
Considering the literature review on improved solutions for determining the significance of FDI indicators, many of which are computer-based and often utilize machine learning (ML) techniques, it can be concluded that ensemble ML methods are currently a trend for solving such complex problems. However, the existing literature still lacks a sufficient number of references that integrate multiple ML methods, whether different or of the same type. This gap motivated the authors to conduct further research into such methods.
To evaluate the proposed model, the authors used datasets available on the World Bank’s website, which are detailed later in this section. For practical implementation, the dataset first required preprocessing, as described in a subsequent part of this paper. The preprocessed data were then analyzed, classifying all instances where the average FDI as a percentage of GDP was greater than 5% during the period from 2017 to 2021 into two categories: positive and negative (for values below 5%). This classification allowed the positive class to include countries where the conditions were favorable enough for the occurrence of successful FDI.
2.1. Methods
The problem under consideration, with the described dataset preprocessing, falls into the category of classification problems. Two main groups of methods are available for solving such problems: traditional statistical methods like logistic regression and feature selection.
Since the dependent variable follows a Bernoulli distribution rather than being a continuous random variable, the errors cannot be normally distributed. Additionally, applying linear regression would result in nonsensical fitted values, possibly falling outside the 0, 1 range. In cases involving a binary dependent variable, one potential approach is to classify a “success” if the predicted value exceeds 0.5 and a “failure” if it does not. This method is somewhat comparable to linear discriminant analysis, which will be discussed later. However, this technique only produces binary classification results. When the predicted values are near 0.5, the confidence in the classification decreases. Furthermore, if the dependent variable contains more than two categories, this method becomes unsuitable, requiring the use of linear discriminant analysis instead.
Machine learning (ML) is a broad discipline grounded in statistical analysis and artificial intelligence, focused on acquiring knowledge, such as learning rules, concepts, and models that should be interpretable and accepted by humans. In the ML process, it is essential to validate the knowledge acquired, meaning the learned rules, concepts, or models must undergo evaluation. Two main evaluation methods exist, both involving the division of the available dataset into learning and testing sets in different ways.
The first method is the holdout test suite, where the dataset is split into two non-overlapping subsets: one for training and the other for testing the classifier (e.g., a 70:30 ratio). The classification model is built using the training data, and its performance is evaluated using the test data, allowing an assessment of classification accuracy based on the test results.
The second method, K-fold cross-validation, is more effective than using a single test set. In this approach, the dataset is split into k equal parts (or folds). One fold is used for testing, while the remaining folds are used for training. Predictions are made based on the current fold, and the process is repeated for k iterations, ensuring each fold is used for testing exactly once. The accuracy of the learned knowledge is one key measure of success, defined as the ratio of successful classifications to the total number of classifications. Other common evaluation metrics include precision, recall, the F1 measure, and, importantly, the Receiver Operating Characteristic (ROC) curve. Additionally, when dealing with imbalanced datasets, the precision–recall curve (PRC) may be more relevant, as will be discussed later in this chapter.
An important fact that must be noted is that the variables choice in the classification process affects all performance metrics of classification. Therefore, different techniques for variable selection are necessary during the data preparation or preprocessing phase, and dimension reduction methods may also be applied.
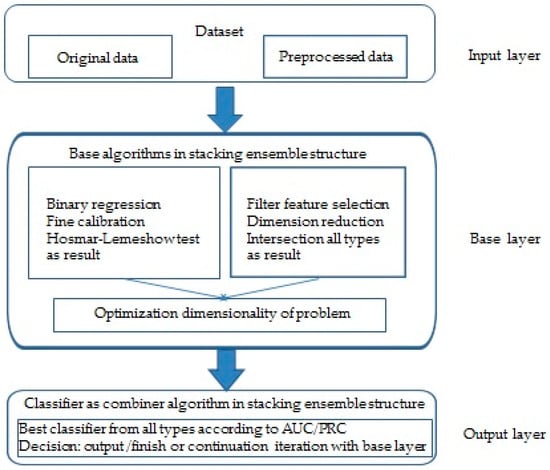
This paper proposes an ensemble ML model for determining the significance of various FDI indicators and predicting the likelihood of successful FDI in a given country based on these factors. As mentioned earlier, the proposed method integrates several feature selection algorithms, a binary regression algorithm, and the best-performing classification algorithm, combining them into a stacking ensemble ML method. The following subsections will briefly describe the methodologies employed, as the ensemble method integrates logistic binary regression with ML-based classification methods and feature selection techniques.
2.1.1. Classification Methodology
The main advantage of this classifier is the convenience of small datasets.
2.1.2. Logistic Regression
In logistic regression, when solving a problem using machine learning (ML) methodology, it is important to use probabilistic classifiers that not only return the label for the most likely class but also provide the probability of that class. These probabilistic classifiers can be evaluated using a calibration plot, which shows how well the classifier performs on a given dataset with known outcomes—this is especially relevant for the binary classifiers considered in this paper. For multi-class classifiers, separate calibration plots are required for each class.
The factor ebi represents the odds ratio (O.R.) for the independent variable Xi.
It indicates the relative change in the odds of the outcome: when the O.R. is greater than 1, the odds increase, and when it is less than 1, the odds decrease. This change occurs when the value of the independent variable increases by one unit.
2.1.3. Future Selection Techniques
Filter: Known examples include Relief, GainRatio, and InfoGain;
Wrapper: Notable examples include BestFirst, GeneticSearch, and RankSearch;
Embedded: These methods combine filter and wrapper techniques.
Weka, a widely used, free-to-use software, includes a feature selection function that reduces the number of attributes by applying different algorithms. This made it the tool of choice for evaluating the proposed model in the case study representing the problem discussed in this paper.
Feature selection methods vary in how they handle the issues of irrelevant and redundant attributes. In the proposed model, the authors utilized multiple filter algorithms, more than the recommended minimum of five, covering all the filter algorithms available in the WEKA 3.8.6 software. All these algorithms were used with the Ranker search method, which produces a ranked list of attributes based on their individual evaluations. This method must be paired with a single-attribute evaluator, not an attribute-subset evaluator. In addition to ranking attributes, Ranker also selects them by eliminating those with lower rankings.
where H represents the entropy of information, and the information gained about an attribute after observing the class is equal to the information gained when the observation is reversed.
As shown in Formula (13), when predicting a specific variable or attribute, InfoGain is normalized by dividing it by the entropy of the class and vice versa. This normalization ensures that the GainRatio values fall within the range [0, 1]. A GainRatio of 1 means that knowledge of the class perfectly predicts the variable or attribute, while a GainRatio of 0 indicates no relationship between the variable or attribute and the class.
FilteredAttributeEval (ClassifierAttributeEval) is a classifier that handles nominal and binary classifications with various types of attributes, including nominal, string, relational, binary, unary, and even missing values. It uses an arbitrary evaluator on data processed through a filter built solely from the training data.
This classifier handles nominal, binary, and missing class classifications using attributes such as nominal, binary, unary, and others.
ReliefFAttributeEval is an instance-based classifier that randomly samples instances and examines neighboring instances from both the same and different classes, handling both discrete and continuous class data.
PrincipalComponents transforms the attribute set by ranking the new attributes according to their eigenvalues. A subset of attributes can optionally be selected by choosing enough eigenvectors to represent a specified portion of the variance, with the default set to 95%.
CorrelationAttributeEval evaluates the importance of an attribute by measuring its correlation (Pearson’s) with the class. For nominal attributes, each value is treated as an indicator and considered on a value-by-value basis. The overall correlation for a nominal attribute is calculated as a weighted average.
2.1.4. Ensemble Methods ML
As mentioned earlier in the Introduction and at the start of this section, ensemble methods are based on the concept that combining algorithms of different types can yield better results than each algorithm individually. There are several types of ensemble methods and their taxonomies, with the most commonly used being the following:
Ensemble learning combines multiple machine learning algorithms into a single model to enhance performance. Bagging primarily aims to reduce variance, boosting focuses on reducing bias, and stacking seeks to improve prediction accuracy;
While ensemble methods generally offer better classification and prediction results, they require more computational resources than evaluating a single model within the ensemble. Thus, ensemble learning can be seen as compensating for less effective learning algorithms by performing additional computations. However, it is important to note that in many problems, including the case study presented in this paper, real-time computation is not a constraint, making this extra computational effort manageable.
Stacking
2.1.5. Proposed Ensemble Model
The proposed stacking ensemble method integrates two types of machine learning algorithms in an asymmetric structure. The first is a binary regression method that initiates the model and evaluates the goodness of fit at each step, while the second is a feature selection algorithm that reduces the dimensionality of the problem by selecting fewer factors. This process continues as long as the classification algorithm, acting as the combiner, permits it. The combiner only grants permission if the dimensionally reduced problem yields better values in terms of PRC (for imbalanced datasets) or ROC AUC (for balanced datasets) before the iterative process begins.
The goodness of the regression model is assessed using the Hosmer–Lemeshow test, and ultimately, the significance coefficients of the final regression model with acceptable fit will refine the prediction by identifying the most important factors.
In this way, the authors aim to develop an optimized iterative procedure that combines the strengths of both methods while minimizing their weaknesses. Although both binary regression and feature selection algorithms are widely recognized as supervised learning techniques used for predictions on labeled datasets, their divergent approaches to binary classification and other machine learning problems highlight their differences.
| Algorithm 1: Determining the importance of indicators for successful FDI |
| 1. * Input data each instace with n1 factors for m instances-countries and preprocess the data. NEXT Perform binary regression and determine non-colinear input indicators; Check regressions goodness IF NO No valid prediction GOTO END ELSE NEXT Check datasets imbalance OneClass is <=25%ofOtherClass IF NO No Treshold TR = ROC AUC ELSE Treshold TR = PRC NEXT 2. ** Perform classification with a minimum of five classification algorithms of different types and identify the algorithm ‘TheBest’ with the highest PRC (or ROC AUC) value. Check goodness of classification IF NO No valid prediction GOTO END ELSE NEXT 3. *** Apply feature selection procedure using minimum 5 different filter algorithms; Using intrsection logic operation determine M <= N attributes; NEXT 4. **** Using TheBest classification algorithm determine with dataset of M attributes new its value TheNewBest NEXT Check regressions goodness IF NO GOTO 6 ****** ELSE GOTO 5 ***** NEXT 5. **** Check goodness of classification IF NO GOTO 6 ****** ELSE GOTO 3 *** NEXT 6. ****** By means of already carried out in the previous Step 5 binary regression determine important indicators for FDI i.e., prediction formula END |
* Step 1. Step 1 starts with an obligatory preprocessing dataset with n1 indicators and m instances—countries as independent variables. The last special column contains binary values of the dependent variable FDI in % of GDP, which indicates the success of FDI in each specific country. To be useful for the application preprocessed dataset, it must have a minimum of four instances, i.e., regions or countries for each used indicator of FDI and successful instances classified as true, each of which has an inflow of FDI in GDP greater or equal to five percent. Before entering the iterative loop, binary regression is made, and collinearity is checked to exclude potentially collinear indicators. The goodness of the Hosmer–Lemeshow model is tested, and if it is greater than 0.05, the procedure can start; otherwise, it is not applicable and cannot determine the significance of individual indicators. Also, before entering the procedure in Step 2, determination of the imbalance of the considered dataset is performed, and in the case of imbalance, i.e., if one of the two classes in the considered binary classification is present with less than 25% in the classification procedure, the PRC evaluator is used as the most significant in the selection of the best from a minimum of 5 different types of classification algorithms; otherwise, the ROC measure is used.
** Step 2. This step involves selecting the best classification algorithm for the model from at least five different types of classification algorithms. It concludes by evaluating the goodness of classification. If the value of the most significant measure, PRC (or ROC AUC), is less than 0.7, the procedure terminates, as it would not be applicable and cannot determine the significance of individual indicators. A 10-fold cross-validation test procedure is used.
*** Step 3. The loop itself begins with Step 3, in which a potential reduction in the dimensionality of the problem is determined between a minimum of five feature selection filter algorithms using a logical function of the intersection of individually obtained results, and the algorithm continues in Step 4.
**** Step 4. In Step 4, with a reduced number of indicators selected in Step 3 by the best classification algorithm, the PRC is determined by comparing an unbalanced set or ROC in the opposite case. It first examines the goodness of the regression model for that reduced number of indicators. If it is OK, it moves on to Step 5, and if there is no fulfillment of this condition, the procedure ends with a previously determined number of indicators in Step 6.
***** Step 5. In this step, it is checked whether the value of PRC, i.e., ROC, is now greater than or equal to the previous one. In the case of fulfillment of this condition, the loop continues with Step 3, and in the opposite case, the loop is exited in Step 6.
****** Step 6. If the optimization procedure for a specific dataset is possible, this algorithm ends with a previously determined number of indicators in Step 6, where significant indicators are determined based on the value of the regression model, and a prediction model can also be provided. The next step leads to the end of this algorithm.
2.2. Materials
2.2.1. Dataset World Bank for FDI Countries around the World
The World Bank Enterprise Surveys (WBESs), part of the World Bank Enterprise Analysis Unit within the Development Economics Global Indicators Department, offer a vast array of economic data covering over 219,000 firms across 159 economies, with the expectation of reaching 180 economies soon. These surveys provide valuable insights into various aspects of the business environment, such as firm performance, access to finance, infrastructure, and more. The data are publicly available and are particularly useful for scientists, researchers, policymakers, and others. The data portal offers access to over 350 WBESs, 12 Informal Sector Enterprise Surveys in 38 cities, Micro-Enterprise Surveys, and other cross-economy databases.
The Enterprise Surveys focus on factors influencing the business environment, which can either support or hinder firms’ operations. A favorable business environment encourages firms to operate efficiently, fostering innovation and increased productivity, both of which are crucial for sustainable development. A more productive private sector leads to job creation and generates tax revenue essential for public investment in health, education, and other services. Conversely, a poor business environment presents obstacles that impede business activities, reducing a country’s potential for growth in terms of employment, production, and overall welfare.
These surveys, conducted by the World Bank and its partners, cover all geographic regions and include small, medium, and large firms. The surveys are administered to a representative sample of firms in the non-agricultural formal private economy. The survey universe, or population, is uniformly defined across all countries and includes the manufacturing, services, transportation, and construction sectors. However, sectors such as public utilities, government services, health care, and financial services are excluded. Since 2006, most Enterprise Surveys have been implemented under a global methodology that includes a uniform universe, uniform implementation methodology, and a core questionnaire.
2.2.2. Preprocessed Dataset World Bank for FDI 60 Countries around the World
Keeping in mind the original data of the World Bank, the authors noticed the necessary reprocessing of the same in the next steps:
For more than a hundred indicators provided in 13 groups, a correct analysis would require about 500 instances, i.e., countries, and there are not that many in the world;
Data exist separately for companies of different sizes, but there are also aggregated data;
For individual countries, data for indicators as independent variables in the research are collected at intervals of about 5 years, and data for the dependent variable in the research for the percentage of FDI in the GDP of an individual country are available annually.
For these reasons, the authors, in the preprocessing of the dataset usable for the intended research, took data for a sufficient number of 60 countries that exist in the period of 5 years, 2017–2021. The independent variable included aggregate data for companies of all sizes and the average investment percentage in the same period for each of the countries included in the study. The dependent variable was shown to be successful in terms of FDI for the percentage of FDI greater than 5.
Source link
Aleksandar Kemiveš www.mdpi.com
