
1. Introduction
Artificial intelligence, particularly convolutional neural networks, has emerged as a powerful tool for addressing previously complex problems using classical techniques. Each artistic style, from Realism and Impressionism to Surrealism and Cubism, possesses distinctive characteristics that manifest in various aspects, such as color application techniques, brushstroke textures, choice of shapes, and visual compositions. Capturing these details automatically requires models to process visual data and understand the underlying complexities within the artwork. One of the main challenges in pictorial style classification is the need for more available high-quality labeled data. The limited number of artworks for training these models can restrict their ability to generalize correctly and accurately recognize styles, primarily because the dataset must adequately represent the existing stylistic diversity. This issue is particularly relevant in studies aiming to differentiate styles with subtle similarities, where the need for more data results in models with lower generalization capacity and, consequently, suboptimal performance. Therefore, the dependence on large volumes of training data exacerbates the situation, hindering the models’ ability to learn complex patterns effectively through varied and abundant information.
More advanced approaches have emerged to address these limitations, such as using Generative Adversarial Networks (GANs), which offer an innovative solution for generating synthetic data. GANs have demonstrated the ability to create visual samples statistically similar to the original dataset. These networks consist of two competing neural networks: a generator that attempts to produce the most realistic images and a discriminator that aims to distinguish between generated and authentic images. This adversarial training process allows the generator to iteratively improve until it can create pictures that are often indistinguishable from real ones to the human eye.
When applying this type of network to generate synthetic data in pictorial style classification, the primary goal is to expand the dataset with images that reflect the intrinsic variability of artistic styles, considering details and combinations that may not be present in the original samples. These synthetically generated images can also include stylistic details and characteristics that contribute to greater diversity and complexity in the dataset. In this way, models trained with a dataset that provides Diffusion model-generated images are expected to achieve better results in terms of accuracy but also demonstrate greater robustness to stylistic variations and subtle details.
The present study aims to explore and assess the impact of integrating synthetic data generated by Diffusion models in the training process of deep learning models for pictorial style classification. The objective is to determine whether including these images can enhance the models’ ability to capture the complexities of the styles and, consequently, increase accuracy and generalization capacity. To achieve this, a series of model training experiments are conducted, varying the proportion of real and synthetic data, to evaluate performance through various accuracy metrics related to precision, generalization capability, and robustness analysis in the face of stylistic variations.
2. Related Works
However, these techniques have limitations. Mixup and CutMix focus primarily on the combination and overlay of visual features, which can result in images that, although they diversify the dataset, still need to preserve stylistic coherence or the distinctive elements of a specific artistic style. This lack of stylistic preservation can be problematic when training models aimed at distinguishing subtle stylistic differences, as the generated images may lose the critical information necessary for the accurate identification and classification of a particular style. Furthermore, combining multiple images into a single example can introduce noise and unnatural features that might confuse the model rather than help it learn relevant features for the task of style classification.
3. Models and Methods
This section describes the adapted methodological process in detail, covering the diffusion models and classifiers used, the generation of prompts, and the creation of new pictorial works for model training.
3.1. Diffusion Models
For all these reasons, Fooocus is the model selected, as it allows the generation of highly diverse images while maintaining coherence within a given style. This level of control and quality is critical for generating synthetic data that effectively complements the dataset without introducing artifacts or inconsistencies that could negatively impact the performance of the classification model, making it the most suitable option for this study.
Fooocus leverages a diffusion-based architecture that transforms a random noise vector into a high-quality, stylistically coherent image through an iterative denoising process. Unlike StyleGAN, which maps a noise vector z into a latent space w for image generation, Fooocus operates within the Latent Diffusion Model (LDM) framework, where the noise is progressively refined step-by-step.
where is the noise scheduling parameter, controlling how much noise is added at each timestep, and represents Gaussian noise. As , the distribution of approaches .
where is the noise predicted by the model, controls the variance of added noise for stochasticity, and is random Gaussian noise.
where is the mean squared error (MSE) between the actual noise and the predicted noise , is the noisy image at timestep t, and is the model prediction of the noise.
The loss function in Fooocus offers clear advantages over the adversarial losses commonly used in GANs, addressing some of the most persistent challenges in generative modeling. First, the diffusion loss is inherently more stable, as it eliminates the adversarial dynamics required to balance a generator and discriminator in GANs. This stability ensures that the model does not encounter common issues such as mode collapse or vanishing gradients, which often complicate GAN training. Second, the noise prediction loss employed in Fooocus is highly interpretable, as it directly measures the accuracy with which the model predicts the noise added during the forward diffusion process. This clarity in the optimization objective facilitates understanding and diagnosing the model’s performance. Lastly, the diffusion loss enables direct optimization of the quality of the denoised output, ensuring that the generated images align with the underlying data distribution. The loss guarantees high-fidelity reconstructions by explicitly focusing on reducing the noise prediction error, making Fooocus an effective and reliable choice for tasks that require precise image generation with stylistic consistency.
3.2. Convolutional Neural Networks for Object Detection
where x is the input to the block, are the weights of the convolutional layers, and F is a non-linear transformation function. The network is trained using the categorical cross-entropy loss function, which measures the discrepancy between the true labels and the model’s predictions:
where is the true label, and is the predicted probability for class i.
The selection of ResNet-50 as the classification model in this study to evaluate the proposed methodology is based on its proven effectiveness in image classification tasks, including artistic style classification. ResNet-50 is a widely used architecture in the literature due to its ability to capture complex visual features, facilitated by its residual block design, which allows for the efficient training of deep networks. This model combines precision and computational efficiency, making it an ideal choice for exploring the impact of diffusion-based data augmentation in the proposed context.
However, it is important to highlight that the methodology presented in this work is not exclusively tied to ResNet-50 but constitutes a meta-method applicable to other classification architectures. The proposed approach is designed to enhance the performance of any model reliant on a large and diverse dataset. This implies that other architectures could similarly benefit from the Diffusion model-based data augmentation implemented in this study. The selection of ResNet-50 is made to establish a clear and consistent experimental baseline for evaluating the effectiveness of the data augmentation method.
3.3. Methodology
The first step of the methodology is based on the generation of detailed prompts. This process is fundamental for guiding the Fooocus model in creating stylistically coherent images. These prompts serve as textual inputs that define the desired visual and stylistic characteristics of the generated artworks. Two distinct approaches are used to generate prompts based on the nature of the artistic style.
For artistic styles with well-defined and easily describable characteristics, prompts are designed by combining the following:
Visual descriptions: detailed textual representations of the artwork’s composition, textures, and colors.
Artistic style: the name of the specific artistic movement.
Representative artist: the name of a prominent artist associated with the style.
where is the i-th prompt, is a detailed description of the artwork’s visual characteristics, is the artistic style (e.g., Baroque and Impressionism), and is a representative artist of the given style (e.g., Caravaggio for Baroque).
For abstract artistic styles, where visual characteristics are less tangible or difficult to express textually (e.g., Expressionism or Minimalism), the prompts are simplified. These prompts only include the following:
where is the i-th prompt, is the artistic style (e.g., Expressionism and Minimalism), and is a representative artist of the style (e.g., Rothko for Color Field).
This approach focuses on providing the model with sufficient contextual information, recognizing at the same time the challenges inherent in abstract styles. For each artistic style, a total of 300 prompts is generated to ensure sufficient diversity and coverage of stylistic elements. The prompts are iteratively refined based on the output quality, ensuring they adequately convey the desired visual and stylistic characteristics. These carefully crafted prompts form the foundation for generating high-quality synthetic images aligned with specific artistic movements.
In the second step, the Fooocus model is employed to generate synthetic artworks based on the prompts. Using its Latent Diffusion Model (LDM) architecture, Fooocus transforms textual prompts into high-quality, stylistically coherent images through an iterative denoising process.
where is the i-th prompt, and represents the textual encoder.
where is the noisy image at timestep t, is the predicted noise conditioned on the prompt encoding , is the variance of added noise for stochasticity, and is the random Gaussian noise.
The iterative refinement ensures that the generated images align closely with the visual and stylistic attributes described in the prompts. This process allows Fooocus to produce outputs that are diverse yet coherent with the specified artistic styles, making them ideal for augmenting the dataset used in the classification task.
where I is the original image, is the mean pixel value, and is the standard deviation.
Here, represents the true label of class i, and is the probability predicted by the model for that class. The fine-tuning process involves retaining the pre-trained lower layers and adjusting the upper layers to adapt to the new classification domain.
4. Experiments and Results
This section details the experiments and results obtained using the previously described methodology. First, the dataset used is presented, followed by an explanation of the metrics employed to evaluate the model’s performance, and finally, the results obtained are analyzed.
4.1. Dataset
The initial dataset exhibits significant diversity in the number of samples per style. Therefore, selective filtering is applied, including only those styles with at least 1000 available images to maintain a balance among the different classes and minimize potential biases in model training. Additionally, certain artistic styles with similar visual and conceptual characteristics are unified. An example of this is the combination of “Early Renaissance” and “High Renaissance” under a single label called “Renaissance”, justified by their stylistic similarity and the limited number of individual samples.
4.2. Metrics
where is an indicator function that takes the value 1 if and 0 otherwise. For multiclass classification, the precision, recall, and F1-score are computed as macro-averages, considering all classes equally:
where C is the number of classes, and , , and denote the true positives, false positives, and false negatives for class c, respectively.
The model’s performance is tested with three different data configurations: only original images, only generated images, and a mixed dataset combining both. This comparison allows for the determination and subsequent analysis of the impact of including synthetic images on improving the classifier’s ability to accurately recognize pictorial styles and better generalize in a varied data environment.
4.3. Results
This section presents the results obtained from evaluating the capability of the ResNet-50 network to classify pictorial styles using different data configurations: real artworks, synthetic artworks, and a combination of both. The validation technique is applied, dividing the dataset into multiple subsets. The model is trained on all but one subset and validated on the remaining one. This process is repeated with different subsets, allowing for a robust estimation of the model’s performance.
4.3.1. Training Parameters
4.3.2. Application of a Pre-Trained Diffusion Model for Synthetic Data Generation
The Fooocus model, a diffusion-based framework, is used in its pre-trained form as provided by its official repository. This decision is based on the demonstrated quality of the model in generating high-fidelity images for various tasks, eliminating the need for retraining in this study.
Given the study’s focus on evaluating the impact of synthetic data on pictorial style classification, the quality and diversity of the generated images are the primary criteria for assessing the model’s suitability. Periodic qualitative inspections of generated images are conducted to confirm their alignment with the intended artistic styles. These inspections evaluate consistency in key stylistic elements, such as texture, color, and composition, ensuring the synthetic data adequately complement the real dataset.
While quantitative measures of convergence, such as loss curves, are typically applicable in the training of generative models, they are not relevant in this case since the model is not retrained. Instead, the evaluation is focused on ensuring that the pre-trained model’s outputs meet the requirements for dataset augmentation and classification.
This study does not involve the retraining of the model. The Fooocus model is selected for its pre-trained capabilities, which allows the study to focus on the application of synthetic data rather than the intricacies of training a generative model. The pre-trained model has been optimized by its developers, ensuring high-quality outputs that are suitable for dataset augmentation. This approach not only reduces the computational burden but also aligns with the study’s primary objective: assessing the impact of synthetic data on the classification of pictorial styles. Please note that a main contribution of our work is the design of detailed, carefully tailored prompts that can be provided to the Fooocus model so it is not necessary to retrain the model to generate high-quality, relevant augmented training images.
4.3.3. Results with Real Data
The initial training of the classifier is conducted using only real artworks, consisting of 300 images per style for training and 100 for validation. The model achieves an accuracy of 58.33%. While this value indicates that the model has moderate performance, it also suggests areas for improvement, especially in styles that show difficulties in making accurate predictions. The adjusted Rand Score obtained is 0.3401, demonstrating that, although the model can group artworks into their respective styles, there is a significant tendency toward confusion among certain visually similar styles.
4.3.4. Results with Synthetic Data
The second experiment uses a dataset of 300 synthetic images per style, with 100 authentic images for validation. The model achieves an accuracy of 51.47%, suggesting that the generated images may not fully reflect the characteristics of authentic artworks. The adjusted Rand Score is 0.2758, highlighting that although the model identifies specific patterns in the synthetic data, there is significant confusion among the styles.
Analyses reveal imbalances in the original dataset, where underrepresented styles such as Ukiyo-e and Color Field Painting exhibit lower classification accuracy than more prevalent styles like Impressionism and Renaissance. A synthetic data generation strategy is implemented to address this, creating a uniform number of 300 synthetic images per style. This approach equalizes the representation of all artistic movements in the training dataset, mitigating biases and enhancing the dataset’s stylistic diversity. Special attention is given to preserving the defining characteristics of each style, such as texture, composition, and color palette, to ensure stylistic coherence. Additionally, qualitative inspections of the generated images ensured that the synthetic data do not introduce repetitive patterns or artifacts, supporting a balanced and diverse training set.
However, significant difficulties persist in distinguishing between styles such as Expressionism and Impressionism, as well as Romanticism and Realism, suggesting that the visual characteristics of the synthetic data are not sufficiently differentiated for these cases. Additionally, notable errors are recorded in the classification of styles such as Cubism and Renaissance, implying that the synthetic artworks generated must fully capture the distinctive features of these artistic movements, affecting the model’s accuracy in these categories.
To evaluate the impact of the synthetic images, performance metrics such as accuracy, adjusted Rand Score, and the confusion matrix are analyzed. These metrics provide indirect insights into the contributions of the synthetic data, revealing improvements for underrepresented styles and challenges in distinguishing visually similar styles such as Impressionism and Expressionism.
To address the potential risks of overfitting due to the inclusion of synthetic data, a balanced dataset approach is adopted. Synthetic images are generated uniformly across styles (300 per style) to prevent any single style from dominating the training set. The model’s generalization ability is also assessed using validation and test datasets of real images. The results indicate no significant discrepancies between training and validation performance, suggesting that the model maintains its generalization ability.
These measures ensure that the synthetic data complement the real dataset without introducing significant biases or overfitting risks, supporting improved classification performance for underrepresented styles while maintaining diversity and stylistic coherence.
4.3.5. Results with Mixed Data
The final experiment utilizes a mixed dataset comprising 300 real artworks and 200 synthetic artworks per class for training and 150 real artworks for validation. The balance between real and synthetic data for each artistic style significantly affects the classification model’s performance. Mixing synthetic and real data ensures that the training dataset maintained uniformity across styles, reducing the risk of overrepresentation or underrepresentation for any specific style. This strategy yields the best results, indicating that a balanced combination of real and synthetic data positively influences the model’s generalization ability. The achieved accuracy is 62.89%, surpassing the experiments with exclusively real or synthetic data. The adjusted Rand Score is 0.3921, indicating a significant improvement in the model’s ability to differentiate between styles when including real and synthetic data.
4.3.6. Summary of Results
5. Discussion
The results obtained in this study allow for the assessment of the effectiveness and limitations of using synthetic data generated with Fooocus, a diffusion-based model, to improve the classification of pictorial styles. This analysis provides a foundation for understanding how combining real and generated data influences the model’s generalization capability and prediction accuracy.
Synthetic data prove helpful in increasing dataset diversity and exposing the model to stylistic variations that may not have been fully represented in the original dataset. The generated images provide additional examples that enrich the training process, especially for styles with well-defined characteristics. For instance, Color Field Painting and Ukiyo-e significantly benefit from including synthetic data, demonstrating a marked improvement in classification accuracy. This indicates that for styles with less complexity and more consistent visual traits, the synthetic data effectively bridge the gaps in the dataset and enhance the model’s learning process. However, the results also reveal notable limitations. More complex styles like Cubism and Baroque exhibit higher misclassification rates when synthetic data are included. This suggests that while diffusion-based models such as Fooocus offer a valuable mechanism for generating diverse training examples, the quality and fidelity of the generated images play a critical role in their utility. The inability of the model to fully replicate the intricate details and characteristics of these styles highlights a key area for further refinement in data generation techniques.
The experiment with the mixed dataset proves to be the most effective, achieving higher accuracy and an adjusted Rand Score compared to the experiments using exclusively real or synthetic datasets. This result underscores the importance of combining real data, which provides authenticity and fidelity, with generated data, which introduces controlled diversity. The inclusion of synthetic data proves especially valuable for addressing challenges in styles such as Cubism and Impressionism, where the additional diversity helped the model reduce confusion between styles with overlapping characteristics. By exposing the model to a broader range of examples, the mixed dataset strategy enhances its ability to generalize and distinguish previously problematic styles.
Despite the observed improvements, the confusion matrix indicates that challenges remain in accurately classifying certain styles, particularly Romanticism and Symbolism. These styles often share overlapping visual characteristics, making it difficult for the model to distinguish them reliably. The synthetic data generated for these styles fail to capture the intricate details or unique elements that define their essence, contributing to the observed misclassifications. This finding highlights the need to refine image generation models like Fooocus and adapt prompts to better capture the details that define these styles. Synthetic data usage is a strategy that must be implemented with caution, as it offers clear benefits in terms of data diversity. However, its effectiveness depends on the generator’s ability to accurately reproduce the characteristic elements of pictorial styles. Styles with more abstract patterns or complex details require a more sophisticated approach in synthetic data creation to ensure the model can learn and generalize effectively.
The comparative analysis of the experiments highlights the superiority of the mixed strategy in terms of overall performance. By integrating generated artwork into the training process, the model can learn from a broader and more diverse dataset, reducing its dependence on the limited volume of real images available. This expanded exposure to stylistic variability allows the model to understand subtle differences between styles better, resulting in improved accuracy. The mixed strategy’s advantage lies in its ability to balance the strengths and weaknesses of the other configurations. For example, while the real-data-only experiment provides authentic features and achieves a baseline accuracy of 58.33%, it lacks sufficient stylistic variability to generalize across underrepresented styles. Conversely, the synthetic-data-only configuration contributes increased stylistic diversity but achieves only 51.47% accuracy, likely due to inconsistencies or limitations in the fidelity of the generated images. The mixed dataset achieves a 62.89% accuracy, combining the real data’s authenticity with the variability introduced by synthetic samples. This represents a 7.83% improvement over real data alone and an 11.42% improvement over synthetic data alone, underscoring the complementary nature of the two datasets.
The adjusted Rand Score is improved to 0.3921 in the mixed strategy, compared to 0.3401 for real data and 0.2758 for synthetic data, reflecting the better grouping of artworks into styles. However, overlaps between Romanticism, Realism, Expressionism, and Impressionism persist, indicating that while synthetic data enhance performance, further refinement in data generation is needed to capture subtle stylistic distinctions. However, the results also suggest a threshold for the effectiveness of synthetic data. While these images enhance performance for styles with defined traits, their utility diminishes for more complex or abstract styles that require higher fidelity in generated examples.
These findings reinforce the notion that synthetic data are a valuable complement to real data, especially for addressing class imbalances and enhancing stylistic diversity. However, the results also highlight a threshold to the effectiveness of synthetic data, particularly when dealing with styles requiring high levels of detail and fidelity. This aligns with the observations in other domains, such as medical imaging.
Diffusion-based models like Fooocus have proven effective in augmenting datasets for well-defined styles but face challenges in replicating rare or complex patterns.
6. Conclusions and Future Work
This study has demonstrated the feasibility and effectiveness of using synthetic data generated through Fooocus, a diffusion-based model to enhance the classification of pictorial styles. The experiments showed that training with real data achieved an accuracy of 58.33% and an adjusted Rand Score of 0.3401, reflecting moderate performance. However, using synthetic data alone resulted in lower accuracy at 51.47% and an adjusted Rand Score of 0.2758, highlighting that the quality of the generated images, while diverse, may not fully emulate the visual richness of real artworks. On the other hand, the mixed approach achieved the highest accuracy of 62.89% and an adjusted Rand Score of 0.3921, indicating that combining real and synthetic data enhances the model’s ability to generalize and effectively recognize pictorial styles. Nevertheless, challenges remain in classifying certain complex styles, such as Romanticism and Symbolism, suggesting the need for further optimization in data generation.
Future research could focus on optimizing the quality of the images generated by Fooocus and improving the specificity of input prompts to better capture the distinctive features of complex styles. Additionally, integrating domain-specific data augmentation techniques and evaluating other classification models, such as InceptionV3 or EfficientNet, could further enhance the robustness of the approach. Extending this methodology to different types of artworks, such as sculptures or engravings, would also help verify the applicability and effectiveness of generated data in a broader and more diverse context.
Author Contributions
Conceptualization, E.L.-R.; methodology, I.G.-A. and E.L.-R.; software, R.M.L.-B.; validation, E.L.-R. and R.M.L.-B.; formal analysis, I.G.-A. and M.Á.M.M.; investigation, I.G.-A. and M.Á.M.M.; resources, R.M.L.-B.; data curation, M.Á.M.M.; writing—original draft preparation, I.G.-A. and M.Á.M.M.; supervision, E.L.-R. and R.M.L.-B. All authors have read and agreed to the published version of the manuscript.
Funding
This work is partially supported by the Autonomous Government of Andalusia (Spain) under project UMA20-FEDERJA-108, project name Detection, characterization and prognosis value of the non-obstructive coronary disease with deep learning, and also by the Ministry of Science and Innovation of Spain, grant number PID2022-136764OA-I00, project name Automated Detection of Non Lesional Focal Epilepsy by Probabilistic Diffusion Deep Neural Models. It includes funds from the European Regional Development Fund (ERDF). It is also partially supported by the University of Málaga (Spain) under grants B1-2021_20, project name Detection of coronary stenosis using deep learning applied to coronary angiography; B4-2023_13, project name Intelligent Clinical Decision Support System for Non-Obstructive Coronary Artery Disease in Coronarographies; B1-2022_14, project name Detección de trayectorias anómalas de vehículos en cámaras de tráfico, and B1-2023_18, project name Sistema de videovigilancia basado en cámaras itinerantes robotizadas; and, by the Fundación Unicaja under project PUNI-003_2023, project name Intelligent System to Help the Clinical Diagnosis of Non-Obstructive Coronary Artery Disease in Coronary Angiography. The authors thankfully acknowledge the computer resources, technical expertise and assistance provided by the SCBI (Supercomputing and Bioinformatics) center of the University of Málaga. They also gratefully acknowledge the support of NVIDIA Corporation with the donation of a RTX A6000 GPU with 48 Gb. The authors also thankfully acknowledge the grant of the Universidad de Málaga and the Instituto de Investigación Biomédica de Málaga y Plataforma en Nanomedicina-IBIMA Plataforma BIONAND.
Institutional Review Board Statement
Not applicable. The study did not involve humans or animals.
Informed Consent Statement
Not applicable. The study did not involve humans.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors upon reasonable request. This is to maintain the integrity and transparency of the research while considering any limitations related to data sensitivity or privacy.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Sigaki, H.Y.D.; Perc, M.; Ribeiro, H.V. History of art paintings through the lens of entropy and complexity. Proc. Natl. Acad. Sci. USA 2018, 115, E8585–E8594. [Google Scholar] [CrossRef]
- Elgammal, A.; Mazzone, M.; Liu, B.; Kim, D.; Elhoseiny, M. The Shape of Art History in the Eyes of the Machine. arXiv 2018, arXiv:1801.07729. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, P.; Liu, K.; Wang, P.; Fu, Y.; Lu, C.T.; Aggarwal, C.C.; Pei, J.; Zhou, Y. A Comprehensive Survey on Data Augmentation. arXiv 2024, arXiv:2405.09591. [Google Scholar]
- Chen, Z.; Zhang, Y. CA-GAN: The synthesis of Chinese art paintings using generative adversarial networks. Vis. Comput. 2023, 40, 5451–5463. [Google Scholar] [CrossRef]
- Xue, A. End-to-End Chinese Landscape Painting Creation Using Generative Adversarial Networks. arXiv 2020, arXiv:2011.05552. [Google Scholar]
- Zhang, Y.; Xie, S.; Liu, X.; Zhang, N. LMGAN: A Progressive End-to-End Chinese Landscape Painting Generation Model. IJCNN 2024, 6, 1–7. [Google Scholar] [CrossRef]
- Gui, X.; Zhang, B.; Li, L.; Yang, Y. DLP-GAN: Learning to draw modern Chinese landscape photos with generative adversarial network. Neural Comput. Appl. 2023, 36, 5267–5284. [Google Scholar] [CrossRef]
- Gao, X.; Tian, Y.; Qi, Z. RPD-GAN: Learning to Draw Realistic Paintings With Generative Adversarial Network. IEEE Trans. Image Process. 2020, 29, 8706–8720. [Google Scholar] [CrossRef]
- Zhang, H. Seg-CycleGAN: An Improved CycleGAN for Abstract Painting Generation. In Proceedings of the 2023 4th International Conference on Computer Vision, Image and Deep Learning (CVIDL), Zhuhai, China, 12–14 May 2023; pp. 416–421. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, C.; Dai, H.N.; Li, P. Stroke-GAN Painter: Learning to paint artworks using stroke-style generative adversarial networks. Comput. Vis. Media 2023, 9, 787–806. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Chakrabarty, S.; Johnson, R.F.; Rashmi, M.; Raha, R. Generating Abstract Art from Hand-Drawn Sketches Using GAN Models. In Proceedings of the International Joint Conference on Advances in Computational Intelligence, Dhaka, Bangladesh, 20–21 November 2020; Uddin, M.S., Bansal, J.C., Eds.; Springer: Singapore, 2023; pp. 539–552. [Google Scholar]
- Berryman, J. Creativity and Style in GAN and AI Art: Some Art-historical Reflections. Philos. Technol. 2024, 37, 61. [Google Scholar] [CrossRef]
- Habib, M.; Ramzan, M.; Khan, S.A. A Deep Learning and Handcrafted Based Computationally Intelligent Technique for Effective COVID-19 Detection from X-Ray/CT-scan Imaging. J. Grid Comput. 2022, 20, 23. [Google Scholar] [CrossRef] [PubMed]
- Nouman Noor, M.; Nazir, M.; Khan, S.A.; Ashraf, I.; Song, O.Y. Localization and Classification of Gastrointestinal Tract Disorders Using Explainable AI from Endoscopic Images. Appl. Sci. 2023, 13, 9031. [Google Scholar] [CrossRef]
- Riaz, A.; Riaz, N.; Mahmood, A.; Ali Khan, S.; Mahmood, I.; Almutiry, O.; Dhahri, H. ExpressionHash: Securing Telecare Medical Information Systems Using BioHashing. Comput. Mater. Contin. 2021, 67, 2747–2764. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image Data Augmentation for Deep Learning: A Survey. arXiv 2023, arXiv:2204.08610. [Google Scholar]
- Kumar, T.; Brennan, R.; Mileo, A.; Bendechache, M. Image Data Augmentation Approaches: A Comprehensive Survey and Future Directions. IEEE Access 2024, 1, 12. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Jackson, P.T.; Atapour-Abarghouei, A.; Bonner, S.; Breckon, T.; Obara, B. Style Augmentation: Data Augmentation via Style Randomization. arXiv 2019, arXiv:1809.05375. [Google Scholar]
- Elgammal, A.M.; Liu, B.; Elhoseiny, M.; Mazzone, M. CAN: Creative Adversarial Networks, Generating “Art” by Learning About Styles and Deviating from Style Norms. arXiv 2017, arXiv:1706.07068. [Google Scholar]
- Cho, Y.H.; Seok, J.; Kim, J.S. DARS: Data Augmentation using Refined Segmentation on Computer Vision Tasks. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 348–350. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond Empirical Risk Minimization. In Proceedings of the 6th International Conference on Learning Representations, (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018; Available online: https://openreview.net/forum?id=r1Ddp1-Rb (accessed on 18 December 2024).
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization Strategy to Train Strong Classifiers with Localizable Features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October– 2 November 2019; pp. 6022–6031. [Google Scholar] [CrossRef]
- Gibson, E.; Giganti, F.; Hu, Y.; Bonmati, E.; Bandula, S.; Gurusamy, K.; Davidson, B.; Pereira, S.P.; Clarkson, M.J.; Barratt, D.C. Automatic Multi-Organ Segmentation on Abdominal CT with Dense V-Networks. IEEE Trans. Med Imaging 2018, 37, 1822–1834. [Google Scholar] [CrossRef]
- Podell, D.; English, Z.; Lacey, K.; Blattmann, A.; Dockhorn, T.; Müller, J.; Penna, J.; Rombach, R. SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis. arXiv 2023, arXiv:2307.01952. [Google Scholar]
- Biswas, A.; Md Abdullah Al, N.; Imran, A.; Sejuty, A.T.; Fairooz, F.; Puppala, S.; Talukder, S. Generative Adversarial Networks for Data Augmentation. In Data Driven Approaches on Medical Imaging; Zheng, B., Andrei, S., Sarker, M.K., Gupta, K.D., Eds.; Springer Nature: Cham, Switzerland, 2023; pp. 159–177. [Google Scholar] [CrossRef]
- Frid-Adar, M.; Klang, E.; Amitai, M.; Goldberger, J.; Greenspan, H. Synthetic data augmentation using GAN for improved liver lesion classification. In Proceedings of the 2018 IEEE 15th International Symposium on Biomedical Imaging (ISBI 2018), Washington, DC, USA, 4–7 April 2018; pp. 289–293. [Google Scholar] [CrossRef]
- Yorioka, D.; Kang, H.; Iwamura, K. Data Augmentation For Deep Learning Using Generative Adversarial Networks. In Proceedings of the 2020 IEEE 9th Global Conference on Consumer Electronics (GCCE), Kobe, Japan, 13–16 October 2020; pp. 516–518. [Google Scholar] [CrossRef]
- Wei, Y.; Xu, S.; Tran, S.; Kang, B. Data Augmentation with Generative Adversarial Networks for Grocery Product Image Recognition. In Proceedings of the 2020 16th International Conference on Control, Automation, Robotics and Vision (ICARCV), Shenzhen, China, 13–15 December 2020; pp. 963–968. [Google Scholar] [CrossRef]
- Ramzan, F.; Sartori, C.; Consoli, S.; Reforgiato Recupero, D. Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment. AI 2024, 5, 667–685. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 43, 4217–4228. [Google Scholar] [CrossRef]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J. Synthesizing Training Data for Object Detection in Indoor Scenes. arXiv 2023, arXiv:1702.07836. [Google Scholar]
- Nag, P.; Sangskriti, S.; Jannat, M.E. A Closer Look into Paintings’ Style Using Convolutional Neural Network with Transfer Learning. In Proceedings of the International Joint Conference on Computational Intelligence; Uddin, M.S., Bansal, J.C., Eds.; Springer: Singapore, 2020; pp. 317–328. [Google Scholar]
- Lecoutre, A.; Negrevergne, B.; Yger, F. Recognizing Art Style Automatically in Painting with Deep Learning. Proc. Mach. Learn. Res. 2017, 77, 327–342. [Google Scholar]
- Sabatelli, M.; Kestemont, M.; Daelemans, W.; Geurts, P. Deep Transfer Learning for Art Classification Problems. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2023, arXiv:1511.06434. [Google Scholar]
- Tan, W.R.; Chan, C.S.; Aguirre, H.; Tanaka, K. Improved ArtGAN for Conditional Synthesis of Natural Image and Artwork. IEEE Trans. Image Process. 2019, 28, 394–409. [Google Scholar] [CrossRef] [PubMed]
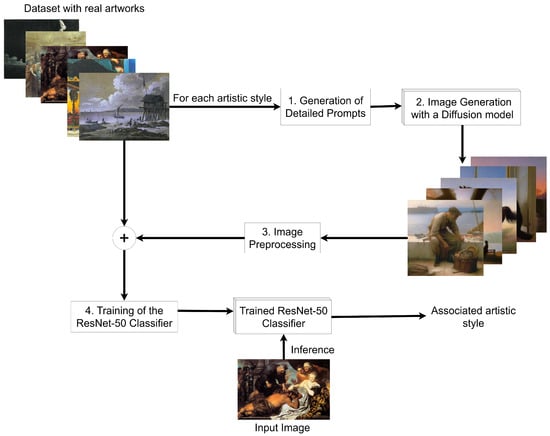
Workflow of the proposed methodology.
Figure 1.
Workflow of the proposed methodology.
Some examples of the artworks that compose the dataset.
Figure 2.
Some examples of the artworks that compose the dataset.

A series of comparisons between real and generated artworks (from left to right).
Figure 3.
A series of comparisons between real and generated artworks (from left to right).

Confusion matrix: training with real data.
Figure 4.
Confusion matrix: training with real data.

Confusion matrix: training with synthetic data.
Figure 5.
Confusion matrix: training with synthetic data.

Confusion matrix: training with mixed data.
Figure 6.
Confusion matrix: training with mixed data.
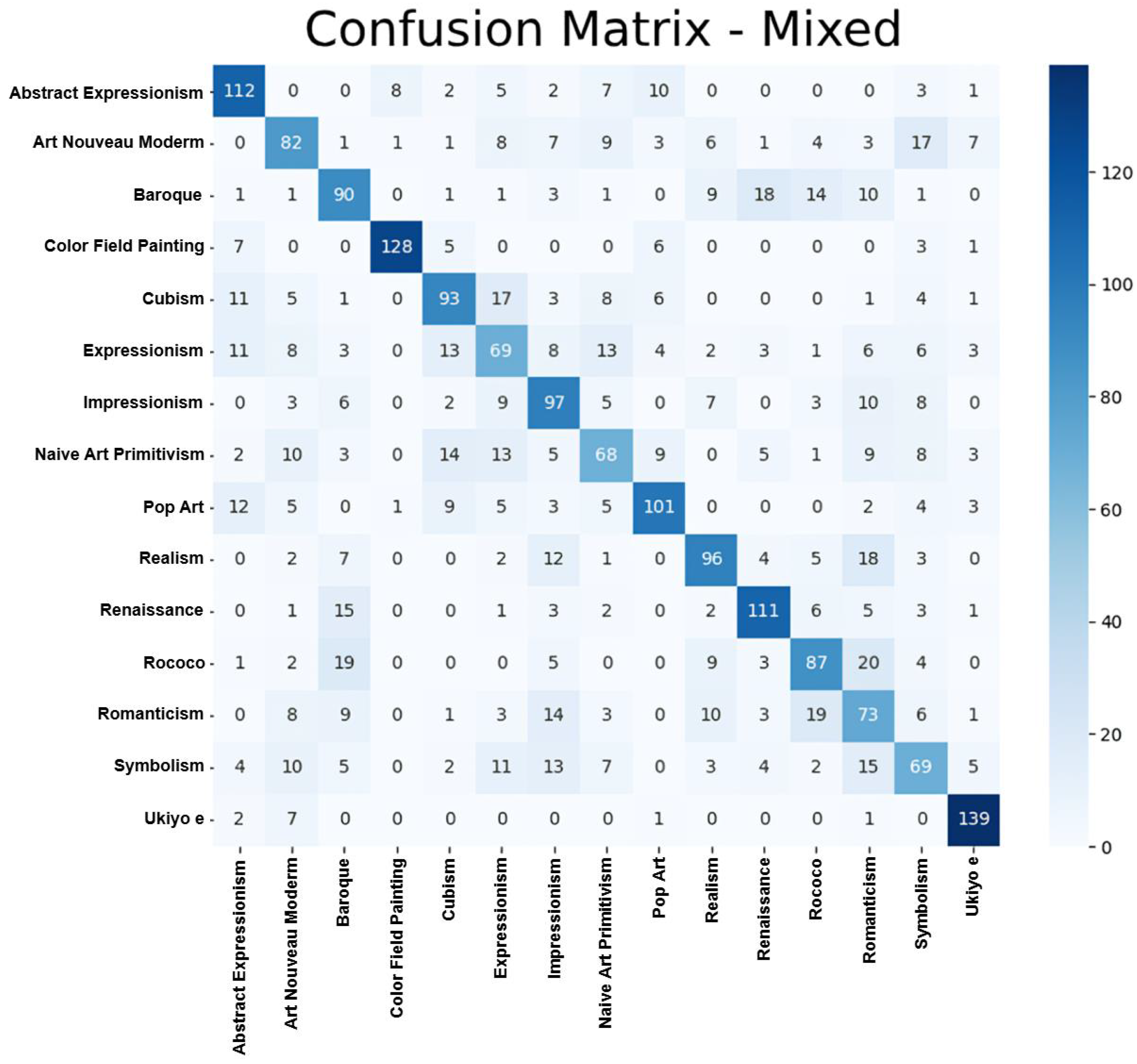
Table 1.
Selected parameters for classifier training.
Table 1.
Selected parameters for classifier training.
| Parameter | Value |
|---|---|
| Batch Size | 32 |
| Learning Rate | |
| Optimizer | Adam |
| Loss Function | Categorical cross-entropy |
Table 2.
Summary of experimental results.
Table 2.
Summary of experimental results.
| Training Data | Accuracy | Adjusted Rand Score |
|---|---|---|
| Real Data | 58.33% | 0.3401 |
| Synthetic Data | 51.47% | 0.2758 |
| Mixed Data | 62.89% | 0.3921 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Source link
Miguel Ángel Martín Moyano www.mdpi.com