentration, leading to poor experimental results. Therefore, after performing 200 sets of experiments, each subject had to be replaced by the next subject.
4.1.4. Data Preprocessing
4.2. Analysis of Results
4.2.1. Model Training Parameters
where denotes the real probability of the sample and represents the predicted probability of the sample. The training should try to make the values of and infinitely close to each other.
The sample dataset is grouped for training using 5-fold cross-validation. The process of 5-fold cross-validation is as follows. First, the sample dataset is divided randomly into five equal-sized subsets. Any one of the subsets is the testing set for testing the model performance, and the remaining four subsets are the training set for model training. We then repeat the above method of dividing the dataset five times. The training and testing sets are different each time. Finally, we average the validation results from all testing sets. This average value represents the final performance of the model.
4.2.2. Results and Analysis of Target Classification
To evaluate the proposed multimodal human–computer interaction model’s performance comprehensively, we first assess the performance of the target and intention classification modules separately. We then group all eye movement data samples for training using 5-fold cross-validation. We randomly divide the 14,400 sets of eye movement data into five equal-sized subsets at a time.
denotes the number of samples whose classification results are identical to the class labels. denotes the number of samples whose classification results differ from the class labels.
4.2.3. Results and Analysis of Intention Classification
We also train the 14,400 sets of EEG data samples in groups using 5-fold cross-validation. The model needs to be cross-validated five times. For each cross-validation, the sample size of the training set is 11,520, and the sample size of the testing set is 2880. The final classification accuracy of the intention classification model in this paper is the average of the classification accuracies obtained from 5-fold cross-validations.
4.2.4. Results and Analysis of Multimodal Interaction
is the interaction accuracy. denotes the number of samples for which the target and intention classification predictions are the same as the class labels. denotes the number of samples for which the class labels are the same as the predictions for target classification and different from the projections for intention classification. denotes the number of samples where the class labels differ from the predictions of the target classification and are the same as the predictions of the intention classification. denotes the number of samples for which the predictions of both the target and intention classifications differ from the class labels.
4.2.5. Results and Analysis of Flight Simulation Validation
5. Discussion
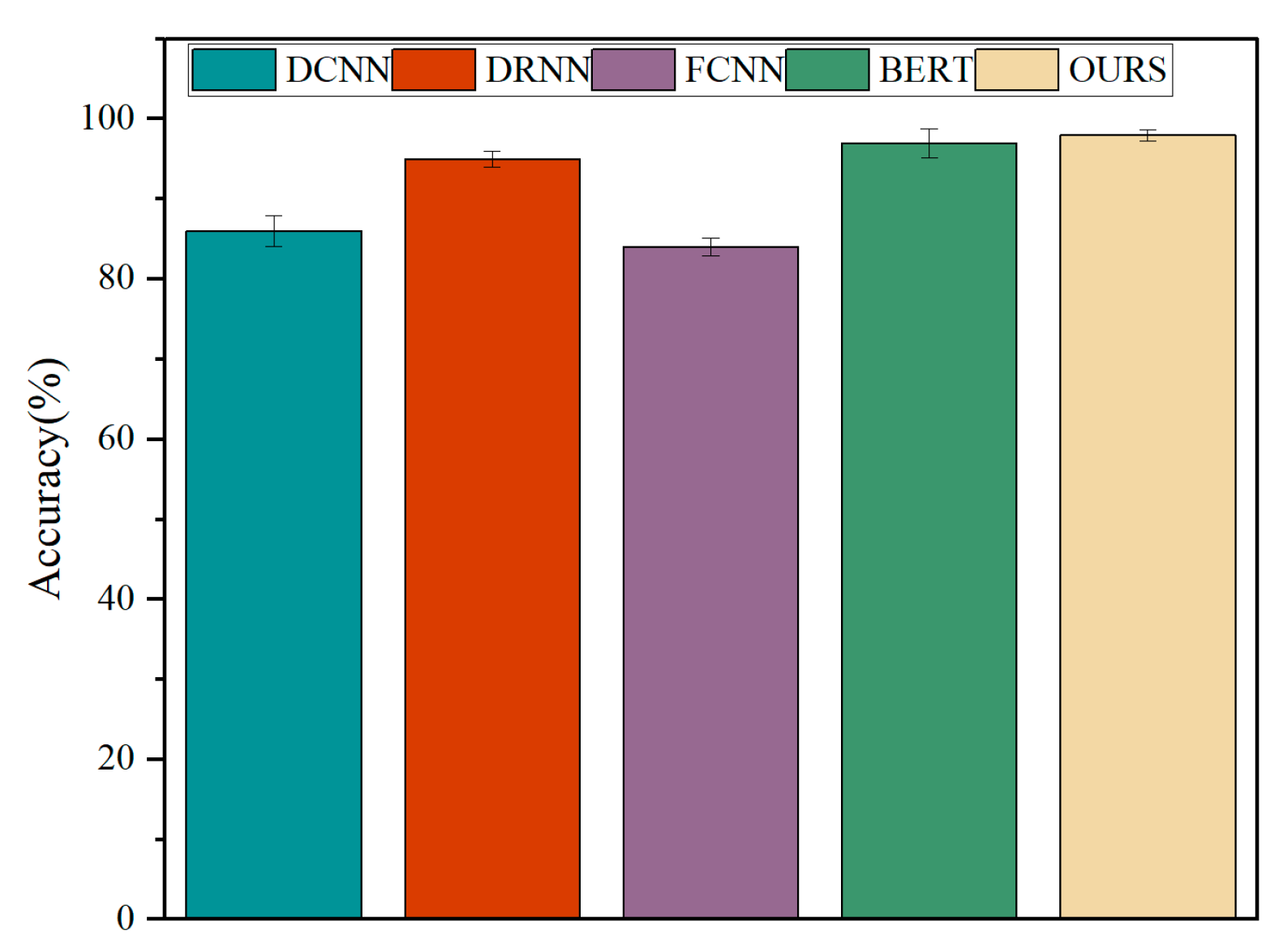
The model we designed achieves the expected results in the human–computer interaction task with the selected target. In the designed multimodal interaction model, the target classification module utilizes the LSTM network framework, and the intention classification module uses a modified transformer framework. To evaluate the performance of the LSTM and transformer in the model, we compare them with multiple models. The comparison results prove the robustness of our model. In addition, the test results on the simulated flight platform also show that our designed multimodal human–computer interaction model based on gaze and EEG can improve the accuracy of the interaction.
The model in this paper focuses on the situation when the motion trajectories of the interacting targets are different. In other words, target classification works best when the motion trajectories of the interacting targets are quite different. However, the motion trajectories of the airplane targets on the actual radar page may be very similar. In this case, the classification performance of the proposed model will deteriorate. In particular, when the airplane targets all move along the identical flight path, the target classification network in this paper is difficult to distinguish by eye movement trajectories. In addition, it is necessary to expand the scale and variety of the dataset used by the model further. The model in this paper is still in the exploratory stage for practical applications and cannot directly apply to real cockpits. Because it still has many challenges, such as the system’s integration technology’s complexity, the system’s response time, and the adaptation of user personalization.
6. Conclusions
The research in this paper aims to improve the efficiency and accuracy of the human–computer interaction in aircraft cockpit scenarios as well as the naturalness of the interaction behavior. In this study, we propose a multimodal interaction model based on deep learning networks to implement target selection for radar interfaces. The model points to the task object by gaze and then determines by EEG whether or not to select the pointed task object. The comparison results with other models and the validation results of the simulated flight platform prove the advantages of the proposed model’s performance. Our study can provide a reference value for the design of intelligent aircraft cockpits. In future studies, we will expand the subject population by increasing the number of subjects, adding female subjects, and other measures. Large and diverse datasets can raise the model’s generalization ability. We will continue to optimize the network model to improve accuracy, considering that the trajectories of interacting targets may be very similar. In addition, future research should consider actual cockpit testing, adding other modalities, and user experience.
Author Contributions
Methodology, L.W.; writing—original draft, L.W.; writing—review and editing, L.W.; data analysis, H.Z.; funding acquisition, C.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the National Natural Science Foundation of China (Number: 52072293).
Institutional Review Board Statement
The study was conducted in accordance with the Declaration of Helsinki, and the protocol was approved by the Ethics Committee of Xi’an Technological University (10702) on July 2022.
Informed Consent Statement
Informed consent for participation and publication were obtained from all subjects involved in the study.
Data Availability Statement
The datasets presented in this article are not readily available because the data are part of an ongoing study. Requests to access the datasets should be directed to authors.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Plopski, A.; Hirzle, T.; Norouzi, N.; Qian, L.; Bruder, G.; Langlotz, T. The eye in extended reality: A survey on gaze interaction and eye tracking in head-worn extended reality. ACM Comput. Surv. 2023, 55, 53. [Google Scholar] [CrossRef]
- Land, M.F.; Tatler, B.W. Looking and Acting: Vision and Eye Movements in Natural Behaviour. In Looking and Acting: Vision and Eye Movements in Natural Behaviour; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Dondi, P.; Porta, M.; Donvito, A.; Volpe, G. A gaze-based interactive system to explore artwork imagery. J. Multimodal User Interfaces 2022, 16, 55–67. [Google Scholar] [CrossRef]
- Niu, Y.; Li, X.; Yang, W.; Xue, C.; Peng, N.; Jin, T. Smooth Pursuit Study on An Eye-Control System for Continuous Variable Adjustment Tasks. Int. J. Hum. Comput. Interact. 2021, 1, 23–33. [Google Scholar] [CrossRef]
- Card, S.K.; Moran, T.P.; Newell, A. The Psychology of Human-Computer Interaction; University of Michigan: Ann Arbor, MI, USA, 2008. [Google Scholar]
- Mahanama, B.; Ashok, V.; Jayarathna, S. Multi-eyes: A framework for multi-user eye-tracking using webcams. In Proceedings of the 2024 IEEE International Conference on Information Reuse and Integration for Data Science (IRI), San Jose, CA, USA, 7–9 August 2024; pp. 308–313. [Google Scholar]
- Franslin, N.M.F.; Ng, G.W. Vision-based dynamic hand gesture recognition techniques and applications: A review. In Proceedings of the 8th International Conference on Computational Science and Technology, Labuan, Malaysia, 28–29 August 2021; Lecture Notes in Electrical Engineering. Springer: Singapore, 2022; Volume 835, pp. 125–138. [Google Scholar]
- Jacob, R.J.K. What you look at is what you get: Eye movement-based interaction techniques. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seattle, WA, USA, 1–5 April 1990; pp. 11–18. [Google Scholar]
- Castellina, E.; Corno, F.; Pellegrino, P. Integrated speech and gaze control for realistic desktop environments. In Proceedings of the 2008 Symposium on Eye Tracking Research & Applications, Savannah, GA, USA, 26–28 March 2008; pp. 79–82. [Google Scholar]
- Carrino, S.; Péclat, A.; Mugellini, E.; Khaled, O.A.; Lngold, R. Humans and smart environments: A novel multimodal interaction approach. In Proceedings of the 13th International Conference on Multimodal Interfaces, Alicante, Spain, 14–18 November 2011; pp. 105–112. [Google Scholar]
- Sengupta, K.; Ke, M.; Menges, R.; Kumar, C.; Staab, S. Hands-free web browsing: Enriching the user experience with gaze and voice modality. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–3. [Google Scholar]
- Rozado, D.; McNeill, A.; Mazur, D. Voxvisio—Combining Gaze and Speech for Accessible Hci. In Proceedings of the RESNA/NCART, Arlington, VA, USA, 10–14 July 2016. [Google Scholar]
- Chatterjee, I.; Xiao, R.; Harrison, C. Gaze+ gesture: Expressive, precise and targeted free-space interactions. In Proceedings of the 2015 ACM on International Conference on Multimodal Interaction, Seattle, WA, USA, 9–13 November 2015; pp. 131–138. [Google Scholar]
- Pfeuffer, K.; Mayer, B.; Mardanbegi, D.; Gellersen, H. Gaze+ pinch interaction in virtual reality. In Proceedings of the 5th Symposium on Spatial User Interaction, Brighton, UK, 16–17 October 2017; pp. 99–108. [Google Scholar]
- Feng, W.; Zou, J.; Kurauchi, A.; Morimoto, C.; Betke, M. Hgaze typing: Head-gesture assisted gaze typing. In Proceedings of the ACM Symposium on Eye Tracking Research and Applications, Online, 25–27 May 2021; pp. 1–11. [Google Scholar]
- Jalaliniya, S.; Mardanbegi, D.; Pederson, T. MAGIC pointing for eyewear computers. In Proceedings of the 2015 ACM International Symposium on Wearable Computers, Osaka, Japan, 7–11 September 2015; pp. 155–158. [Google Scholar]
- Wang, B.; Wang, J.; Wang, X.; Chen, L.; Zhang, H.; Jiao, C.; Wang, G.; Feng, K. An Identification Method for Road Hypnosis Based on Human EEG Data. Sensors 2024, 24, 4392. [Google Scholar] [CrossRef] [PubMed]
- Huang, C.; Xiao, Y.; Xu, G. Predicting human intention-behavior through EEG signal analysis using multi-scale CNN]. IEEE/ACM Trans. Comput. Biol. Bioinform. 2020, 18, 1722–1729. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, Z.; Zou, Z.; Zhang, A.; Tian, R.; Gao, S. Semi-autonomous g-rasping system based on eye movement and EEG to assist the interaction between the disabled and environment. TechRxiv 2021. [Google Scholar] [CrossRef]
- Yi, Z.; Pan, J.; Chen, Z.; Lu, D.; Cai, H.; Li, J.; Xie, Q. A hybrid BCI integrating EEG and Eye-Tracking for assisting clinical communication in patients with disorders of consciousness. IEEE Trans. Neural Syst. Rehabil. 2024, 32, 2759–2771. [Google Scholar] [CrossRef] [PubMed]
- Huang, R.; Wei, C.; Wang, B.; Yang, J.; Xu, X.; Wu, S.; Huang, S. Well performance prediction based on Long Short-Term Memory (LSTM) neural network. J. Pet. Sci. Eng. 2022, 208, 109686. [Google Scholar] [CrossRef]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. AI Open 2022, 3, 111–132. [Google Scholar] [CrossRef]
- Ye, Z.; Li, H. Based on Radial Basis Kernel function of Support Vector Machines for speaker recognition. In Proceedings of the 5th International Congress on Image and Signal Processing, Chongqing, China, 16–18 October 2012; pp. 1584–1587. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, K.; Robinson, N.; Lee, S.W.; Guan, C. Adaptive transfer learning for EEG motor imagery classification with deep convolutional neural network. Neural Netw. 2021, 136, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Yang, H.; Li, J.; Chen, D.; Du, M. EEG-based intention recognition with deep recurrent-convolution neural network: Performance and channel selection by Grad-CAM. Neurocomputing 2020, 415, 225–233. [Google Scholar] [CrossRef]
- Roots, K.; Muhammad, Y.; Muhammad, N. Fusion convolutional neural network for cross-subject EEG motor imagery classification. Computers 2020, 72, 72. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 4171–4186. [Google Scholar]
Multimodal interaction process.
Figure 1.
Multimodal interaction process.
Multimodal interaction mode.
Figure 2.
Multimodal interaction mode.
The specific structure of the target classification model.
Figure 3.
The specific structure of the target classification model.
The intention classification model’s specific structure.
Figure 4.
The intention classification model’s specific structure.
The measurement flow of the eye tracker.
Figure 5.
The measurement flow of the eye tracker.

Experimental environment.
Figure 6.
Experimental environment.

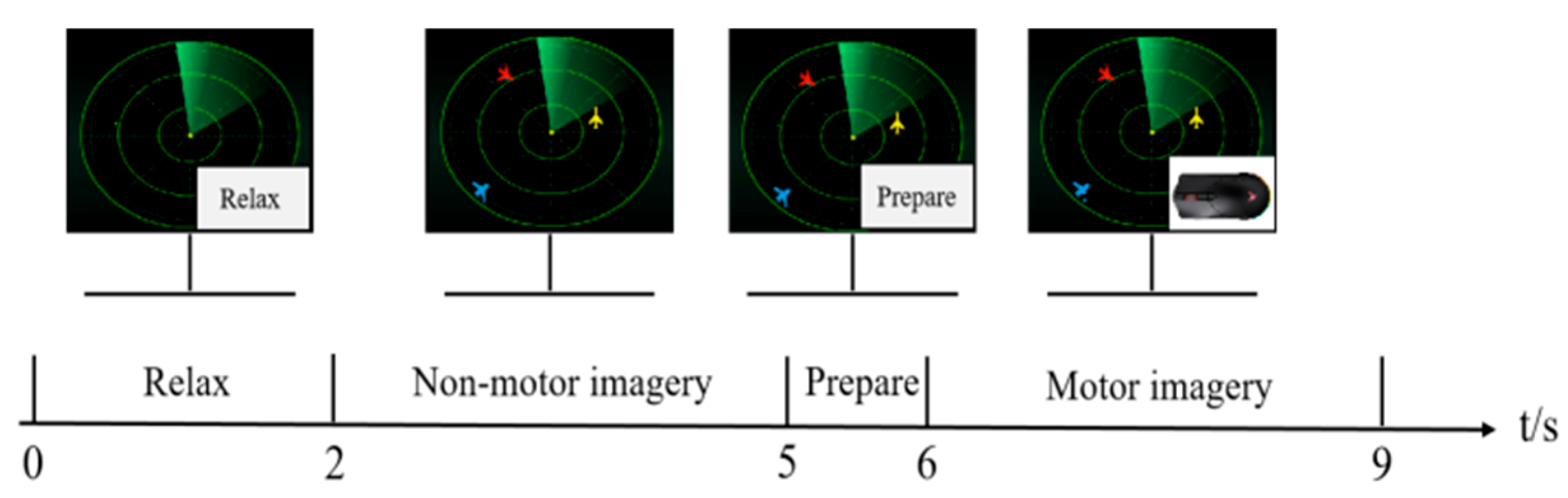
Timing diagram of the experimental flow.
Figure 7.
Timing diagram of the experimental flow.
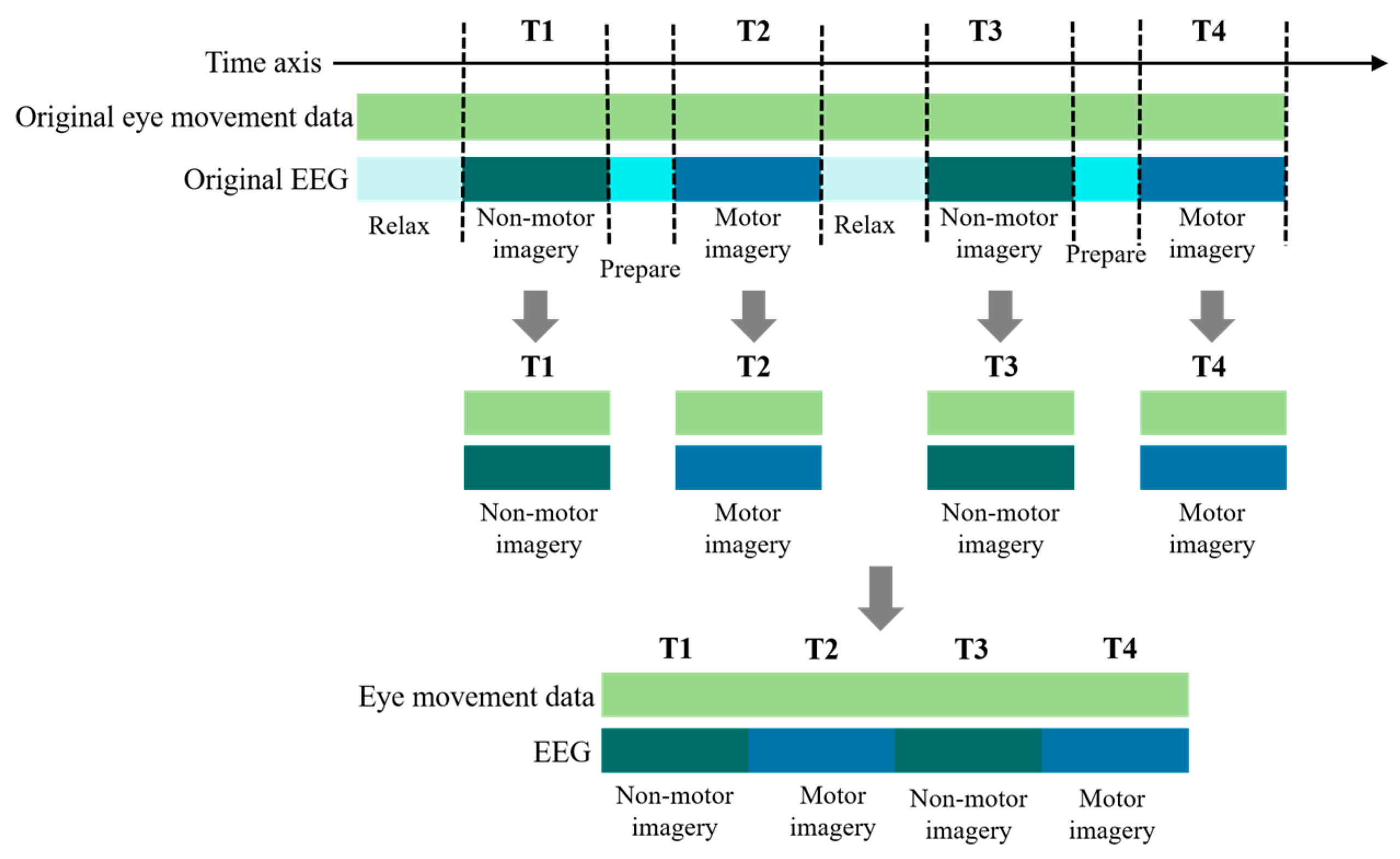
An example of data slicing.
Figure 8.
An example of data slicing.
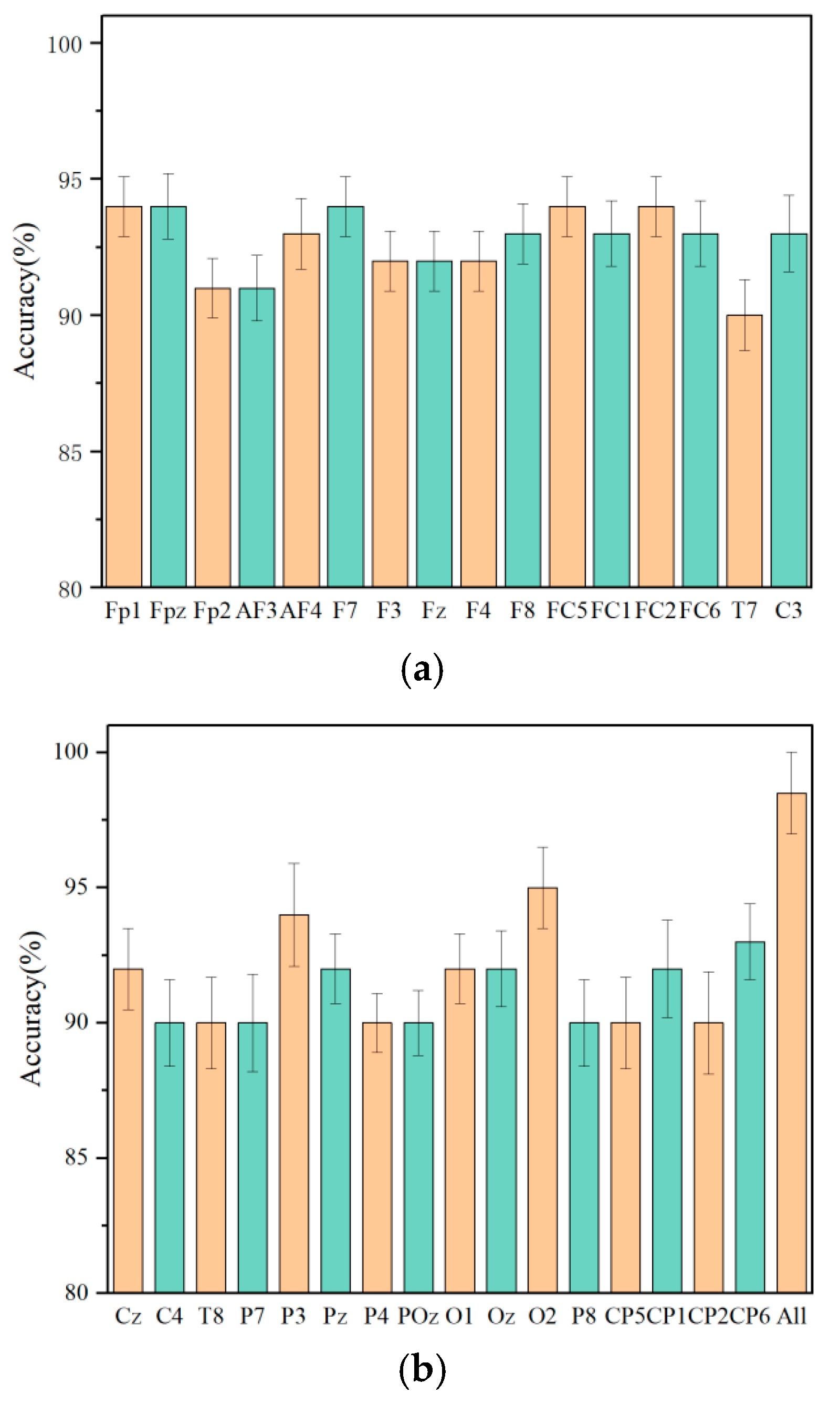
(a). Accuracy comparison of Fp1-C3 channel. (b). Accuracy comparison of Cz-All channel.
Figure 9.
(a). Accuracy comparison of Fp1-C3 channel. (b). Accuracy comparison of Cz-All channel.
Accuracy comparison of different models.
Figure 10.
Accuracy comparison of different models.
Test experiment process.
Figure 11.
Test experiment process.

Interaction verification results.
Figure 12.
Interaction verification results.
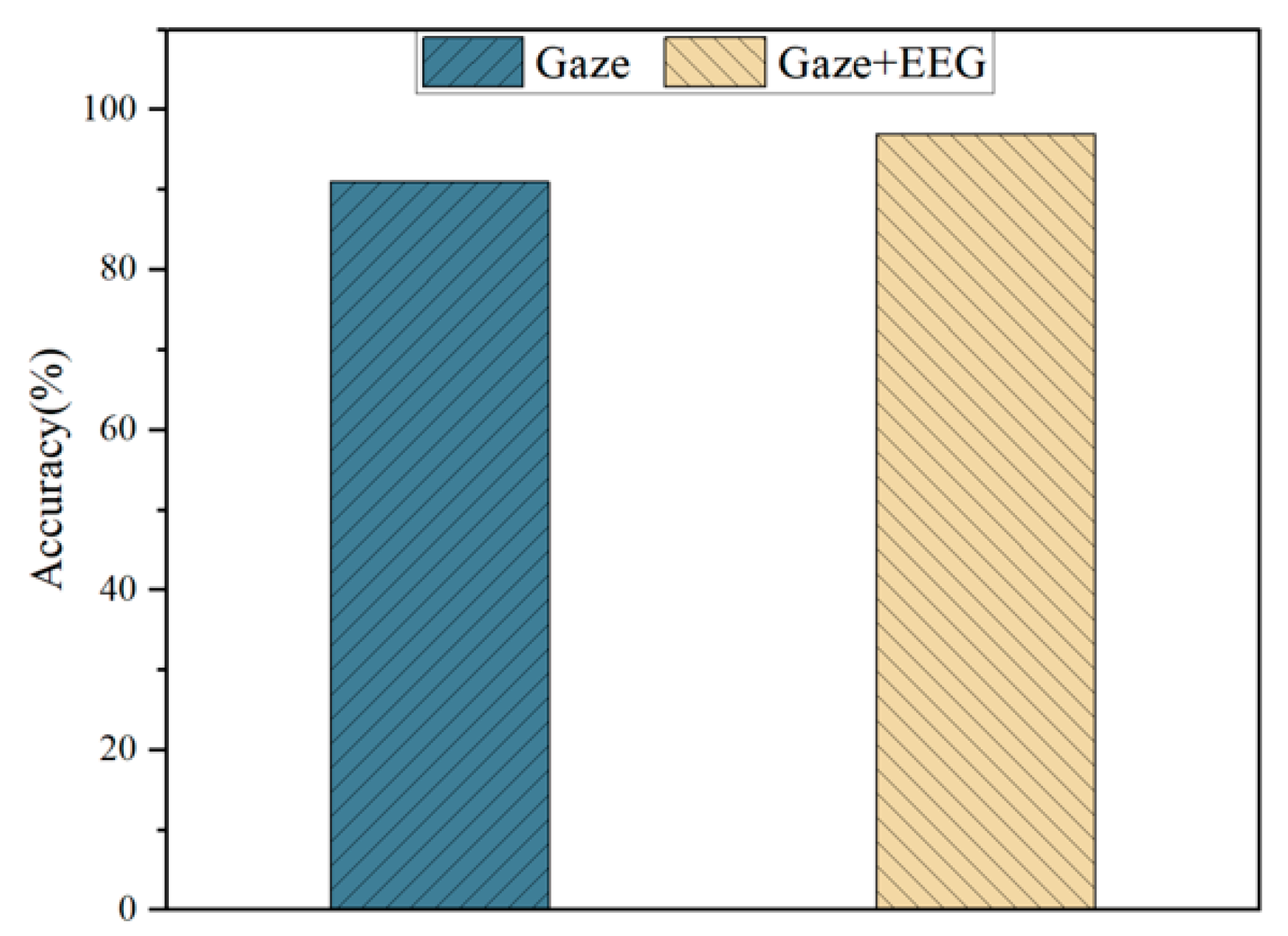
Table 1.
Comparison of results of target classification.
Table 1.
Comparison of results of target classification.
| Classifier | Parameters | Accuracy |
|---|---|---|
| SVM [23] | Kernel Type: RBF | 70.2% |
| AlexNet [24] | num_convolution: 5 Batch size: 64 The initial learning rate: 10−3 Loss function: cross-entropy | 78% |
| GoogLeNet [25] | num_layers: 22 Batch size: 64 The initial learning rate: 10−3 Loss function: cross-entropy | 83.6% |
| RESNET [26] | Convolution kernel size: 3 × 3 Stride: 2 Padding: 1 Batch size: 64 The initial learning rate: 10−3 | 88.4% |
| OURS | num_lstm_layers: 2 Dropout rate: 0.5 Batch size: 64 The initial learning rate: 10−3 Loss function: cross-entropy | 98% |
Table 2.
The results of 5-fold cross-validation of the multimodal interaction model.
Table 2.
The results of 5-fold cross-validation of the multimodal interaction model.
| N | Acc |
|---|---|
| 1 | 97.2% |
| 2 | 96.8% |
| 3 | 97% |
| 4 | 97.9% |
| 5 | 97.4% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Source link
Li Wang www.mdpi.com

