
1. Introduction
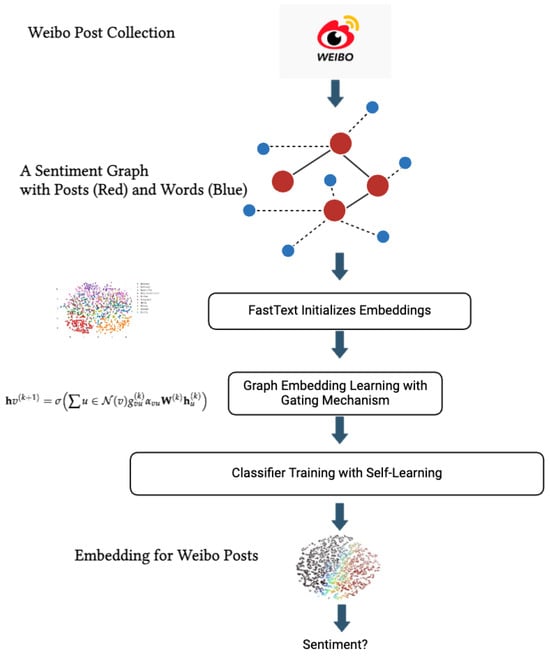
To address these limitations, we propose a novel graph-based framework that integrates self-supervised learning to significantly enhance Weibo sentiment analysis. Our approach introduces a unique “sentiment graph” structure that leverages both word-to-post and post-to-post connections. Unlike traditional models that treat text as isolated sequences, this sentiment graph forms a relational network where words, phrases, and entire posts are treated as interconnected nodes. These connections enable the model to capture fine-grained emotional cues and context-dependent meanings within Weibo posts, particularly those subtle cues that are often overlooked in sequence-based processing. The sentiment graph goes beyond conventional sentiment analysis by embedding two distinct types of relationships: semantic connections between words within individual posts and contextual connections between posts based on thematic or emotional similarity. This dual-level relational structure allows the model to understand not only the immediate sentiment expressed by a post but also how similar sentiments might manifest across different posts in nuanced ways. For instance, it can discern shifts in emotional tone across a user’s posts over time, detect recurring themes of frustration or distrust, and differentiate between subtle variations in sentiment that traditional text-based approaches might miss.
Beyond simply applying graph neural network, our approach is further distinguished by the introduction of a novel gated mechanism within the graph, a key contribution that enhances the model’s ability to capture nuanced sentiment variations. This gating function, integrated within the sentiment graph, allows the model to dynamically filter sentiment signals from neighboring nodes based on their intensity and relevance. By selectively controlling the flow of information, this gated mechanism enhances sensitivity to subtle emotional cues, such as sarcasm or shifts in sentiment intensity, which are common in social media discourse. This enables the model to better differentiate and represent the complex emotional landscape within Weibo posts.
Further distinguishing our approach is the integration of self-supervised learning within the graph framework. We employ a novel self-supervised loss function that operates on the structure of the sentiment graph itself, enabling the model to learn nuanced representations of emotional relationships without relying solely on labeled data. This self-supervised objective is designed to capture latent emotional structures within the graph, such as implicit hierarchies or clusters of sentiment expressions, which can enhance the model’s ability to generalize beyond predefined sentiment categories. By dynamically adjusting to patterns uncovered within unlabeled data, our model can detect complex, layered emotional states that emerge from both the linguistic and relational context in Weibo posts. Integrating sentiment graph and self-supervised learning, we enhance Weibo sentiment classification in a large margin.
In summary, this paper makes four key contributions to advancing Weibo sentiment analysis. First, we introduce a novel sentiment graph framework that leverages the relational connections between words, phrases, and posts, enabling richer contextual understanding than sequence-based models. Second, our dual-level relational structure captures both semantic and contextual relationships, allowing the model to interpret nuanced sentiment patterns across posts. Third, we propose a gated mechanism within the graph framework, enabling the model to selectively adjust information flow based on sentiment intensity—a critical improvement for capturing the nuanced sentiment shifts in social media. Fourth, by incorporating a self-supervised learning objective tailored to the sentiment graph, our model learns complex emotional representations without heavy reliance on labeled data, making it adaptable to diverse, unlabeled social media contexts. Together, these innovations represent a significant step forward in accurately capturing the dynamic, multi-layered emotional landscape of social media platforms like Weibo.
4. Methodology
4.1. Construction of Sentiment Graph
To capture the nuanced sentiments in Weibo posts, we construct a sentiment graph , where denotes the set of nodes, and denotes the set of edges. The nodes in are of two types, “word nodes” and “post nodes”, connected through two types of edges: “word-to-post” and “post-to-post”.
For each post , we link a word node to p if w appears in p. Formally, we define an edge if . This inclusion-based link enables the model to associate specific words with posts, capturing the lexical structure of posts and the contribution of individual words to post sentiment.
If , we establish an edge . This thresholded connection allows the model to capture relational context across similar posts, reflecting trends and contextual sentiment relationships.
The resulting graph captures both lexical content through word-to-post edges and contextual similarity through post-to-post edges, forming a hybrid structure that models both individual post composition and broader relational patterns.
4.2. Feature Transformation Using FastText Embeddings
To leverage the sentiment graph , we transform each node in into an embedding that captures sentiment information via a graph neural network (GNN).
We initialize word nodes and post nodes with FastText embeddings. Let represent the initial embedding of a word node w, and represent the initial embedding of a post node p. FastText’s subword-based embeddings are particularly effective for informal language and slang, which are common in Weibo posts, by capturing morphological nuances within words and enhancing the model’s understanding of variations in sentiment expression.
where we have the following:
denotes the neighbors of v;
represents attention weights that capture the importance of neighboring nodes;
is a learnable weight matrix;
is our proposed learnable gating function that dynamically controls the influence of each neighboring node based on its sentiment features;
is a non-linear activation function.
The gate acts as a sentiment-sensitive filter, strengthening or weakening the information flow based on the sentiment intensity or nuance present in each node’s content. This iterative process produces a final embedding for each post node p, capturing both structural and word-level nuances as well as sentiment-specific context of interactions. The gating mechanism, as our contribution, enables the GNN to handle the rich sentiment variance in Weibo data more effectively, leading to more accurate sentiment representation and analysis.
The final embedding of each post node p serves as input for the sentiment classifier. The classifier maps to a sentiment label , allowing us to predict sentiment based on the aggregated emotional context of each post.
4.3. Model Training with Additional Self-Supervised Loss
To enhance the model’s generalization ability, we introduce a novel self-supervised loss that reconstructs the affinity structure of the sentiment graph , complementing the primary classification loss.
where is the cosine similarity between embeddings and , and is a binary indicator for the existence of an edge between u and v. This loss encourages nodes with an edge to have similar embeddings, while non-connected nodes remain less similar.
where is a hyperparameter that balances the two objectives. This combined loss encourages the model to learn both the sentiment classification task and the inherent relational structure within the sentiment graph, ultimately improving its ability to capture nuanced emotions in Weibo posts.
This methodology enables our model to effectively learn from the unique relational patterns in Weibo data, providing a robust approach to sentiment classification in social media contexts.
5. Experiment
5.1. Datasets
Dataset 1, sourced from the “SMP2020 Weibo Emotion Classification Technology Evaluation”, contains COVID-19-related Weibo posts categorized into six emotional labels: “neutral”, “happy”, “angry”, “sad”, “fear”, and “surprise”. For this study, the dataset was simplified to two sentiment categories: “Positive” (comprising “happy” and “surprise” emotions) with 4620 posts, and “Negative” (including “angry”, “sad”, and “fear” emotions) with 2526 posts. The ”neutral” posts were removed to refine the focus on binary sentiment classification and improve sentiment analysis reliability. In total, the processed Dataset 1 includes 8606 training samples, 2000 validation samples, and 3000 test samples.
Dataset 2 is derived from the “weibo_senti_100k” dataset, featuring 119,984 labeled Sina Weibo comments—59,993 positive and 59,991 negative. This dataset provides straightforward sentiment labels, supporting precise sentiment classification tasks and allowing us to evaluate the model’s performance and generalization on Weibo comment data.
5.2. Example of Data
In the following Weibo review analysis table, we explore a diverse set of posts categorized by sentiment (labeled 0 for negative/neutral and 1 for positive). This sample reflects the various emotional tones and expressions often found on social media platforms.
Sentiment Label Distribution: The table predominantly features posts labeled “0”, representing neutral or negative sentiments, with a smaller portion labeled “1” for positive sentiments. This distribution illustrates the range of emotions present in social media, from frustration and disappointment to gratitude and joy.
Role of Emoticons and Social Media Language: Emoticons like [Tears], [Dizzy], [Haha], and [Playful] are integral to sentiment interpretation, as these symbols often convey emotions more directly than words alone. This underscores the unique challenge of sentiment analysis on platforms like Weibo, where textual and visual elements combine to express sentiment.
Contextual Complexity of Posts: Some posts, such as ID 62050, mention specific events or contexts (e.g., “More negative news about CMB”), making sentiment difficult to assess without background information. Additionally, comments on shared content (e.g., ID 81472) add complexity, as accurate sentiment analysis requires understanding both the primary text and the referenced content.
Direct vs. Indirect Sentiment Expression: Positive posts labeled “1” often express clear sentiments, such as gratitude or well wishes (e.g., IDs 7777 and 6598). In contrast, posts labeled “0” show negative sentiments, including frustration and confusion, as seen in IDs 100399 and 82398, where users express dissatisfaction with experiences like getting lost or facing unclear airline policies.
This analysis highlights the nuanced challenges in Weibo sentiment analysis, where accurate assessment requires interpreting not only direct emotional cues but also contextual references and emoticons.
5.3. Environment
5.4. Data Preprocessing
This section illustrates the flow of the primary preprocessing steps used in our experiments.
- 1.
Text Cleaning: To remove noise from the text, we applied regular expressions to filter out HTML tags, irrelevant URLs, emoticons, and extraneous letters and numbers, retaining only the essential text content.
- 2.
Word Segmentation: We employed the Jieba word segmentation library, a versatile tool for Chinese word segmentation. Jieba offers several segmentation modes: precise, full, and search engine modes. Additionally, it allows for custom dictionaries, enabling tailored segmentation for specific domain vocabularies.
- 3.
Stopword Removal: Stopwords are commonly removed in text preprocessing, as they do not contribute meaningful information. We utilized the Harbin Institute of Technology’s stopword list as our primary source and performed secondary filtering with the Baidu stopword list to enhance text quality.
- 4.
Numerical Conversion: We used a Tokenizer to transform the cleaned text data into numerical format, making them compatible with model processing.
5.5. Experimental Parameters
For model training, the Embedding layer was used to encode the input integer sequences into dense vector representations. The graph neural network architecture included 128 hidden units with a dropout rate of 0.5. We set the batch size to 16 and the learning rate to 0.0001.
5.6. Baseline Models
We evaluate our model’s performance against several established baselines in text classification and sentiment analysis:
Word2Vec: A neural network model that learns word embeddings by predicting context words (skip-gram) or target words (CBOW), effectively capturing semantic relationships between words.
FastText: An extension of Word2Vec that represents each word as a collection of character n-grams, enabling the model to capture subword information and improve performance with rare or misspelled words through enhanced morphological understanding.
K-Nearest Neighbors (KNN): A non-parametric, distance-based classification method that assigns labels based on the majority label among the k nearest neighbors, often utilizing word embeddings or document vectors to measure proximity in text data.
Convolutional Neural Networks (CNNs): Apply 1D convolutional layers on word embeddings to extract local n-gram features, which are aggregated via pooling layers to produce fixed-size vectors for classification tasks.
Long Short-Term Memory (LSTM): A recurrent neural network (RNN) variant designed for sequential data, employing gates to regulate information flow and effectively capturing long-term dependencies in text, which is particularly useful for sentiment analysis.
CNN-BiLSTM: Combines CNNs to extract local patterns with a bidirectional LSTM (BiLSTM) to capture contextual information from both past and future tokens, leveraging the strengths of both architectures for improved performance.
Gated Recurrent Unit (GRU): A streamlined alternative to LSTM with fewer gates and no separate cell state, providing the efficient training and effective modeling of sequential dependencies, especially for shorter text sequences.
- Dual-Channel Graph [40]: Utilizes attention mechanisms to capture syntactic structures and multi-aspect sentiment dependencies, improving the model’s interpretation of complex, multi-faceted sentences.
- Knowledge-Enhanced Graph [39]: Incorporates external sentiment vocabularies to enrich aspect-based sentiment analysis by enhancing the model’s understanding of sentiment-heavy words and phrases, representing the current state of the art.
- Gaussian Similarity Modeling (GSM) [41]: Employs Gaussian similarity metrics to enhance GNN performance by improving the representation of node relationships.
- Cross-Channel Graph Information Bottleneck (CCGIB) [42]: Leverages cross-channel graph information to improve GNN performance by effectively balancing node information and graph sparsity.
5.7. Classification Results
Among the traditional word embedding models, FastText outperforms Word2Vec by a notable margin, achieving a 4% higher accuracy on Dataset 1 and a 3% increase on Dataset 2. This improvement in performance highlights the benefits of subword-level information in FastText, which likely aids in capturing finer nuances in sentiment classification. KNN, as expected, yields the lowest scores among all algorithms, underscoring its limitations in handling complex sentiment data compared to deep learning models. Notably, the CNN and LSTM models both demonstrate strong performance, with accuracy and F1 scores surpassing 90% on both datasets, showing the advantages of capturing spatial and sequential information in text data, respectively.
The dual-architecture models, such as CNN-BiLSTM and GRU, demonstrate incremental improvements over their single-architecture counterparts. These models leverage the strengths of both convolutional and recurrent neural networks, leading to better contextual understanding and feature extraction. For example, the CNN-BiLSTM model achieves 93.08% accuracy on Dataset 1 and 98.16% on Dataset 2, demonstrating its ability to capture intricate sentiment features effectively across diverse datasets.
The most advanced models, including the Dual-Channel Graph and Knowledge-Enhanced Graph architectures, exhibit the highest accuracy and F1 scores. The Dual-Channel Graph model reaches 96.20% accuracy on Dataset 1 and 98.85% on Dataset 2, while the Knowledge-Enhanced Graph model slightly surpasses it, achieving 96.75% and 99.00% accuracy on Datasets 1 and 2, respectively. These models capitalize on graph-based techniques that enhance text representations by capturing complex relationships and contextual dependencies. The Knowledge-Enhanced Graph model, with added semantic information, demonstrates a superior ability to generalize across both datasets, which is particularly advantageous for sentiment classification tasks with nuanced expressions.
Our model, which combines both dual-channel and Knowledge-Enhanced Graph techniques, sets a new performance benchmark with 97.51% accuracy on Dataset 1 and an impressive 99.56% on Dataset 2. This model achieves the highest precision and F1 scores as well, indicating a robust capacity to handle both positive and negative sentiments accurately. Its enhanced architecture likely allows for the extraction of more comprehensive sentiment features, leading to superior generalization. The consistently high performance across both datasets suggests that this model could be well suited for real-world applications in sentiment analysis, where data diversity and complexity often challenge simpler models.
In summary, these results affirm that complex, graph-based models provide the best performance for sentiment classification, with each incremental architectural enhancement translating to measurable improvements in classification metrics. The higher performance of “Our Model” indicates the effectiveness of combining dual-channel and knowledge-enhanced techniques, especially for nuanced sentiment classification tasks, and underscores the potential of these advanced architectures in real-world applications.
5.8. Ablation
For Dataset 2, the pattern is consistent, with the complete model outperforming ablated versions. The model without the Post-to-Post Link shows an F1 score of 98.3%, which is slightly below the full model’s F1 score of 98.82%. Removing the Word-to-Post Link or self-supervised loss also leads to similar minor drops in the F1 score, suggesting that each component contributes incrementally to model effectiveness. Finally, removing the gating mechanism also causes performance drop. The full model achieves the highest performance across all metrics, emphasizing the importance of each component in enhancing accuracy, precision, and F1 scores.
5.9. Sensitivity Check
The chart shows two lines: the flat blue line representing the Knowledge-Enhanced Graph (static), and the dynamic orange dashed line representing our model. As is varied along the x-axis, our model exhibits significant changes in its output, indicating sensitivity to this parameter. The performance of our model initially rises, peaking at a certain value before gradually declining. This pattern suggests that our model is optimized for a specific range of values, where it performs most effectively, and that its performance diminishes when moves beyond this optimal range.
Despite the sensitivity of our model to the parameter, it consistently outperforms the Knowledge-Enhanced Graph (static) across all tested values. This finding is significant because it highlights our model’s ability to adapt to parameter variations while maintaining an edge over the static baseline. The reference line, though stable, is effectively outpaced by our model at every point, demonstrating the latter’s flexibility and superior performance.
5.10. Training and Validation Losses
6. Visualization of Attention Maps
Sample 1: Negative Sentiment In the first sample, “Too much! @Rexzhenghao: More negative news about CMB lately…, high attention scores are assigned to sentiment-rich phrases such as ”Too much!” and “negative news”. This distribution indicates the model’s focus on words that express strong sentiment, as these words likely inform the negative classification of the review. By emphasizing these emotionally charged terms, the model highlights its ability to prioritize critical phrases that contribute to an overall negative tone.
Sample 2: Mixed Sentiment The second sample, “A little tempted to join???? [Sneak smile] Still deciding on the time [Frustrated],” presents a more complex sentiment structure. Attention scores are distributed across phrases such as “tempted to join” and “still deciding”, reflecting a balance between positive curiosity and hesitation. The model appears to account for emoticons like “[Sneak smile]” and “[Frustrated]” in its score allocation, suggesting an understanding of these symbols as mood indicators. This nuanced spread of attention underscores the model’s capacity to capture ambivalence, an essential feature in sentiment analysis when dealing with mixed signals.
Sample 3: Positive Sentiment In the final sample, “[Great] Thanks to everyone supporting Juanwa’s sesame! [Love you]” attention scores are concentrated on overtly positive expressions like “Great”, “Thanks”, and “Love you”. These words carry strong positive connotations, which the model prioritizes in its interpretation. By focusing on these appreciative and affectionate terms, the attention mechanism successfully identifies signals of positive sentiment, thereby enhancing the accuracy of its sentiment prediction.
Overall, the attention score maps show a consistent pattern where the model prioritizes words that convey emotional tone, especially those that are sentiment laden or directly indicative of the review’s mood. This pattern suggests an effective alignment between attention distribution and sentiment-bearing elements within text. Such insights can be instrumental in refining the model’s attention mechanisms, ensuring a greater focus on sentiment-relevant words and improving sentiment analysis accuracy. These observations further highlight the potential for using attention-based interpretability to validate and adjust the model behavior in sentiment prediction tasks.
6.1. Time and Resource Analysis
One of the most notable strengths of the model is its resource-efficient architecture. The training process uses only 16 GB of memory, underlining its suitability for environments with limited computational resources. This efficiency is further amplified by the adoption of a mini-batch training strategy, which allows the model to handle large-scale datasets effectively without requiring excessive hardware. By dividing the data into manageable mini-batches, the model ensures that memory usage remains low while maintaining high performance. This design choice not only reduces the cost of infrastructure but also ensures scalability, making the model adaptable for a wide range of applications, from small-scale research projects to large-scale industrial tasks.
6.2. Applying to Other Social Media and Language
The promising performance of our model on Twitter sentiment analysis suggests its potential applicability to other social media platforms, such as Facebook, Instagram, and YouTube. These platforms often feature diverse linguistic styles, including short posts, comments, and hashtags, where the adaptability of our approach in capturing contextual and semantic nuances can prove valuable. Furthermore, extending our model to support multilingual sentiment analysis could enhance its utility for global applications, particularly in addressing sentiment dynamics in languages with limited annotated datasets. By leveraging transfer learning or cross-lingual embedding techniques, our model can be fine-tuned to analyze sentiment across languages, enabling insights into cultural and regional sentiment trends and fostering broader applications in marketing, policy-making, and social impact analysis.
7. Conclusions
and Future Work
In this paper, we have presented a novel approach to Weibo sentiment analysis, addressing the unique linguistic and emotional complexities of social media discourse through a graph-based framework that integrates self-supervised learning. By leveraging a sentiment graph with relational structures and an innovative gated mechanism, our model captures the nuanced emotional cues that traditional sequence-based models often miss. Our approach enhances the ability to interpret multi-layered emotional expressions, making it particularly relevant for the real-time monitoring of public sentiment, especially during crises such as the COVID-19 pandemic. Through this framework, we demonstrate significant improvements in accurately identifying and interpreting the subtle emotional shifts and intense sentiment fluctuations that characterize Weibo posts. These advancements underscore the potential of our model to support applications in mental health, policy-making, and societal well-being by offering more reliable insights into collective moods and emerging emotional trends.
Future Work: Future research could expand upon our sentiment graph framework by incorporating multimodal data sources, such as images and videos, which are prevalent in Weibo posts and can enhance emotional interpretation. Additionally, the application of cross-lingual transfer learning to this framework may allow it to be adapted to other social media platforms with different languages and cultural nuances. Another promising direction is the refinement of the self-supervised loss function to further capture temporal dynamics, enabling the model to track sentiment changes within user posts over time. Finally, exploring privacy-preserving mechanisms to analyze social media sentiment while safeguarding user data could broaden the adoption of this technology in sensitive contexts like mental health and crisis response, making it a valuable tool for both researchers and practitioners.
Source link
Chuyang Wang www.mdpi.com