1. Introduction
Intertidal ecosystems, as transitional zones between marine and terrestrial ecosystems, hold immense ecological value [
1,
2,
3,
4,
5,
6]. Comprised of mangroves, tidal marshes, and exposed tidal flats, they provide critical ecological functions, such as habitats [
4] for mangrove species, crabs, fish, and migratory birds, and play a pivotal role in coastal protection by buffering against erosion and storm surges [
5,
7,
8,
9]. Beyond their substantial carbon storage [
10] capacity, intertidal ecosystems are among the most dynamic and productive ecosystems on Earth. The confluence of global climate change [
11], sea-level rise [
6,
12], and anthropogenic activities [
13]—such as land reclamation [
14] and coastal aquaculture [
15]—has imposed unparalleled threats on intertidal ecosystems, particularly within the China–ASEAN region.
Accurately and dynamically capturing the spatial distribution and structural characteristics [
16,
17] of intertidal ecosystems is fundamental to their effective conservation and management. However, the pronounced spatial heterogeneity and the dynamic nature of these ecosystems—driven by tidal cycles and vegetation phenology—pose substantial challenges for traditional field-based surveys [
18] and sampling approaches, particularly at large spatial scales. This highlights an urgent need for the development of efficient and high-precision mapping [
19] methodologies, which are pivotal for advancing intertidal ecosystem research and management. Such methodologies underpin critical efforts in ecological monitoring, resource assessment, and conservation planning.
High-resolution spatiotemporal and spectral observation data have been increasingly [
20] employed for mapping intertidal zones. Optical imagery [
21,
22,
23,
24], recognized for its accessibility and extensive spatial coverage, has been widely utilized in monitoring intertidal ecosystems. However, reliance solely on optical data is often constrained by cloud cover, particularly in tropical regions. Unmanned aerial systems (UASs) [
25,
26] provide a flexible and high-resolution approach for intertidal monitoring, offering detailed observations of intertidal features during low tides. Nevertheless, their applicability is limited in scaling up to broader spatial extents. Synthetic aperture radar (SAR) [
27,
28], leveraging active microwave transmission and echo reception, has demonstrated exceptional capabilities in resolving the spatiotemporal dynamics of the water content in intertidal mudflats through its sensitivity to dielectric properties. The interaction between microwaves and saturated sediments induces a shift in scattering mechanisms from volume to surface scattering, effectively capturing the variability in water content distribution. Advanced techniques, including polarization and interferometry, further disentangle surface roughness from dielectric properties, providing mechanistic insights into tidal hydrodynamics and sedimentary processes. Waterline extraction from satellite imagery, followed by tidal correction, remains the predominant method [
29] for delineating coastlines and intertidal zone boundaries. However, tidal information is frequently limited to point-based observations, and the correction process is labor-intensive, presenting challenges for standardized, large-scale mapping.
The integration of cloud-based [
30] platforms for time-series image synthesis, coupled with training samples for machine learning classification [
31,
32,
33], or the application of knowledge-driven, decision tree-based [
34,
35] segmentation, has emerged as a dominant methodological approach for large-scale intertidal zone mapping. Global land-use datasets generated through cloud computing platforms increasingly incorporate intertidal zone information, represented by categories such as surface water occurrence frequency, herbaceous wetlands, and flooded vegetation. Examples include Land Use [
36], MCD12Q1 [
37], Land Cover (LULC) [
37], and Dynamic World [
36], which provide critical references for high-resolution ecosystem monitoring. Notably, Zan et al. developed the ESA land cover product [
38], which includes 11 categories, such as mangrove forests, while GWL_FCS30D [
39] incorporates tidal flats, salt marshes, and mangroves. However, the accuracy of intertidal zone-related classifications within these datasets remains suboptimal due to the complexity of multi-class categorization, complicating the precise delineation of the intertidal zone as a whole. In parallel, single-category [
40,
41] datasets tailored to specific ecosystem types have garnered considerable attention. Wang et al., [
42] for instance, employed Sentinel-2 data to construct covariates, subsequently leveraging object-based segmentation to produce a global mangrove distribution map for 2020. Similarly, Bunting et al. refined 204 regions using Sentinel-2 imagery to update the Global Mangrove Watch (GMW) dataset to version 2.5 [
43] and further employed L-band synthetic aperture radar (SAR) to detect changes, culminating in the creation of GMW v3.0 [
44]. Murray et al. [
45,
46] utilized extensive training samples, random forest classifiers, and Landsat time-series data to generate global tidal flat distribution maps and assess intertidal ecosystem dynamics. Hu et al. [
47] applied a knowledge-based, automated decision tree classifier to map the distribution of salt marshes in China. Despite their contributions, these single-category datasets exhibit marked discrepancies in temporal coverage, spatial resolution, and classification accuracy. Furthermore, inconsistencies in classification standards pose significant challenges to the comparability and the usability of results. Research efforts have also focused on monitoring and classifying coastal wetlands [
48,
49,
50,
51] at both regional and national scales. For example, Wang et al. [
52] developed a coastal wetland map of China using Landsat imagery, categorizing coastal wetlands into tidal flats, deciduous forests, and evergreen forests. However, these studies often fail to effectively distinguish supratidal vegetation from intertidal zones. While large-scale mapping efforts have achieved notable milestones, they continue to face limitations in accurately differentiating complex ecosystem types, such as mangroves, salt marshes, and tidal flats. Addressing these challenges will require advances in standardizing classification criteria, integrating diverse datasets, and refining algorithmic approaches to enhance mapping precision and ecological insights.
The quality control of remote sensing data products is a pivotal technical process for ensuring their consistency and reliability, addressing challenges such as cloud contamination [
53,
54], noise interference [
55], and data gaps [
56]. Diverse methods for reconstructing missing data in dense time-series imagery—spanning spatial, spectral, temporal, and spatiotemporal domains—each exhibit distinct strengths and limitations. Spatial approaches are well suited for simple regions, while spectral methods rely on the availability of complete spectral bands. Temporal techniques, including replacement and deep learning, require the careful mitigation of aliasing effects and high sample demands. In contrast, spatiotemporal methods achieve high accuracy through multidimensional integration but are constrained by significant computational complexity. Advanced techniques such as generative adversarial networks (GANs) [
57] and convolutional neural networks (CNNs) [
58,
59] have demonstrated notable improvements in cloud removal and data gap filling at localized scales; however, their applicability at broader scales remains hindered by computational demands and limited generalization capabilities. Rule-based approaches, such as cloud and shadow masking techniques (e.g., Fmask) [
60], have gained widespread adoption due to their robustness. Connectivity analysis and image filtering are effective in enhancing the spatial coherence of classification outputs, yet they often struggle to preserve boundary details and manage smooth transitions in complex landscapes, potentially resulting in localized information loss or over-smoothing. The continuous enhancement of ancillary datasets—including digital elevation models (DEMs) [
61,
62], climate records [
63], land-use maps, and vegetation cover—provides a crucial foundation for standardized quality control protocols. These advancements have enabled rule-based and domain-knowledge-driven expert systems to perform effectively in feature extraction, particularly in large-scale studies, where their integration of systematic workflows and domain expertise ensures reliable and accurate outcomes.
The intertidal ecosystem, with its pronounced spatial heterogeneity and dynamic characteristics, represents a critical model for understanding complex ecological systems. Early research, through field-based plot surveys, in situ measurements, and the development of distribution maps, revealed significant stratification in the intertidal zone as a transition from land to sea: the high intertidal zone is dominated by species adapted to desiccation and high salinity, while the low intertidal zone supports communities that are heavily reliant on aquatic conditions [
64]. In recent years, advances in satellite remote sensing have broadened the research perspective from local-scale analyses to large-scale assessments of horizontal distribution patterns. Landscape ecological [
65] metrics have been widely employed as quantitative tools in intertidal zone studies, uncovering intricate relationships between spatial attributes—such as fragmentation, patch density, and connectivity—and ecological processes. However, the limitations inherent in small-scale studies, which yield relatively few patches, have hindered deeper investigations into the complex structures of patch dynamics.
Complex systems often exhibit regular spatial distribution patterns that reflect their underlying mechanisms. As a hallmark of scale invariance, power-law distributions have been widely validated across a range of complex systems [
66,
67,
68], including hydrology [
68], climate, and socioeconomics. Recent advances in large-scale remote sensing data processing have further bolstered the application of power-law theory. For example, Feng et al. [
69] employed Pekel’s GSWD [
19] 30 m resolution dataset to confirm the presence of power-law distributions in small water bodies across China, while R. M. Strickland et al. [
67] demonstrated the power-law behavior of glacial depressions through the analysis of 3791 orthophotos. These studies provide valuable insights into the organizational structures and self-organizing dynamics of diverse ecosystems across multiple scales. However, due to limitations in large-scale mapping techniques, the existence of power-law patterns within intertidal ecosystems remains unexplored in the literature.
In conclusion, while notable progress has been made in the mapping of intertidal ecosystems, several challenges persist. Three critical scientific issues have been highlighted in the literature: (1) the suitability of large-scale monitoring methods is constrained by the dynamic characteristics of the intertidal zone, compounded by inconsistencies in classification standards, which limits accuracy; (2) the remote sensing data quality control process requires further refinement; and (3) the spatial distribution of intertidal ecosystems has yet to be validated in terms of adherence to power-law distributions. These challenges are evident at every stage, from data acquisition and classification design to accuracy optimization and mechanistic exploration.
This study aims to develop a high-precision mapping method for intertidal ecosystems based on dense time-series remote sensing data and to explore the spatial distribution patterns of intertidal ecosystems across the China–ASEAN region on a continental scale. The primary objectives of this study are to (1) develop a robust intertidal ecosystem mapping approach; (2) generate a detailed distribution map of China–ASEAN region intertidal ecosystems from 2021 to 2023 using multi-source data; (3) validate the mapping results using high-resolution remote sensing imagery and compare them with existing mapping products; and (4) systematically analyze the spatial distribution characteristics of regional wetlands to provide a scientific basis for the conservation and management of intertidal ecosystems.
2. Materials and Methods
2.1. Study Area
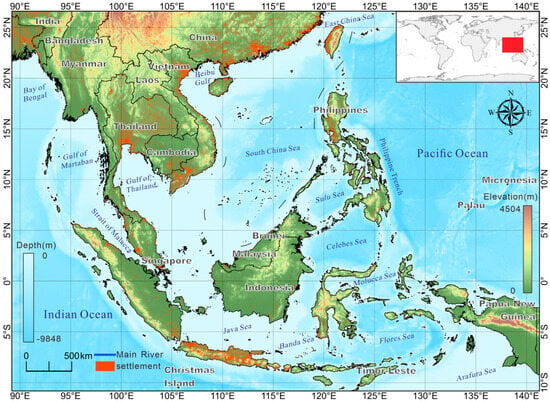
The study area (
Figure 1) spans 26.60°N to 10.82°S and 89.19°E to 141.28°E, covering the ASEAN region, including the Indochina Peninsula and Malay Archipelago. Stretching across approximately 25,000 km of coastline, this region features diverse coastal landscapes, including rocky shores, sandy beaches, mangroves, and salt marshes. Hydrological processes, driven by tropical monsoons, influence salinity gradients, sedimentation patterns, and tidal regimes, while wave energy and sediment transport shape the formation of depositional environments and coastal features. These conditions shape intertidal zones and sustain the region’s ecological and geomorphological diversity.
2.2. Data Sources
This study integrates surface reflectance data from Sentinel-1, Sentinel-2A, and the Landsat 8–9 series (
Figure 2) to support the dynamic monitoring of intertidal ecosystems. These data sources cover the study area from 2021 to 2023. We collected and processed Sentinel-1 VV-polarized data at a 10 m spatial resolution, atmospherically corrected Level-2A Sentinel-2 surface reflectance data, and multi-temporal surface reflectance data from Landsat 8/9 for the period from January 2021 to December 2023. The Sentinel-2 data were cloud- and shadow-masked using the QA60 band to automatically detect and exclude pixels containing cloud cover and shadow. Similarly, Landsat 8/9 multi-temporal surface reflectance data were masked for clouds and cloud shadows using the F-Mask algorithm and QA band, ensuring a high data quality. Utilizing the complete image archive offers ample time-series data in complex tidal environments, thereby enabling a more accurate representation of the dynamic characteristics of the intertidal zone and allowing for the acquisition of additional temporal details of tidal areas. The powerful processing capability of the GEE allows for the parallel processing of the entire available data archive [
19]. The data archives covering the study area from Sentinel-1, Sentinel-2, and Landsat 8/9 were selected using the GEE programming interface, and these datasets were assembled into the required image collection for this study. Across this timeframe, the spectral bands and features from the three data sources were utilized. Spectral covariates derived from these radar and optical datasets included five indices, such as NDVI and EVI, along with their temporal statistics, as well as additional environmental variables, including climate, topography, sediment, and sea surface temperature data. These indices and characteristics were combined with the original bands of each data source, yielding a set of 107 covariates (detailed in
Table 1) to further characterize the temporal and spectral properties of different intertidal features. The modified Normalized Difference Water Index (mNDWI) demonstrates a high sensitivity to changes in suspended sediments and water quality, while the Normalized Difference Water Index (NDWI) is more effective in distinguishing water bodies from bare soil or built-up areas. The Automated Water Extraction Index (AEWI) addresses challenges posed by terrain shadows and other non-water confusions, maintaining robustness against environmental noise. The Normalized Difference Vegetation Index (NDVI) captures the spectral features of mixed pixels comprising vegetation and water, thereby enhancing the separability between supratidal and intertidal vegetation. Meanwhile, the Enhanced Vegetation Index (EVI) offers improved sensitivity in areas with a high vegetation density, overcoming the saturation limitations associated with NDVI. VV [
28] polarization provides a key advantage through its sensitivity to backscattering from smooth surfaces, such as tidal flats and turbid waters, although its capacity to discriminate vegetation is comparatively limited. Within a random forest classification framework, incorporating optical normalized indices, such as NDVI and EVI, allows the model to dynamically adjust feature weights based on variable importance. This approach improves classification accuracy in vegetated regions while maximizing the sensitivity of VV polarization to smooth surfaces in tidal flat areas. Intertidal ecosystems exhibit a characteristic stratified distribution: intertidal vegetation is typically situated near the mean high tide line, whereas tidal flats are located closer to the mean low tide line, experiencing longer inundation periods. The integration of Sentinel-1 data enhances the observation frequency and, owing to its cloud-penetrating capability, facilitates the retrieval of additional tidal flat exposure information in cloud-prone tropical regions.
This study compares several datasets relevant to intertidal ecosystems, as outlined below:
The HGMF dataset [
42] developed by Jia et al. at the Northeast Institute of Geography and Agroecology, the Chinese Academy of Sciences (
https://doi.org/10.7910/DVN/PKAN93) (accessed on 29 December 2024).
2.3. Training Sample Development
This study developed a distributed training dataset covering the coastal regions of China–ASEAN, aimed at accurately predicting the spatial extent of intertidal ecosystems and their components. To ensure the comprehensiveness and the representativeness of the samples, spatial random sampling was employed. Specifically, 50,000 random points were generated within the coastal study area of China–ASEAN, ensuring the balanced and adequate coverage of each ecosystem type (e.g., tidal flats, mangroves, and salt marshes).
The construction of the training dataset referenced multiple high-resolution remote sensing data sources, including high-resolution optical imagery from Google Earth, RGB images from the GF satellite series (GF-1 and GF-2), and supplementary data from electronic maps such as Amap. All imagery used for the training samples was at a spatial resolution finer than 5 m, spanning from 2021 to 2023, thus ensuring both temporal and spatial consistency and clarity.
For sample labeling, all the cloud-free composite metrics derived from the Landsat and Sentinel data were used as a foundational reference, supplemented by high-resolution imagery for visual interpretation. The criteria (
Figure 3) for selecting training samples were as follows: (i) distinct ecological features in the imagery that allow the clear identification of ecosystem types, such as mangroves, tidally submerged sediments, or marsh vegetation; (ii) samples located near well-defined natural coastlines with visible intertidal ecosystems in the imagery; (iii) samples confirmed by multi-temporal images from 2021 to 2023 to ensure ecosystem types remained stable. To improve the accuracy of interpreting complex ecosystem types, additional reference sources were consulted, including studies on China–ASEAN coastal wetlands, coastal atlases, and other publicly available datasets (e.g., Global Wetlands Database). These sources provided supplementary ecosystem characteristics, particularly enhancing interpretation accuracy in areas with similar vegetation types.
The final training dataset consists of 28,138 sample records (
Figure 4), categorized into four classes: mangroves (8378), tidal flats (5864), salt marshes (2513), and other (11,383). Among these, tidal flats, salt marshes, and mangroves collectively constitute the intertidal ecosystem. The “other” category encompasses non-intertidal ecosystems, including deep and shallow marine systems such as seagrass meadows, kelp forests, and photic coral reefs, as well as various terrestrial land cover types like aquaculture zones, agricultural lands, residential areas, sandy coasts, and rocky shorelines. These regions span both the terrestrial ecosystems located above the mean high tide line and the aquatic ecosystems below it.
To ensure the high quality of the training data, rigorous quality control procedures were implemented throughout the sample labeling and dataset construction process. First, publicly available map products were not directly used for sampling to prevent error propagation from existing map inaccuracies. In cases where unmapped areas were encountered—regions not clearly delineated in available public maps or existing wetland classification products—the samples were independently interpreted based on high-quality imagery and reference information. Following sample labeling, a random sampling validation strategy was applied, enabling the independent review of a subset of labeled samples to verify data consistency and accuracy.
2.4. Intertidal Ecosystem Extraction and Classification
2.4.1. Overall Intertidal Ecosystem Extent Extraction
The random forest classification model (
Figure 2) aims to categorize the distribution of different intertidal ecosystem types across China–ASEAN, formalized to represent the three intertidal ecosystem types and non-intertidal ecosystems (other) within the training data. The “intertidal ecosystem” category comprises training data for the three intertidal ecosystem types, and the count for this category is balanced with that of the “other” category through random under sampling. To construct the training dataset, we utilized the Google Earth Engine (GEE) to sample the covariate values at the locations of labeled sample points. The shapefile containing the labeled sample points was first uploaded to GEE’s Assets, where it was stored as a Feature Collection comprising geographic coordinates (latitude and longitude) and categorical labels representing their respective classes. Simultaneously, the pre-constructed covariate dataset (
Table 1), which included time-series features derived from remote sensing imagery and spectral indices, as well as climatic variables and terrain factors, was loaded into the GEE. The covariate values were then associated with the geographic locations of the sample points, extracting the covariate information at each point while preserving the categorical labels. To address potential data gaps, a quality control process was applied after sampling to exclude sample points with missing or invalid values, ensuring data integrity. Finally, the completed dataset was exported as a CSV file, with each record containing the geographic location, class label, and the corresponding 107 covariate values, forming a standardized format required for parameter optimization.
Before deploying the classification model to the Google Earth Engine (GEE), the training dataset containing covariate features was exported to a local environment for hyperparameter optimization. The optimization process employed the “ranger” package in R and a grid search method to systematically identify the best-performing hyperparameter configuration. Grid search is an exhaustive hyperparameter tuning technique that evaluates all possible combinations of specified candidate values for each hyperparameter. In this study, we designed experiments to optimize four key hyperparameters: the number of decision trees, ranging from 100 to 1000 in increments of 100, resulting in 10 candidate values; the number of covariates randomly sampled at each split, spanning from 1 to the total number of covariates (107) in increments of 10, resulting in 11 candidate values; the proportion of observations randomly sampled at each split, ranging from 0.2 to 1.0 in increments of 0.2, resulting in 5 candidate values; and the minimum node size, ranging from 1 to 10 in increments of 1, resulting in 10 candidate values. The total parameter space included 5500 combinations. To balance computational efficiency and experimental coverage, we performed random sampling to select 500 combinations, ensuring uniform coverage across the parameter space. The performance of each configuration was evaluated using the Out-of-Bag Error (OOB Error), which provides a reliable estimate of the generalization error of the random forest model. To ensure stability and robustness, the 10 configurations with the lowest OOB Error were selected, and their hyperparameter values were averaged to derive the final configuration. The optimized hyperparameters were then implemented in the random forest classifier configuration within GEE and applied for training and classification. This process was used to extract and classify intertidal ecosystems across the entire China–ASEAN region, enabling the large-scale, efficient, and accurate mapping of these critical habitats. The model predicts coastal wetland distribution probabilities by running the random forest in probabilistic mode over this three-year period, producing a probability layer for intertidal ecosystem presence.
To minimize misclassification errors, all the training data were utilized to determine the ecosystem type for each intertidal ecosystem pixel above 10 m elevation (corresponding to the maximum elevation in the training set for these ecosystems), excluding pixels classified as tidal marsh or flats and any mangrove pixels identified outside the habitat layer developed by the Global Mangrove Watch project. Following the application of these masks, a threshold of 0.5 was applied to the intertidal ecosystem probability layer, followed by a post-processing step that generated an intertidal ecosystem extent map, using a minimum mapping unit of ten 30 m × 30 m pixels with eight-way connectivity.
2.4.2. Intertidal Ecosystem Classification
In this study, a second set of covariates (
Table 2) (
Figure 2) was developed and utilized in conjunction with a secondary random forest classifier to refine the classification of intertidal ecosystems. Building upon the training samples created during the first step, samples representing the three sub-ecosystems—mangroves, tidal flats, and salt marshes—were selected for this phase. The introduction of the second set of covariates enhanced the classifier’s ability to differentiate among these sub-ecosystems. By integrating multi-temporal spectral indices, radar-derived features, and probability data, the second set of covariates effectively captured the spatial and temporal dynamics of mangroves, tidal flats, and salt marshes, with a particular focus on vegetation vitality and moisture variability. This comprehensive set of covariates improved the model’s sensitivity to ecologically distinct systems with overlapping spectral characteristics (e.g., tidal flats and salt marshes), thereby reducing classification ambiguity and improving overall accuracy.
An independent hyperparameter optimization process was conducted exclusively using training samples for the three sub-ecosystems, employing the same optimization methodology as in the initial classification. This yielded a second set of optimized hyperparameters, which were then applied to train the secondary random forest classifier. To ensure spatial precision and minimize misclassification, the second classification was constrained by a mask representing the intertidal ecosystem extent, as derived from the first random forest classifier.
2.4.3. Expert System Development
To enhance the accuracy of intertidal ecosystem extraction, this study developed an expert system that leverages multiple datasets to mask out errors caused by land cover type confusion during classification.
First, to eliminate misclassifications involving buildings and other artificial structures, we utilized the JRC/GHSL/P2023A/GHS_BUILT_C/2018 dataset (Global Human Settlement Layer), which provides comprehensive global information on residential and building distribution. By overlaying this dataset with our study imagery and spatially filtering out building-related pixels, we prevented the misclassification of urban and surrounding areas, where shadows or water reflections from buildings could otherwise be confused with intertidal water bodies or ecosystems. This step was especially crucial in high-density urban areas. Second, to ensure the accurate delineation of dynamic intertidal water bodies, we applied the JRC/GSW1_4/Monthly History dataset, specifically masking out pixels with 100% water occurrence frequency. This time-series dataset captures globally stable, permanent water bodies, allowing us to exclude high-frequency water pixels and avoid misclassification caused by shadows or transient water surfaces, thereby preventing permanent water bodies from being mistakenly classified as intertidal waters.
Additionally, to prevent confusion between oil palm plantations and natural intertidal vegetation (e.g., mangroves), we utilized the Oil Palm Plantation Probability v20240312 dataset, which offers a global probability map of oil palm plantation distribution. Given the spectral similarity between oil palm plantations and natural vegetation, the high-probability pixels from this dataset were used to effectively differentiate these areas and avoid the misclassification of plantation zones as intertidal vegetation.
During preprocessing, all the masking datasets were spatially aligned with the imagery through standardized spatial matching and preprocessing steps as follows: (1) projection transformation, in which imagery and mask data were converted to a consistent spatial reference system (WGS84) to ensure geographic alignment; (2) spatial resolution matching, where mask data were resampled to match the imagery resolution, thereby avoiding spatial misalignment due to resolution differences; and (3) per-pixel cross-analysis, using Boolean operations to create a union mask layer that integrates all land cover information, ultimately forming a single comprehensive mask layer across the entire study area. This unified mask layer was then applied to the probability layer of the intertidal ecosystem, allowing for the precise extraction of the intertidal regions.
2.5. Accuracy Assessment
This study employed stratified random sampling to assess the classification accuracy of the intertidal ecosystem distribution map for China–ASEAN from 2021 to 2023. Stratified random sampling is widely used in land cover accuracy validation [
19,
46,
70,
71], as it effectively accounts for ecosystem heterogeneity and enhances the representativeness of the samples. The specific steps were as follows:
First, the study area’s intertidal ecosystem was divided into four primary ecosystem categories: mangroves, salt marshes, tidal flats, and other. To ensure the adequate representation of each category in the accuracy assessment, a stratified sampling strategy was used to determine the number of sampling points based on each category’s spatial distribution within the study area. Ultimately, 2244 random sampling points were generated across the entire region, including 820 points for mangroves, 47 for salt marshes, 265 for tidal flats, and 1112 for other categories. The density of these points was proportionally allocated according to the spatial coverage of each category, ensuring the comprehensive consideration of each category’s spatial heterogeneity.
To generate these random sampling points, we utilized the random point generation tool available in the Google Earth Engine (GEE). The latitude and longitude coordinates of each sampling point were automatically generated by an algorithm, ensuring both the independence and even distribution of the sampling points. For accuracy verification at each sampling point, the study first conducted a visual interpretation using high-resolution satellite imagery. During this interpretation, historical Google Earth imagery and field survey data were combined to reclassify each random point into one of the four ecosystem categories, mangrove, salt marsh, tidal flat, or other, based on the actual characteristics of the intertidal ecosystem. To ensure the accuracy of classification results, a double validation mechanism was introduced: the initial interpretation results by interpreters were cross-checked with those from a second independent team, and each verification point was further corroborated using high-resolution imagery. In cases of interpretation inconsistency, the final classification was determined by an expert panel.
Upon completing the classification verification for all the sampling points, a confusion matrix was employed to quantitatively analyze the classification accuracy of the distribution map. The confusion matrix enabled the calculation of four key accuracy metrics: user’s accuracy (indicating the proportion of correctly classified instances within a given category), producer’s accuracy (reflecting the ability to correctly identify a particular category), overall accuracy (indicating the classification accuracy across all categories), and the Kappa coefficient (used to measure the improvement in classification results relative to random assignment). The Kappa coefficient is a crucial metric in accuracy assessment as it accounts for the impact of random chance, thereby providing a more stringent evaluation of accuracy.
2.6. Spatial Distribution and Patch Structure Analysis of Intertidal Ecosystems in China and ASEAN
In this study, we employed power-law fitting and a regression analysis to examine the area–abundance and area–perimeter relationships of intertidal ecosystems and their sub-ecosystems (mangroves, salt marshes, and tidal flats) across the China–ASEAN region. First, we fitted the area and abundance of ecosystem patches in a log-log space to analyze their power-law distributions and validated the fit using the Kolmogorov–Smirnov (KS) test. Additionally, to explore the patch shape complexity and boundary characteristics, we analyzed the area–perimeter relationships in the log space and calculated shape complexity indices, including the Shape Fractal Dimension (SFD), perimeter–area ratio (PAR), mean patch area (MPA), shape index (SI), and patch abundance. These metrics quantified the boundary complexity and fragmentation of the patches, elucidating structural differences among sub-ecosystems within the landscape.
4. Discussion
4.1. High-Precision Classification Scheme for Intertidal Ecosystems
This study presents a novel approach for extracting and classifying intertidal ecosystems, leveraging the GEE platform to provide, for the first time, a detailed spatial characterization of the intertidal zones across China–ASEAN. The success of this study is attributed to three key elements: First, by utilizing multi-source satellite data, the observation frequency at low tide has been significantly enhanced. Second, a robust and efficient time-series image synthesis approach has been introduced, fully harnessing the temporal and spectral characteristics of these images. Third, an expert system has been integrated, based on the unique distribution properties of intertidal ecosystems, implementing stringent quality controls to ensure the accuracy and reliability of the classification results.
The multi-source data integration plays a crucial role in monitoring the dynamic nature of intertidal zones. By merging multi-temporal and multi-sensor images, this study effectively overcomes the limitations of single data sources, with a marked improvement in observation frequency during low tide. The combined use of Landsat and Sentinel images ensures the high spatiotemporal resolution monitoring of intertidal ecosystems, while the complementary strengths of optical and radar imagery substantially enhance the detection of complex ecosystem changes. This data fusion strategy significantly improves the observation accuracy under tidal dynamics, demonstrating considerable potential for broader applications in remote sensing mapping.
Additionally, the two robust and efficient temporal feature extraction schemes are specifically designed to maximize the temporal and spectral features of remote sensing imagery. The first scheme captures comprehensive distinctions between intertidal and non-intertidal zones, while the second effectively differentiates the phenological and tidal cycle dynamics across various intertidal sub-ecosystems. This classification strategy significantly enhances the classification accuracy of complex transition areas (such as tidal flats, mangroves, and marshes) and addresses issues related to omission and misclassification with non-intertidal systems. Furthermore, the random forest classifier demonstrates excellent robustness, maintaining high computational efficiency and classification accuracy in large-scale data processing, providing a stable and reliable foundation for the dynamic monitoring of extensive ecosystems.
Finally, an expert system is introduced to ensure quality control over classification results, guaranteeing precision and consistency. Given the high heterogeneity and the dynamic nature of intertidal ecosystems, single classification methods often face accuracy challenges. To address this, an expert system was developed based on the specific distribution characteristics of intertidal ecosystems to support post-classification validation and quality assurance. By establishing a set of rules, this system effectively identifies and corrects misclassifications associated with seasonal water bodies, building shadows, and terrestrial vegetation.
4.2. Comparison with Other Studies
The high-resolution intertidal ecosystem mapping dataset generated in this study demonstrates outstanding classification accuracy and ecosystem differentiation, particularly excelling in detailed classification and the handling of complex transitional zones. The Murray et al., 2022 [
45] primarily targets the overall intertidal ecosystem (
Figure 9), labeled broadly as “intertidal ecosystem” and encompassing a wide range of ecosystem types. While Murray et al., 2022 [
45] achieves substantial accuracy in large-scale intertidal mapping, it lacks fine distinctions within specific ecosystems, such as mangroves and tidal flats. By contrast, our dataset not only maintains a high overall classification accuracy but also distinctly differentiates detailed components within intertidal ecosystems. The Murray et al., 2019’s UQD [
46] dataset, focused solely on tidal flats, uses brown to denote tidal flat regions with high classification accuracy. However, this dataset is limited to tidal flat classification, excluding other ecosystems, such as mangroves and marshes. In comparison, our study accurately classifies tidal flats while also extending coverage to other intertidal ecosystems, providing a more comprehensive mapping result. The Jia et al., 2023’s HGMF [
42] and Bunting et al., 2022’s GMW3.0 [
44] datasets focus on detailed mangrove classification, demonstrating excellent capability in identifying mangrove core areas globally. Nonetheless, both datasets exclude tidal flats and other intertidal ecosystems. Our study matches their accuracy in mangrove classification while expanding ecosystem classification across the entire intertidal zone using multi-source data, resulting in a more inclusive classification. Zanaga et al., 2022’s ESA World Cover [
38] dataset encompasses global vegetation types, including mangroves, grasslands, and shrublands, but shows reduced classification accuracy within intertidal areas, especially in vegetation boundary zones. By implementing a refined classification strategy, our study not only enhances the accuracy for vegetation types such as mangroves but also achieves an improved classification performance in complex terrains.
The statistical results (
Figure 10) from multiple large-scale remote sensing mapping algorithms illustrate the area distribution of intertidal, tidal flat, and mangrove ecosystems across various countries. In this study, the estimated area of intertidal ecosystems is 82,044.67 km
2, representing a 9.12% increase compared to the 74,560.45 km
2 estimated by Murray et al., 2022 [
45]. At the national scale, the areas in China, Bangladesh, Indonesia, and India constitute a substantial proportion of both datasets. Our estimates indicate that China’s intertidal area is slightly higher than that in Murray et al., 2022 [
45], while the estimates for Indonesia are closely aligned. Additionally, area differences for Malaysia, the Philippines, and Vietnam are minimal, with fairly consistent results across both datasets. The area of tidal flats estimated in this study is 18,975.8 km
2, which represents a 37.86% decrease relative to the 30,538.35 km
2 estimated by the UQD [
46] dataset. At the national level, the UQD [
46] dataset shows larger estimates for tidal flats in China, India, and Bangladesh, while our study yields relatively lower values for these countries. Similar discrepancies are observed in Indonesia, Malaysia, and Myanmar, although the overall distribution trend remains consistent across the countries. Furthermore, the tidal flat areas in Vietnam, Cambodia, and the Philippines show only minor differences between the two datasets, with closely aligned estimates.
In terms of mangrove ecosystems, our study estimates an area of 58,134.61 km
2, compared to 51,067.02 km
2 in the GMW dataset and 50,597.37 km
2 in the HGMF 2020 [
42] dataset, indicating 3.55% and 4.91% lower estimates, respectively. At the national level, the mangrove areas in Indonesia, Myanmar, Malaysia, and China are slightly higher in our study compared to the other datasets, though the distribution patterns remain broadly consistent. The mangrove areas in the Philippines and Vietnam show minimal area differences across all the datasets. Notably, the area estimates for Bangladesh, Thailand, and Cambodia show limited divergence across the datasets, presenting a relatively consistent distribution pattern.
In summary, compared to multiple global remote sensing datasets, this study reveals certain differences in the area estimates for intertidal, tidal flat, and mangrove ecosystems. The most significant discrepancies are observed for tidal flats, particularly in China, Indonesia, and Bangladesh, whereas the estimates for mangrove ecosystems show relative consistency, with only minor deviations in a few countries.
The classification approach in this study provides a more comprehensive treatment of the diversity within the intertidal zone, demonstrating significant advantages, particularly in handling transitional and complex mosaic areas. It effectively distinguishes spatial interweaving and boundary ambiguities between different ecosystem types. The estimated area of the intertidal ecosystem in this study is 9.12% larger than that in the Murray_2022 [
45] dataset, largely due to our integration of multi-source Sentinel-1 and Sentinel-2 data, which effectively addresses the spatiotemporal limitations of Landsat data and captures more previously unobserved areas. In contrast, our estimated tidal flat area is 37.86% smaller than that in the UQD [
46] dataset, as the latter includes coastal aquaculture ponds in its intertidal zone, resulting in overestimation. Additionally, our estimates for mangrove ecosystems differ by 3.55% and 4.91% from those in the GMW [
44] and HGMF [
42] datasets, respectively, reflecting the maturity and robustness of the current mangrove extraction algorithms. Unlike the GMW [
44] and HGMF [
42] datasets, which rely on single-year data, this study extracts multi-year average characteristics for mangroves based on three years of multi-temporal data, effectively mitigating the influence of seasonal, tidal, or anomalous climate effects on single-year data, thus providing a more stable and integrated representation of ecosystem characteristics.
4.3. Driving Mechanisms and Ecological Responses of Patch Structure in Intertidal Zones and Their Sub-Ecosystems
The patch size–abundance and area–perimeter relationships of intertidal zones and their sub-ecosystems follow power-law distributions, driven by a combination of natural and anthropogenic factors. First, tidal dynamics and sediment transport are the primary natural drivers shaping this spatial pattern. The periodic rise and fall of tides not only sculpt the physical structure of intertidal patches but also promote patch fragmentation and redistribution through sediment accumulation and erosion. Biological processes also play a crucial role; for instance, the root systems of mangroves and salt marsh plants stabilize sediments, forming larger and more stable patches, whereas smaller patches lacking such biological protection are more susceptible to erosion. Coastal development and land-use changes exacerbate patch fragmentation, leading to the gradual reduction in size of larger patches and an increase in the number of smaller patches. This fragmentation drives the size–abundance relationship to follow a power-law distribution, with smaller patches dominating spatially.
The power-law distribution highlights the self-organizing nature and dynamic equilibrium of intertidal ecosystems under natural and human-induced pressures. Small patches, due to stronger edge effects and lower ecological connectivity, are more vulnerable to external disturbances, which compromises their biodiversity and ecological function. In contrast, larger patches offer more stable habitats, support more complex ecological networks, and exhibit greater resilience. This power-law relationship between patch area and perimeter unveils how intertidal ecosystems adaptively adjust patch structures to accommodate environmental changes, reflecting ecosystem adaptability and recovery mechanisms at multiple scales.
The power-law distribution observed in intertidal ecosystems aligns with similar patterns identified in other complex systems, such as small water bodies and glacier depressions. These systems share the characteristic of scale invariance, adhering to universal spatial organization principles shaped by natural dynamics. However, intertidal ecosystems and their subsystems exhibit additional regional adaptations driven by the combined influences of tidal cycles, sedimentary processes, and biological stabilization. These dynamics further highlight their consistent behavior under diverse driving forces.
This study integrates intertidal ecosystems into the broader framework of complex systems science, using high-resolution mapping to uncover their spatial structures and deepen our understanding of self-organization and dynamic equilibrium in highly dynamic environments. Moreover, the findings demonstrate that power-law distributions are not only applicable to relatively static ecosystems but also extend to highly dynamic transitional systems like intertidal zones. This result expands the applicability of complex systems theory and provides novel theoretical tools for modeling and managing dynamic ecosystems under global change scenarios.
This finding offers new insights into coastal ecosystem management globally, particularly as intertidal ecosystems’ self-organizing capacity becomes increasingly pertinent for addressing the multiple pressures imposed by climate change, rising sea levels, and human activity.
4.4. Limitations, Potential Applications, and Future Development Directions for Intertidal Ecosystem Mapping
Although the use of multi-source satellite data has increased the temporal observation frequency, capturing the full spatial detail of dynamic tidal regions remains challenging. The heterogeneous tidal ecosystems exhibit complex land–water interactions, where fine-scale features may be lost at lower spatial resolutions or during tidal transitions. Furthermore, in certain regions, temporal dynamics—such as seasonal or intra-annual changes in ecosystem conditions or seasonally dynamic seagrass—may not be fully captured due to the static nature of the sample design, which limits its ability to monitor finer-scale temporal variations. The intrinsic variability of tidal ecosystems, such as seasonal flooding and geomorphological changes, can introduce errors in reference data collection, meaning that existing datasets may not fully reflect changes within the tidal zones. Moreover, the lack of necessary ground-truth data may limit the reliability of the classification results, leading to datasets that inadequately capture the changes within the intertidal zone. This also leads to confusion between salt marshes and other terrestrial categories, such as paddy fields, abandoned aquaculture ponds, floodplain grasslands, and Lacustrine Wetlands. Additionally, given the large volume of data, the abundance of features, and the limitations of GEE computational resources, the dataset generated in this study is limited to a spatial resolution of 30 m. Tidal conditions exert a substantial influence on the analysis of intertidal zones, particularly in the integrated use of SAR and optical imagery. Tidal-induced fluctuations in water levels directly affect the scattering characteristics of SAR, with a pronounced impact on the VV polarization response. During high tide, the increased dielectric constant of water modifies the scattering mechanisms, while the exposure of sediments at low tide alters the scattering properties, thereby influencing the classification accuracy. Similarly, tidal variations markedly alter the reflectance characteristics of optical imagery. High tide leads to an expansion of water bodies, enhancing reflectance, whereas low tide exposes wetlands, resulting in an increase in reflectance.
The resulting 30 m spatial resolution map of the China–ASEAN intertidal ecosystems for 2021–2023 is critical for a deeper understanding of ecosystem structures and dynamics in this region and provides essential support for the sustainable management of coastal zones. Leveraging open-access remote sensing data and the Google Earth Engine cloud computing platform enables the rapid monitoring of the coastal ecosystems in the China–ASEAN region, with a potential for broader global application. Furthermore, this approach lays a foundation for tracking the spatial distribution and change trajectories of global coastal ecosystems as far back as the 1980s. Future research should prioritize establishing more standardized classification systems and integrating higher-resolution satellite data (e.g., World View, GF, and Planet) to further enhance the mapping accuracy. At the same time, international collaboration and joint field surveys will ensure the collection of higher-quality and more representative sample data, which is essential for the development and validation of large-scale remote sensing products. Future work will combine higher-resolution remote sensing data with advanced deep learning models to capture large-scale ecological changes. The training sample design will focus on change detection, enabling the more precise capture of dynamic aspects in intertidal zones and seasonally dynamic freshwater ecosystems, such as salt marshes and river floodplain grasslands. Future research should integrate automated mechanisms for filtering SAR data noise and aligning tidal time-series data. To handle large volumes of imagery, image acquisition periods should be optimally selected based on tidal height and water level fluctuations, thereby minimizing the influence of irrelevant data. Additionally, further investigations should focus on the synergistic use of different polarization data on cloud computing platforms, as well as the optimization of polarization selection under tidal conditions, to enhance classification accuracy in complex environments. This will ultimately contribute to the more effective management and conservation of vulnerable ecosystems.