1. Introduction
Electricity networks represent a critical infrastructure and a pivotal element of the national power grid. Despite the rapid progression of new power systems under the national ’double carbon’ strategy, most high-voltage transmission towers (TTs) in China are subjected to various security risks posed by the surrounding terrain and vegetation. These risks arise due to the long transmission distances and the need to traverse intricate geographical landscapes [
1]. To alleviate potential surface threats adjacent to these lines, responsible departments carry out periodic inspections. In line with scientific and technological progress, the application of remote sensing technology to inspect electrical grid assets has emerged as a key area of research in the development of the smart grid [
2,
3].
For automated inspections of electrical grid assets using remote sensing technology, the primary data sources consist of SAR imagery, optical satellite images, optical aerial photographs, and airborne LiDAR point cloud data. LiDAR point clouds stand out for their exceptionally high spatial resolution, achieving accuracy at the centimeter level. Furthermore, LiDAR data collection is not affected by adverse weather conditions such as cloud cover, fog, or sunlight, enabling continuous monitoring regardless of weather or time of day. This capability makes LiDAR particularly useful during large-scale natural disasters such as snowstorms and earthquakes [
4]. In contrast to SAR or optical imagery, which require elaborate preprocessing to construct 3D point clouds, LiDAR point clouds inherently offer high-precision, structured 3D information of the entire scene without complex processing, thereby substantially simplifying subsequent point cloud analysis and object identification. Consequently, airborne LiDAR data are gaining prominence in automated inspections of electrical grid assets, especially for the detection of TTs [
5].
Thanks to significant advances in artificial intelligence and computer vision technology, object detection is increasingly becoming a key technology for automated inspections of electrical grid assets. Object detection methods have achieved significant success in the image domain, yet their shortcomings become more pronounced when applied to 3D point cloud data. For one, acquiring an adequate number of 3D patterns is challenging; in the case of TTs, for example, only a limited number of 2D samples are publicly accessible [
6]. Additionally, the precision of current 3D object detection techniques is heavily influenced by the density of point clouds, leading to not only reduced detection efficiency but also limited adaptability across different scenarios [
4,
7]. Therefore, there is an urgent demand for the development of fast and robust 3D object detection algorithms for automated inspections of TTs.
2. Related Works
Three-dimensional (3D) point cloud data encompass rich spatial information, providing precise spatial positioning details of scenes, and playing a significant role in the localization and prediction of targets. Moreover, 3D object detection can be broadly categorized into the following types:
Projection-based methods: These methods process 3D point cloud data by projecting the data onto two-dimensional (2D) views (such as front view, top view, side view, etc.). This category leverages mature 2D image processing techniques, such as convolutional neural networks (CNNs), for object detection. The advantage of this approach is the ability to utilize powerful tools and algorithms from the image domain, but it may lose some depth information and may not be efficient in handling occlusion issues.
Point-based methods: These methods operate directly on the raw point cloud data without voxelization or other forms of transformation, directly utilizing the geometric distribution and density information of the point cloud. Methods like PointNet [
8] and PointRCNN [
9] preserve the complete 3D information of the point cloud but have higher computational complexity.
Voxel-based methods: These methods divide the 3D space into a regular grid and quantize the point cloud into 3D cells (voxels), then apply 3D CNNs for further feature extraction and object detection. Methods like VoxelNet [
10] and PointPillars [
11] can reduce the computational complexity to a certain extent while maintaining the spatial structure information but may introduce information loss, especially at a low sampling resolution.
Point-voxel-mixed methods: These methods combine the advantages of the two aforementioned methods, utilizing both the precise geometric information of the point cloud and the computational efficiency afforded by voxelization. They aim to optimize the use of computational resources while maintaining accuracy, for example, by using voxel representation in dense areas of the point cloud and directly processing point cloud points in sparse areas.
Each category has its specific application scenarios and advantages, and the most suitable method should be chosen based on specific requirements, such as accuracy requirements, real-time constraints, hardware resource limitations, etc. Point-based methods, such as PointNet [
8], PointNet++ [
12], PointRCNN [
9], and FARP-Net [
13], do not require data transformation, thus avoiding the loss of effective information. However, point cloud data are voluminous, typically consisting of tens of millions of points with 3D coordinates and other attribute information, such as colors, returns, etc. The uneven distribution in 3D space makes point-based methods computationally expensive and slow. Voxel-based methods require the transformation of point cloud data into regular voxels, using voxels as input for 3D object detection. These methods extend traditional 2D object detection networks to 3D domains and achieve higher efficiency than point-based methods. However, converting non-uniform point clouds into regular voxels may result in a lack of effective information, and due to the sparsity of point clouds, most of the converted voxels are empty, which indicates a significant amount of computational effort and memory will be wasted.
To achieve a more efficient representation of point cloud data for 3D object detection, many researchers have explored methods to transform point cloud data onto a 2D plane, such as generating bird’s-eye views or side views. This allows the use of existing mature 2D object detection networks for fast target recognition. In 2016, Li et al. [
14] adopted an innovative strategy, VeloFCN, which projects point clouds onto a front view and converts them into 2D images, then uses a fully connected network to simultaneously complete object detection and location regression tasks. However, in the front view representation, the sizes of object projections in the image are inversely proportional to their depth. Different object projections are prone to overlapping, making detection tasks more difficult. In 2018, Beltrán et al. [
15] proposed BirdNet, a framework that initially transforms point clouds into a bird’s-eye view (BEV) map, incorporating height, intensity, and normalized density as its three key feature layers. Subsequently, this BEV map serves as input for a faster R-CNN network, which is utilized for 2D object detection. Additionally, the method integrates ground plane estimation to predict the orientation of targets. BirdNet is structurally simple, ensuring real-time detection, but its detection accuracy is not high. Yang et al. [
16] proposed a single-stage dense object detection framework named PIXOR, which projects point cloud data to obtain a BEV and apply a lightweight CNN for feature extraction, performing pixel-level dense prediction to improve detection precision. Subsequently, Yang et al. [
17] optimized PIXOR and proposed HDNet, which introduces map and road semantic information to assist in object detection. Compared to PIXOR, the network structure replaces original deconvolutional layers with more efficient bilinear interpolation layers, enhancing performance. In 2021, Qi et al. [
18] proposed a novel offboard 3D object detection pipeline using point cloud sequence data by making use of the temporal points through both multi-frame object detection and novel object-centric refinement models. In 2024, Vrba et al. [
19] proposed a new 3D occupancy voxel mapping method for object detection and a cluster-based multiple-hypothesis tracker to compensate for the uncertainty of the sensory data, thereby providing robustness to different environments and appearance changes of objects.
BEVs significantly reduce object overlap compared to front or side views, minimizing the impact of target occlusion. Furthermore, they offer a unified and comprehensive global scene representation, allowing for the direct and clear expression of object size and orientation. However, its efficacy significantly diminishes when detecting small objects, such as the components of TTs within the context of automated inspection scenarios. Meyer et al. [
20] proposed LaserNet, a method that projects point clouds to generate six panoramic views, employs convolutional neural networks for feature extraction and, subsequently, integrates the extracted features from these six perspectives for fine object detection. Fan et al. [
21] proposed RangeDet, which projects point cloud data to obtain a range view and apply a Meta-convolutional kernel for feature extraction. Compared to BEVs, range views are more compact and have no quantization errors. RangeDet addresses the “pain point” of poor performance in range view-based object detection methods and even surpasses BEVs in detecting smaller or more distant objects. Some researchers have also leveraged multiple views to achieve more accurate 3D object detection. In 2024, Jing et al. [
22] proposed a multi-branch, two-stage 3D object detection framework that utilizes a semantic-aware multi-branch sampling module and multi-view consistency constraints to enhance detection performance.
In the field of object detection for point cloud data, there is often a trade-off between speed and accuracy, meaning that improving detection accuracy often requires more computational resources and time, and vice versa. Point-based methods have complete information but are difficult to speed up due to the overwhelming amount of information. Voxel-based methods also face the same issue when increasing the voxel sampling resolution to pursue high detection precision. Projection-based methods can make information representation more compact, thereby reducing computational complexity and optimizing detection efficiency. However, BEVs, side views, or range views can cause an inevitable loss of information when converting from 3D to 2D. Therefore, it is important to select the appropriate method based on the specific scenario.
In the context of related works, our contributions are as follows:
A novel 3D TT detection pipeline for UAVs that takes advantage of existing 2D TT datasets, thereby circumventing the need for a dedicated 3D TT dataset.
A fast virtual view generation approach that leverages 2D splatting technology to adaptively refine the projected point size and color attributes, thereby ensuring the accurate visibility of 3D points and greatly improving the view quality.
A novel local–global dual-path feature fusion network for TT detection, which takes advantage of visual attention mechanisms as well as multi-scale features, to provide accurate and robust detection performance.
An extensive experimental evaluation and demonstration in both synthetic datasets and real-world scenarios, including TT inspection in the wild.
3. Methodology
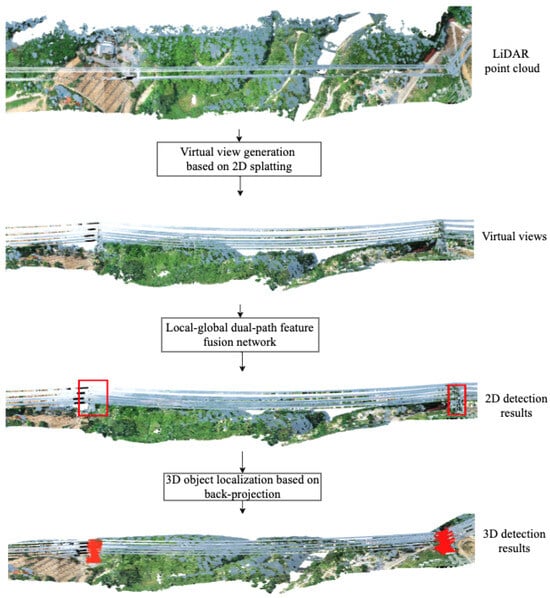
Airborne LiDAR point cloud data cover vast areas and contain large volumes of data, while the targets to be detected are notably small and sparsely scattered throughout the scene, occupying a minimal fraction of the overall area. To enhance detection efficiency without sacrificing the accuracy of TT detection, this paper proposes a fast TT detection method based on virtual views. Initially, the method computes the flight direction by analyzing the spatial extent of the LiDAR point cloud data. With the flight direction established as the x-axis and the elevation direction as the y-axis, a parallel projection matrix is created. This matrix projects the entire LiDAR point cloud onto a vertical plane in real-world coordinates, thereby generating a comprehensive virtual view. To overcome the challenge of detecting the small-sized TTs and potential omissions, this paper puts forth a local–global dual-path feature fusion network. This network extracts the two-dimensional coordinates of all TTs from the virtual view. Ultimately, the extracted two-dimensional positions are converted back into three-dimensional spatial coordinates within the LiDAR point cloud through the application of the projection matrix. The overall pipeline is illustrated in
Figure 1.
3.1. Virtual View Generation Based on 2D Splatting
Point cloud data are typically sparse and irregularly distributed, posing challenges for direct 3D object detection, especially for airborne LiDAR point clouds comprising tens of millions of points. Projecting the point cloud onto a plane to create a denser representation is a more effective method to alleviate these challenges. This approach also allows the leveraging of established 2D object detection techniques [
23,
24], thereby ensuring a robust detection rate. The conventional projection strategies commonly used for airborne LiDAR data include the BEVs and side views. The BEV provides a top-down perspective, with the generated virtual view being an orthogonal projection onto the XY plane. This virtual view can directly show the TTs and the surrounding environment on a global scale. However, since the key features of the TTs are primarily distributed in the elevation direction, their projection onto the XY plane results in a small coverage area and less prominent features (as shown in
Figure 2a), which can make object detection difficult. Therefore, this paper adopts a side-view projection model, which is more conducive to the detection of TTs. Specifically, a parallel projection matrix,
P, is used to project the point cloud onto a vertical plane formed by the flight direction and the elevation direction (as shown in
Figure 2b). This approach helps to better capture the relevant features of the TTs, enhancing the overall detection performance.
It is worth noting that because 3D points lack inherent spatial dimensions, their direct projection onto a 2D plane leads to the creation of numerous empty spaces and allows distant backgrounds to seep through nearby objects. This process, consequently, compromises the original spatial scale and occlusion relationships inherent in the 3D point cloud. As shown in
Figure 2b, the projections of the TT are heavily mixed with those penetrating projections of distant trees. To address this issue, traditional methods typically assign a fixed size to each 3D point based on empirical experience. However, the predefined point size commonly falls short of meeting the demands of practical applications. A size that is too small is inadequate for effectively addressing the spacing and penetrating challenges associated with distant objects. Conversely, if the size is excessively large, it may lead to overlapping and occupation of 3D points in densely populated areas within the point cloud.
Given the inherent sparsity and uneven distribution of 3D point clouds, it is necessary to increase the point size in areas with sparse point density and reduce the point size in areas with high point density. Therefore, an adaptive point size setting strategy is required. To solve this problem, this paper builds upon the surface splatting technique [
25] and incorporates the latest 2D splatting techniques [
26] to automatically set the point size based on local point cloud density. Specifically, each 3D point is treated as a 3D Gaussian distribution, where the spatial probability distribution follows a Gaussian distribution. Its mathematical expression is as follows:
where denotes the center of the 3D Gaussian point, and ∑ is the 3D covariance matrix, which could be calculated by averaging the distances to the top three nearest neighbors, respectively, in the X, Y, and Z directions. When the 3D Gaussian point is projected onto the virtual view via the parallel projection matrix, P, corresponding to the side view, it results in a 2D Gaussian point ; the mathematical expression is as follows:
where denotes the 2D coordinates obtained by projecting , that is, , while is the 2D covariance matrix, which is obtained as follows:
where J is the Jacobian matrix of P.
Following the projection of all 3D Gaussian points onto a 2D plane via the projection model
P, the subsequent procedure entails rendering the virtual view by utilizing the projected geometric and color attributes. The process initiates with the sorting of the projected 2D Gaussian points based on the depth information of each point. The color of a point
x within the virtual image is computed as the weighted sum of the colors of all 2D Gaussian points at that location:
where represents the color (directly provided by LiDAR data) and opacity (with a default value of 1) of the 2D Gaussian point i, while are the Gaussian parameters of i, with indicating the opacity of Gaussian point i at the image pixel x.
It is noteworthy that since the entire view rendering process is based on an individual point, it is very easy to parallelize and accelerate, which can greatly reduce the virtual view generation time.
Figure 3 shows a portion of the virtual view covering a TT.
3.2. Local–Global Dual-Path Feature Fusion Network
To address the challenge of detecting TTs in virtual views, where they are relatively small compared to the whole scene and inherently difficult to detect, this paper refines the feature extraction architecture. Inspired by the principles of visual focus and attention, and incorporating multi-scale feature fusion [
27], we developed a local–global dual-path feature fusion network based on the YOLO framework [
24] for TT detection.
The whole algorithm is divided into three parts: the input part simulates the amplification of visual focus in images, the backbone part performs feature extraction of the local and global dual paths and fuses feature maps at different scales, and the head part realizes the inference prediction of objects.
Figure 4 illustrates the overall structure of the object detection network.
The algorithm model performs sub-block partitioning of the input image at the input end, taking into account both computational speed and accuracy, and divides the image into four sub-blocks. Subsequently, it enriches the feature information of weak targets by locally magnifying the visually attended regions of the partitioned image. The magnified regions are then input through the branch streams for feature extraction and combined with the globally extracted features from the virtual view for detection. The globally extracted features are primarily used for background detection, while the locally extracted features are used for detecting TTs. The design that significantly enhances the local area serves as an extension of the visual attention mechanism, amplifying the overall and detailed information of the target object of interest, while enhancing its spatial location information, making the model more sensitive to small-sized TTs. Additionally, the feature extraction module fuses local and global feature information from different branches at multiple scales, which can more effectively obtain precise location information and high-level semantic information, increasing spatial correlation. Unlike existing attention mechanism modules, the dual-path feature fusion network magnifies the focal area at the data input end and expands the spatial information of the target through multi-scale feature information fusion in dual branches, thereby altering the weight of the feature maps.
The branch input for the local area passes through the convolutional layers of the backbone and fuses features with the convolutional layers of the global area input at multiple scales. This is achieved by using a Concat (channel connection) layer to connect the channels and then passing through a convolutional layer to reorganize the feature channels and update the attention weights for small-sized target areas, removing redundant information. The feature extraction architecture for the branch input is similar to that for the global area input. The feature maps of the branch local input are combined with the global feature map size and the sub-block coordinate information at the input for interpolation and completion, followed by a Concat layer and convolutional modules that merge with the global feature maps. Since the output of the Concat layer realizes the connection of local and global input channel data, the algorithm places a convolutional layer after the Concat layer to integrate feature map information of targets and backgrounds, with a SiLU activation function layer following each convolution. In each branch’s feature extraction stage, a convolutional module with a stride of 2 is used to downsample the feature maps, which are then passed to the Concat layer along with other inputs, forming a multi-scale feature fusion. The resulting backbone feature maps contain the largest receptive field, with the richest semantic and spatial information.
3.3. 3D Object Localization Based on Back Projection
The locations of TTs detected by the local–global dual-path feature fusion network described in
Section 3.2 are on the virtual view rather than in the LiDAR point cloud. Therefore, it is necessary to use the projection model,
P, to back-project the 2D detection results into the LiDAR point cloud to obtain the portions of the point cloud corresponding to the TTs. However, since the side view projection only provides nearly half of the side information of the TTs, direct back projection can only yield half of the 3D point cloud of the towers.
To acquire the complete point cloud of the TTs from the LiDAR data, this paper employs a seed point-based 3D region growing algorithm. By using the detected 3D points belonging to the TTs as seed points, and taking the average Euclidean distance and local point cloud density in both planar and elevation directions as similarity criteria, the algorithm sequentially determines whether the neighboring points near the seed points meet the similarity criteria. If they do, the neighboring points are considered part of the TT and used as new seed points; otherwise, the points are discarded, and this region-growing step is continued until no new seed points are added, at which point the process stops. Consequently, the entire point cloud of TTs is extracted completely, as shown in
Figure 5.
5. Conclusions
With the rapid development of new types of power systems, the ability to detect 3D TTs during the use of drones for automated power grid inspection is a core technical element for understanding and mining potential environmental hazards. However, traditional 3D TT detection methods require searching the entire three-dimensional space, which is not only inaccurate but also very time-consuming. In recent years, although 3D target detection methods based on deep learning have significantly improved detection accuracy, they rely on a large number of 3D TT samples for training, are sensitive to the density of 3D point clouds, and have low detection efficiency, limiting their application in automatic inspection of power transmission corridors.
This paper, based on the projected virtual view, converts irregular three-dimensional point clouds into regular 2D virtual views for detection, which not only effectively utilizes mature image processing technology, especially the proposed local–global dual-path feature fusion network, to achieve efficient feature extraction, but also promotes the integration of multimodal information, combining the depth information of point clouds with the rich texture of images, greatly improving detection accuracy in complex scenes. The overall average accuracy of 3D detection of TTs can reach , and the detected point cloud resolution can reach 0.2 m, which can meet the needs of drone inspection of power transmission corridors.
However, at the same time, the proposed method also has some shortcomings, such as the extracted TT point cloud is not pure, including some ground objects near the tower. One potential solution is to enhance the YOLO framework utilized in this study by updating it to the latest version, which is integrated with the SAM (segment anything model) [
30]. This upgrade is expected to yield more precise profiles of TTs in virtual views, effectively mitigating background noise. Alternatively, increasing the number of virtual views by generating multiple perspectives at varying angles could provide a more comprehensive constraint on the profile of TTs. This additional information would facilitate the 3D region growing algorithm in distinguishing and excluding background points. Future research endeavors will concentrate on these strategies for a comprehensive investigation, aiming to enhance the algorithm’s robustness.