
1. Introduction and Background
One of the main problems is the reliance on traditional, static methods that rely on past experience and expert judgement, which have shown limitations, especially in adapting to changes and managing unforeseen emergencies.
Integrating legacy systems with new digital tools is another critical challenge. Many rail networks still rely on outdated systems that are not compatible with modern digital technologies. Upgrading these systems requires significant investment and technical expertise, which can be a considerable hurdle for many organizations.
Management of the sheer volume of data generated by IoT devices. These data require robust management capabilities to be useful for strategic and operational decision-making. In addition, the interoperability of maintenance management systems is crucial for effectively implementing digital technologies across the rail network. Achieving this interoperability can be complex.
Cybersecurity has become a critical concern due to increased connectivity and dependence on digital systems. Protecting these systems against cyber threats is essential to ensure security and operational continuity.
Finally, effective implementation of digital technologies remains a challenge, especially in networks with older or less digitized infrastructure. This implementation requires technological, organizational, and training changes to ensure staff adapt to new technologies.
Digitalization and criticality analysis together offer innovative solutions to address challenges in railway asset management, sensors embedded in the infrastructure enable the automated collection and processing of real-time data on asset conditions, such as track wear and tear and train conditions. In addition, digital twins, continuously updated with these data, allow operational scenarios to be simulated and potential failures to be foreseen before they occur.
On the one hand, digitalization
- –
- Enables the integration of advanced technologies such as IoT, Big Data, and digital twins, facilitating the collection and processing of real-time data on the condition of railway assets. This not only improves the accuracy of asset condition assessment but also enables a faster and more efficient response to changing conditions and unforeseen emergencies [2].
- –
- Facilitates interoperability and system integration through the use of advanced data models, such as the asset administration shell (AAS), which enables the representation of the digital characteristics of a physical asset. This enables advanced and efficient management throughout the asset lifecycle, overcoming the limitations of legacy systems [3].
On the other hand, criticality analysis
- –
Is a methodology that identifies and prioritizes system components whose failure would negatively impact operations. When combined with digitalization, this analysis becomes more dynamic and accurate, allowing the continuous and on-demand assessment of the railway assets. This technique optimizes resource allocation by focusing on the most critical assets, thus improving safety and operational efficiency.
In other words, digitalization and criticality analysis address technical and operational challenges and promote a proactive and predictive approach to railway asset management. This approach contributes to increased rail infrastructure reliability and safety, marking a significant advance in asset management in the digital age.
With the above in mind, the paper develops an approach to railway asset management through digitalization and criticality analysis. To this end, a data model is proposed where through a structured extract, transform, and load (ETL) process and the development of a criticality evaluation algorithm according to this data model, enabling an automated and accurate assessment of the risk associated with railway assets.
Location of the asset (on a journey or at a station): This attribute tells you whether the asset is in a train station or along a journey between stations. Location can influence the frequency of failures due to wear and tear and the consequences of failures, as a failure at a station could have a different impact than a failure at a track.
Network type (high-speed, conventional, suburban): Depending on the network, assets may be subject to different voltage levels, speeds, and usage, affecting the likelihood of failure and its consequences. For example, a high-speed network can have more severe consequences if it fails.
Traffic speed: Assets located on sections where trains run at higher speeds may be subjected to more significant mechanical stress, increasing failure frequency. In addition, if a failure occurs, the consequences could be more severe due to the high speed.
Asset location: Assets in curves or tunnels may have more adverse conditions affecting their durability. In a curve, trains can generate greater friction, and in a tunnel, ventilation and humidity conditions can be different, affecting both the frequency of failures and the consequences of those failures (e.g., longer or more difficult-to-repair service interruptions).
Impact on failure frequency: Each attribute can increase or decrease the likelihood of the asset failing. For example, a curve or tunnel asset might fail more often than one in a straight, open section due to more demanding operating conditions.
Impact on the consequences of failures: In addition to frequency, these attributes affect the consequences when the asset fails. A failure in a tunnel can be more challenging to repair and have more severe consequences than one in an open area. Similarly, a failure in a high-speed network could cause more severe delays than in a suburban network.
2. Literature Review
- Crespo Márquez [3] proposes a model incorporating digitalization as a crucial enabling factor, facilitating extensive assessments in organizations managing millions of assets.
- The Asset Management Working Group [4], corresponding to the International Union of Railways (UIC) guidance, suggests a model capable of managing risk throughout the asset lifecycle, integrating operations and maintenance management. This approach implies a high degree of complexity in handling multiple data sources, which makes the implementation of advanced technologies such as digital twins essential.
- The use of artificial intelligence (AI) in railway maintenance has shown substantial advantages, especially in identifying and predicting defects using techniques such as computer vision and machine learning [18]. For example, automated visual track inspection allows rail geometry defects and component wear to be detected with significantly higher accuracy than traditional manual inspections. In addition, deep learning algorithms can detect objects on roads and segment signals in complex environments, improving safety and reducing the risk of accidents. However, the deployment of AI in this sector faces critical challenges. One of the biggest challenges is the lack of specific standards and regulations that ensure the safety and reliability of AI-based systems. In addition, AI integration requires a large amount of high-quality data, the availability and accuracy of which can vary considerably between railway systems. Despite these challenges [19], AI has the potential to transform railway maintenance management, enabling real-time scenario simulation and predictive alert generation that improve operational efficiency and safety.
- Several studies, shown in Table 3, have laid the groundwork for implementing digital technologies in rail asset management, demonstrating their potential to improve the safety, efficiency, and sustainability of rail operations. The current literature on the digitalization and management of railway assets has identified several gaps that limit the full exploitation of digital technologies in this sector.
- ○
Heterogeneous Data Integration: One of the main challenges is integrating extensive volumes of data from various sources, such as sensors and monitoring devices. Consistency in analyzing these data remains a complex task due to railway systems’ dynamic and varied nature.
- ○
Scalability and Flexibility: Another critical gap is ensuring that digital solutions are scalable and flexible to adapt to different railway environments. While promising models have been proposed, such as digital twins, more studies are needed to explore their scalability in various operational contexts.
- ○
Interoperability and Standardization: A significant obstacle is a lack of standardization and interoperability between different technologies and systems. Both aspects hinder the effective integration of new technologies with legacy systems, which is crucial for efficient asset lifecycle management.
- ○
Application of Advanced Data Models: Although progress has been made in collecting and analyzing large volumes of data, few studies have succeeded in integrating these data into operational models that facilitate dynamic criticality assessment and real-time predictions.
- ○
Cybersecurity and Data Management: Secure data management and protection against cyber threats are growing concerns as more aspects of railway maintenance are digitized. Addressing these challenges is essential to maximize the potential of digitalization.
Table 3.
Literature Gaps and Challenges.
Table 3.
Literature Gaps and Challenges.
| Gap Identified | Detail | References |
|---|---|---|
| Holistic Integration | Need to combine various digital tools into a unified framework. | [20,21] |
| Use of Real-Time Data | Development of methodologies for using real-time data in dynamic criticality analysis. | [17,22] |
| Standardization and Interoperability | Development of common standards and protocols for the seamless integration of digital technologies. | [20] |
| Human and Organizational Factors | Addressing the cultural and structural changes necessary for digital transformation. | [23,24] |
| Cybersecurity and Data Privacy | Ensuring the security and integrity of data in digital systems. | [25] |
| Cost Benefit Analysis | Conducting comprehensive cost-benefit analyses of digitalization. | [3] |
| Scalability and Flexibility | Development of scalable and flexible digital solutions to adapt to different contexts. | [14] |
3. Methodology
3.1. Methodological Development
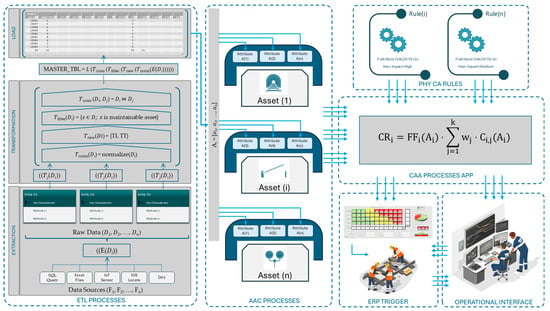
- Description of the ETL process and AAS framework: The data model focuses on the process of extracting information from various sources, transforming it to ensure consistency and compatibility, and loading it into a master database that centralizes the data for analysis. This process begins with identifying and collecting operational and performance data from heterogeneous sources. The data are then normalized using relationship tables to create a subset that assigns values to variables for each asset based on asset type, operational context, and the required level of intervention. This approach is reinforced by the principles of the asset administration shell (AAS), which propose a standardized digital representation of the asset. This digital representation acts as a multi-layered structure containing information such as status, service condition, maintenance history, and any other relevant data that aid in developing a dynamic criticality analysis. As an example, Figure 2 represents the structure developed in our use case, where graphically it is possible to appreciate how the multiple attributes are fed for each asset from different sources “Operational Entities” through specific relationships. In the same way, from other sources of operational information (MTC), it is possible to establish, by inference from type of asset and reference system, data on the frequency of failures and operational affectation such as delayed trains or unavailability of the system.
Asset attribute characterization (AAC) and its implementation: Asset attribute characterization (AAC) is applied to clearly define the critical attributes that influence the criticality of assets. This process includes defining and analyzing variables containing attributes such as failure frequency, unavailability, and other performance indicators that directly affect the operability of railway systems. These attributes characterize the assets, elaborated from the operation (online or on-demand) or history data and integrated into the criticality analysis.
Procedures for criticality assessment and creation of digital assets: The procedures established for criticality assessment use algorithms that analyze asset attributes to calculate their potential impact based on predefined criteria. This assessment is visualized in a criticality matrix that segments assets according to risk levels and allows a clear visualization of intervention priorities. Model-specific business rules are executed from the master database values to automatically determine each asset’s criticality value. In the previous step, the developer must create the digital asset by replicating the physical and operational attributes of the assets in a standardized digital format.
Integration with enterprise asset management (EAM) systems: Integrating criticality scores and risk alerts into the EAM system initiates specific maintenance activities if significant changes in risk occur. For example, measuring the wear of a rail section transmitted by the monitoring train updates the EAM system, allowing the maintenance manager to determine that the section needs to be inspected and repaired promptly, thus avoiding significant problems in train operation.
- Data Visualization and Modeling: The visualization is used to facilitate understanding of the process and decision-making, following diagrams such as Figure 2, which illustrates the data flow from extraction to criticality assessment. In addition, machine learning algorithms are envisaged to model and predict asset behavior, improving failure anticipation and maintenance strategy.
Continuous improvement: Finally, it is suggested that the master data set be enhanced with additional attributes, such as real-time health status measurement, and that advanced analysis techniques be employed to further optimize railway asset management. This methodology not only proposes an effective operational model but also sets a precedent for future improvements in digitalization and criticality analysis.
3.2. ETL Process for Rail Asset Assessment
3.2.1. Definition of Key Variables in the ETL Process
This section outlines the essential variables involved in the ETL process, including raw data, the transformations applied to it, and the final load into a centralized database. These variables form the basis of the data model that supports criticality assessment for railway assets
Raw Data (D):
- –
(D) represents raw data extracted from various sources, such as Excel files, SQL databases, inventory systems, and real-time IoT sensors.
- –
This data is organized in several tables (D1, D2…, Dn) where each table contains asset-specific information (e.g., it could contain inventory information, failure history, inventory data, asset information, etc.); (D1) could contain inventory information, (D2) failure history, etc.
Transformations (T):
- –
Transformations are the operations we apply to raw data to clean, normalize, and structure them into a valid format. These transformations can include the following:
- –
Normalization of heterogeneous data.
- –
- Calculation of additional attributes (such as failure frequency or network categorization), further detailed in Section 4, where we discuss their role in determining both the failure frequency and failure consequences.
- –
Filtering of non-relevant records.
- –
The data can be enriched by cross-referencing different sources.
- –
Each transformation can be modeled as a function applied to the raw data:
((Tj(Di)) is a transformation applied on the data table (Di)
where the transformed table is loaded into the final structure.
3.2.2. Extraction, Transformation, and Load Process Phases (ETL)
This section details the individual phases of the ETL process, including data extraction from multiple sources, transformations to normalize and enrich the data, and the final loading of this transformed data into a master table for use in criticality analysis.
Rail asset data are extracted from a variety of sources (F1, F2, …, Fn), which may include the following:
- –
SQL inventory databases (F1),
- –
Excel files with maintenance information (F2),
- –
IoT sensors (F3),
- –
GIS systems to locate assets (F4).
- –
Extraction is formalized as an operation: E(Di) = Di para i = 1,2, …, n
- –
Here, (E(Di)) represents the raw data extracted from the source (i), which will then be transformed.
The transformations are divided into several sub-processes:
- –
Attribute Normalization: Normalize the raw data so all assets have a standard attribute format, (Di), so that all assets have a common attribute format. For example, if an attribute such as failure frequency is in different units or formats, it is transformed by a normalization function:
Tnorm(Di) = normalize (Di)
- –
Calculation of New Attributes: In many cases, the system must create new attributes that are not present in the raw data. An example is calculating the unavailability time (IT) and the number of circulations per hour (TT). These new attributes can be modeled mathematically as
Here, the function (Tnew) applies calculations on (Di) to derive new attributes.
- –
Data Filtering: Irrelevant or redundant data are removed during filtering. For example, non-maintainable assets are filtered out if only information on maintainable assets is required. This task can be modeled as
Tfilter(Di) = {x ∈ Di: x is maintainable asset}
- –
Data Crossing: The ETL process also involves crossing different tables to generate a complete database. This cross can be formalized as
Tcross (Di, Dj) = Di ⋈ Dj
where (⋈) represents a join between the tables (Di) and (Dj) based on common keys (such as the asset identifier).
Load (L):
- –
- Finally, the transformed and normalized data are loaded into a master table MASTER_TBL, which is the final result of the ETL process. This is expressed as
- –
The master table will contain all the calculated and transformed attributes, ready to be used in the criticality assessment. Each row in MASTER_TBL represents an asset, and each column represents one of the key attributes (failure frequency, impact, downtime, etc.).
3.2.3. Formalization of the Complete ETL Process
MASTER_TBL = L (Tcross (Tfilter (Tnew (Tnorm(E(Di))))))
where
- –
(E(Di)) extracts the raw data from the source (i);
- –
(Tnorm), (Tnew), (Tfilter), y (Tcross) represent the normalization transformations, creation of new attributes, filtering of irrelevant data, and data crossover, respectively;
- –
(L) is the final load operation in MASTER_TBL.
Applicability to Other Companies: This ETL process is easily adaptable to other railway undertakings. This process can be reused on any railway infrastructure by changing the specific data sources and adjusting the necessary transformations according to the type of assets and network characteristics. In addition, the ETL process can evolve as new data sources (such as advanced IoT sensors or predictive maintenance systems) are added, making it flexible and scalable.
3.2.4. ETL Example Table (Explanation of Table Elements)
This table gives a clear visual reference of how the data are processed and structured, illustrating each step of the ETL process
Original Data Type: The type of data as they are initially obtained from their source, for example, asset inventory, maintenance records, real-time sensor data, etc.
Data Source: The specific source of each data type, such as SQL databases, Excel files, IoT devices, or GIS systems.
Transformation Applied: The transformation applied to the original data to structure it for the final data model (normalization, filtering, metric conversion, etc.).
3.3. Generalized Mathematical Model for Criticality Assessment
3.3.1. Definition of Variables
Failure Frequency (FF): (FFi) is the frequency with which an asset (i) fails in a given period of time (e.g., failures per year). This frequency can be derived from historical maintenance data or predictions based on the type of asset and its operating environment.
Consequences of Failure (C): (Ci) is the impact that the failure of an asset would have on different (i) in different dimensions. It can be modeled as a vector of consequences:
Ci = [Csafety, Cenvironment, Cservice, Ccosts])
where each component reflects the consequence on a specific dimension (safety, environment, quality of service, operational cost overruns).
- 3.
Asset Criticality (CR): (CRi) is the total criticality of an asset (i), which combines the frequency of failure with the consequences of those failures. The result is the key value that will be used to prioritize the most critical assets in maintenance.
- 4.
Operational Characteristics of the Asset (A): (Ai = [a1, a2,…, an]) is a set of attributes describing the asset (i) such as its location (path or station), type of network, traffic speed, whether it is in a curve or tunnel, etc. These attributes affect both the frequency of failure and the consequences of failure.
3.3.2. General Criticality Formula
where
- –
is the failure frequency of the asset (i) depending on operational characteristics ,
- –
is the value of the consequence of the failure in the dimension (j) depending on operational characteristics (e.g., safety, environment, etc.),
- –
(wj) is a weight assigned to each dimension (j) to reflect its relative importance in the criticality analysis,
- –
(k) is the number of dimensions considered (in this case, 4: safety, environment, service, costs).
3.3.3. Frequency and Consequence Models
- –
Failure Frequency (FF): The frequency of failures (FFi) can be modeled using historical data or predictions based on asset attributes, such as operating time, number of runs, or track type. A standard model for failure frequency function based on asset characteristics is as follows:
FFi = α + β1α1 + β2α2 + ⋯ + βnαn
where (α) is a base constant, and (β) are coefficients that adjust the impact of each characteristic on the failure frequency (an). (The choice of a linear regression model for predicting failure frequency (FF) was made due to its simplicity and interpretability, especially when the relationship between variables is approximately linear and the data are sufficient. We also acknowledged that alternative models, including machine learning approaches such as decision trees and non-linear regression, are being explored by our research team for future studies. However, these models typically require larger datasets and greater computational resources, which are beyond this study’s scope)
- –
Consequences (C): Each consequence can be modeled (Ci,j) using historical failure impact data or by simulations of potential failures. A standardized scale of consequences (e.g., from 1 to 10) can be used for each dimension. The weighted sum of the consequences in the different dimensions gives the total impact of an asset failure; these consequences can also be simplified into qualitative equivalents such as high, medium, low, and unacceptable.
3.3.4. Generalization Considerations
- –
Adaptation of Weights: The model is easily adaptable to different railway companies by adjusting the weights (wj) according to the company’s priorities. A company that values service quality more highly may assign a higher weighting to (wservice), while one that is more concerned about the environment might give a higher weight to (wenvironment). The assignment of weights and consequences is typically carried out through an expert consensus methodology, in which relevant company areas determine which dimension has the greatest impact on their business. It is worth noting that this distribution may vary in the medium term; however, in the short term, it remains stable, as is common in any risk analysis.
- –
Integration of Digital Technologies: The implementation of this model can be realized in a maintenance management system (EAM), where digital twins of each asset would allow for real-time monitoring of the values of (FFi) and (Ci) values, recalculating criticality continuously to adapt to changing operational conditions. In the absence of integrated systems, the data on asset operating characteristics must be extracted from a data model that consistently relates the operational context to the specific asset. These relationships may not be direct, so it will be necessary to use relationship tables to interpret the source data about the asset. Each of these sub-models can then be attached to each asset to make the information available on demand for future queries.
- –
- In this study, the developed criticality model does not consider failure interdependence, that is, the cascading effect that a failure in one component can have on others. Although a factorial analysis of failure interdependence would be valuable, it is considered beyond the scope of this work due to the added complexity and specific data requirements on asset dependency. However, the analysis based on the loss of functionality of the higher-level maintainable asset, UFS (unit functional of system, as per Rodriguez et al. [26]), partially compensates for this interdependence, as it is reflected in practice through the functional loss of the UFS, even if not explicitly modeled. In the applied case study, one of the considerations in the ETL process includes an inherited failure model, in which failures of secondary components are transferred to primary components when these failures cause a system-wide malfunction. Nevertheless, we recognize that the impact of partial failures, which do not entirely stop the system, is not captured in this model and could be explored further. We suggest that future research consider integrating interdependence models, such as those based on reliability block diagrams (RBD), Markov chains, and other systemic analysis models, to provide a more comprehensive risk assessment in complex railway systems.
- –
Scenario Simulations: The model can be used to simulate different maintenance scenarios, calculating how criticality would change if preventive interventions were or were not carried out on certain assets. This is especially useful for planning maintenance investments.
3.3.5. Simplified Practical Example
Let us assume an asset (i) with the following values:
Data, attributes, and conditions:
- –
Asset i, condition FF1: If the asset is located in location Az (for example, Line C4, Kilometer 16, and is also type rail, then FF = 2
- –
Asset i, Condition CC1: If the asset is Attribute A1 [rail type], and if Attribute2 [zone] = main track, then Ci,safety = 8.
- –
Asset i, Condition CC2: If the asset in Attribute A3 [area] = Protected, then Ci,environment = 3
- –
Asset i, Condition CC3: If the asset in Attribute A4 [time] = Peak, then Ci,service = 7
- –
Active i, Condition CC4 If active Attribute A5 belongs to [class] Rail and Attribute A6 [failure mode] is Breakage then Ci,cost = 5.
- –
Failure Frequency: FFi = 2 failures per year.
- –
Consequences on Safety: Ci,safety = 8
- –
Consequences on Environment: Ci,environment = 3
- –
Consequences on Service: Ci,service = 7
- –
Consequences on Costs: Ci,cost = 5
CRi = 2 ⋅ (0.4 ⋅ 8 + 0.2 ⋅ 3 + 0.3 ⋅ 7 + 0.1 ⋅ 5) = 2 ⋅ (3.2 + 0.6 + 2.1 + 0.5) = 2 ⋅ 6.4 = 12.8
3.4. Proposed Procedure
Data Collection: The first phase consists of obtaining updated data on demand from different points, e.g., tracking maintenance history, asset classification, asset inventory, section criteria, operational definitions, and others.
Data processing: After collecting the data, they are processed and converted to a commonly understandable format according to each asset type’s respective business rules, considering that the railway system has a heterogeneous asset typology. In this sense, each asset type has a specific rule and sphere of influence. In this step, we define the relationship between each operational entity and several relationship tables to prepare the query that will provide the attribute values for each asset.
Sub-model encapsulation: Within the context of AAS, these processed data are encoded into sub-models, allowing for a current digital reproduction of each asset’s state in time. To avoid manual data processing, we attach to each asset a shell that collects the entities and assigns them a model of inputs and outputs that can then be automatically run to obtain the normalized information on demand.
Criticality Assessment: Sophisticated algorithms with many rules process the data, and scores are determined for each asset. The above scores indicate how vital the security effects, performance, and cost impacts on the given assets will be.
Risk Alerts and Dashboard: With up-to-date information, the system can automatically produce risk alerts on highly critical assets based on their criticality scores, which are displayed on an easy-to-understand dashboard. It helps maintenance managers decide which assets should be prioritized for maintenance. In the case of criticality assessment, real-time data are not necessary because the objective is a strategic assessment. Still, data availability enables the system to apply condition-based techniques or health monitoring tools, of course, with other output models.
Integration with the EAM System: This integrates criticality scores and risk alerts into the EAM system, initiating specific maintenance activities if major changes in risk occur.
4. Case Study
4.1. Scenario and Application
The data model provided an organized structure for capturing and analyzing detailed information about each asset, including attributes such as type, location, current status, and maintenance history. This structure was essential to understanding the relationships between the different components of the network and how the failure of one component could affect others.
The master table was created as a centralized database that integrated data from various sources, such as inventories and maintenance records, through SQL queries. This process allowed the extraction and combination of crucial data, such as failure frequency and asset classes, resulting in a rich and detailed database for criticality assessment.
Using the master table allowed for automating the calculation of asset criticality, assigning a specific value to each asset based on its characteristics and operational context. This automatization was achieved by integrating various relationship tables that identified the levels of intervention required for each type of asset. In addition, cross-referencing with other key tables was performed to obtain specific characteristics, such as network type and station category, which were essential to associate attributes with specific network assets correctly. In other words, the data model and the master table facilitated a more dynamic and effective criticality analysis, allowing the prioritization of interventions and asset management optimization in the rail network.
Similarly, data capture would be carried out for the rest of the characteristics, such as:
Type of substation
Slope height and distance
Maximum altitude (altitude)
Type of high-voltage line
If the maintainable asset is located in a tunnel
If the maintainable asset is on a curve
If the maintainable asset is located in an environmentally protected area
If the maintainable asset is at an upper step
Unavailability time (UT) and failure frequency (FF) for each station or route
Average hourly traffic
Data collection was a comprehensive process that involved obtaining information from multiple sources, transforming it into standard formats, and integrating real-time data for a more dynamic and accurate analysis of railway assets’ criticality. Once the data were collected and linked, customized business rules were implemented for each type of asset in railway systems.
Class: Classification of the asset according to its function or criticality in the railway network.
Type_Via: The type of track where the asset is located, which can influence criticality and the risk of failure.
Track Device: Track-installed devices that can modify the behavior of the asset or influence its probability of failure.
The key results obtained from the criticality analysis in the rail network case study were significant for asset management and optimization. Some of them are summarized as follows:
Signaling systems:
- ○
More than 500 systems assessed.
- ○
Average frequency of failures: 1.2 incidents per year.
- ○
Average delays: 45 min, affecting more than 100 trains and 60,000 passengers daily.
Track devices:
- ○
More than 700 evaluated.
- ○
Frequency of failures: 0.4 per year.
- ○
Serious consequences: traffic disruption on more than 15 km sections, affecting 20,000 passengers and generating costs of 50,000 euros per disruption.
Electrical substations:
- ○
More than 320 assessed.
- ○
Infrequent but critical failures.
- ○
Impact: paralysis of sections of up to 50 km, affecting 200,000 passengers and costs of 100,000 euros per hour of inactivity.
- ○
Proposal: Real-time monitoring systems will reduce downtime by 40%.
Digitalization:
- ○
Key for real-time data update.
- ○
Digital twins for continuous monitoring and fault simulations.
In addition, the technological infrastructure needed to implement advanced criticality analysis presented significant challenges. Robust data management systems, specialized software, and advanced analysis tools such as digital twins and machine learning algorithms were required. Procurement, installation, and maintenance of this infrastructure proved costly and technically complex. Finally, training and change management were critical challenges. Adopting new methodologies and technologies involved a significant change in how asset managers and operational staff carried out their work. This change required a considerable commitment to training and organizational change to ensure that staff were technically trained and aligned with the strategic objectives of the data-driven approach.
4.2. Rule Automation
5. Discussion
During the case study, several significant challenges were faced that impacted the implementation of criticality analysis on the rail network. One of the main challenges was data integration and data quality. The effectiveness of criticality analysis depends on accurate, complete, and up-to-date data. However, the available data were fragmented and came from different sources and systems that were not always integrated, making it difficult to use effectively. Another major challenge was the complexity and heterogeneity of the railway network. The network comprised various interdependent components, each with its technical characteristics, criticality levels, and maintenance requirements. This interdependence required a methodology that considered the criticality of each element and the system as a whole. In addition, the technological infrastructure needed to implement advanced criticality analysis presented significant challenges. Robust data management systems, specialized software, and advanced analysis tools such as digital twins and machine learning algorithms were required. Procurement, installation, and maintenance of this infrastructure proved costly and technically complex.
Finally, training and change management were critical challenges. Adopting new methodologies and technologies involved a significant change in how asset managers and operational staff carried out their work. This adoption required a considerable commitment to training and organizational change to ensure that staff were technically trained and aligned with the strategic objectives of the data-driven approach. Digitalization significantly improved operational efficiency and decision-making in rail asset management through several key strategies. First, automating data collection and processing allowed for a smoother and more accurate information integration. Sensors installed in the rail infrastructure collected real-time data on asset status, eliminating the need for manual input and reducing the risk of errors. These sensors facilitated a faster and more accurate response to maintenance and operational needs. In addition, the implementation of digital twins provided virtual representations of the physical assets, continuously updated with real-time data. These digital twins allowed asset managers to simulate different operational scenarios and anticipate potential failures before they occurred, resulting in a more proactive approach to maintenance and asset management. The ability to anticipate possible problems improved planning and reduced unplanned downtime, optimizing operational efficiency.
Digitalization also promoted interoperability and connectivity between asset management systems, databases, and analysis tools. This connectivity facilitated data integration and provided a more complete and coordinated view of the entire network, improving operational efficiency and decision-making. By sharing and using data effectively, organizations were able to improve cooperation and efficiency in a complex, multinational environment. Furthermore, implementing the data model transformed asset management by providing a powerful tool for continuous criticality assessment, optimizing and preventive maintenance, and improving the safety and reliability of railway operations. The results obtained by implementing data modeling and digitalization in railway asset management have several advantages over traditional methods. Firstly, data-driven methods offer a more accurate and reliable asset criticality assessment due to real-time and historical data, which allow for identifying patterns and trends that may not be evident with more conventional methods.
In addition, traditional methods often rely on manual inspections and qualitative assessments, which can lead to decisions based on assumptions or experience. In contrast, the digitalized approach allows for quantitative and objective evaluation, facilitating prioritizing maintenance actions based on concrete data. This prioritization optimizes resource allocation and improves operational efficiency by reducing unplanned downtime by 25%. Digitalization enables greater adaptability and agile response to changes in the network and operating environment, something that traditional methods cannot match due to their rigidity. Simulating failure scenarios and planning proactive interventions are other significant advantages, as they reduce service interruptions and improve availability. Finally, interoperability and data integration in a unified framework facilitates a more complete and coordinated view of the network, something that traditional methods, with their partitioned systems, cannot provide. In short, using data models outperforms conventional methods in accuracy, efficiency, and responsiveness, significantly improving asset management. The study has several limitations that could be addressed in future research to improve the implementation and effectiveness of the data model in railway asset management. For example:
Complexity and heterogeneity of railway networks complicate data integration and application of the criticality model.
Risk of information overload due to the large amount of data available.
Advanced data filtering and analysis techniques are needed to prioritize critical information.
High initial implementation costs for advanced technology and staff training.
Scalability and flexibility of digital solutions require more attention.
Develop scalable models that are adaptable to different operational contexts and infrastructures.
Creation of standardized frameworks to facilitate the integration of digital technologies in various rail networks.
In summary, addressing these limitations through future research could significantly improve the effectiveness and efficiency of the data model in rail asset management. For the practical implementation of the digitalization-based approach and the data model for railway asset management, several key recommendations can be made:
Developing a Standardized Framework: It is crucial to develop standardized frameworks and protocols that facilitate the integration of various digital technologies in criticality assessment. This development will help overcome data integration challenges and ensure that systems are interoperable.
Training and Change Management: Adopting new technologies requires significant organizational change. Implementing training programs is essential to ensure that staff are technically trained and aligned with the strategic objectives of the data-driven approach.
Cost–Benefit Analysis: Conducting a detailed cost–benefit analysis is essential to justify investments in digitalization. This analysis will help organizations understand the long-term benefits and cost savings of implementing these technologies.
Optimizing Data Quality: Ensuring data accuracy, completeness, and timeliness is essential for practical criticality analysis. Robust data collection and management processes must be established to minimize discrepancies that can lead to erroneous assessments.
Implementing advanced technologies: Advanced tools such as digital twins and machine learning algorithms can significantly improve criticality analysis. These technologies enable dynamic, real-time analysis, optimizing fault identification and prioritization.
Cybersecurity and Data Privacy: It is critical to implement cybersecurity measures to protect the integrity of information used in criticality analysis, ensuring that the data are secure and used ethically.
Application in Real-Time Environments: We expanded the discussion to address the potential for integrating real-time data sources into our model. Specifically, real-time traffic conditions and geometric measurements from inspection trains could be incorporated to enhance the accuracy and immediacy of the criticality assessment process. By including these real-time data sources, we aim to minimize delays in data-driven decision-making, which, in the current system, can sometimes exceed 12 months. This extended delay can impact the responsiveness of maintenance and criticality evaluation, ultimately affecting the safety and efficiency of railway operations. In addition, new IoT systems currently under development hold significant promise for further enhancing the model’s responsiveness. These IoT systems could enable real-time updates on critical infrastructure components, such as level crossings and electrification systems. Such an advancement would allow the model to process up-to-the-minute information on these essential assets, capturing dynamic changes in asset conditions and usage levels that static or delayed data may not reflect. By integrating these real-time data, the model can provide more accurate and timely insights into the state of railway assets, thereby supporting proactive maintenance decisions and reducing the risk of unexpected failures.
These recommendations can facilitate successful implementation and maximize the positive impact of a digital approach to rail asset management.
Next steps: The integration of artificial intelligence (AI) in railway maintenance presents considerable advantages for asset management, enhancing the predictive and preventive capabilities essential for operational efficiency and safety. AI can analyze large volumes of real-time and historical data to forecast failures, detect anomalies, and improve maintenance scheduling with a higher degree of accuracy than traditional methods. For instance, machine learning models can identify wear patterns and potential failure points, allowing maintenance teams to preemptively address issues that may otherwise lead to service disruptions. Moreover, AI-powered simulations can model various operational scenarios, providing valuable insights for optimizing maintenance resources. However, implementing AI in this context also poses significant challenges, such as ensuring the availability of high-quality data, developing standardized AI protocols for safety, and overcoming the compatibility issues with legacy systems. Addressing these challenges is essential to fully leverage AI’s potential in improving the resilience and reliability of railway infrastructure but is necessary to develop a strong structure of data and data models to develop really useful applications using AI’s potential.
6. Conclusions
This study has demonstrated the transformative impact of digitization and criticality analysis on rail asset management. Integrating a vector of operational attributes, such as failure frequency, unavailability time, asset location, and traffic speed, makes it possible to assess the criticality of assets dynamically in real-time. This data-driven approach allows for the prioritization of critical assets, optimizing resource allocation and improving operational reliability, which is essential for the efficient management of critical infrastructure.
The research question focused on whether a systematic method based on digitalization and real-time data could provide more accurate and timely criticality evaluations than traditional static methods. The results confirm that by continuously updating the vector of attributes for each asset, we can more precisely calculate critical parameters, such as failure probability and potential consequences. This method improves maintenance efficiency by focusing on the most critical assets, leading to a 25% reduction in unplanned downtime and a 15% decrease in operating costs.
Integrating advanced technologies, such as digital twins and real-time monitoring, further enhances this approach, allowing for continuous updates and re-calculation of criticality as asset conditions evolve. This dynamic assessment model ensures better decision-making, safety, and long-term sustainability of rail operations.
In conclusion, developing a practical ontological framework for criticality assessment centered on the vector of operational attributes provides a theoretical and practical guide that can be adapted to various railway contexts. This framework addresses the increasing complexity of rail infrastructure management, offering an effective strategy for the future of asset management in critical environments.
Source link
Mauricio Rodríguez Hernández www.mdpi.com
