1. Introduction
The rapid growth of the mobile internet, e-commerce [
1], and social media platforms [
2] has created an overwhelming array of choices for online users. To address information overload and help users efficiently discover relevant products [
3], recommender systems have emerged as crucial tools for personalized recommendations [
4]. Traditional recommendation algorithms mainly rely on historical user behavioral data, such as browsing and purchase records, to model user–item similarities [
5,
6,
7,
8,
9]. They are limited by their single source of information, overlooking valuable multimodal information embedded in product images and text descriptions. Recommendation algorithms that can fuse multimodal data have gradually become a hot research topic [
10].
Multimodal recommendation systems enhance recommendation performance by leveraging diverse data types to supplement user interaction history [
11]. The core of multimodal recommender systems lies in the fusion and modeling of heterogeneous data, which mainly include two modal forms: text and image [
12]. Researchers have proposed a variety of fusion strategies, which can be mainly categorized into two main types: early fusion and late fusion [
13]. Early fusion improves feature representation by combining information from multiple modalities at the initial stage of data processing [
14]; late fusion integrates the results of different modalities at the output stage of the model to improve the accuracy of decision making [
15].
Recent success of transformer models has highlighted attention mechanisms’ effectiveness in recommendation systems for weighting important interaction features and capturing user preferences [
16,
17,
18,
19,
20,
21,
22,
23,
24]. However, attention mechanisms can be vulnerable to noisy data, potentially overweighting invalid signals. To address this limitation, studies have attempted to combine the attention mechanism with graph neural networks (GNNs) to better handle complex relationships and multimodal data [
11]. MMGCN [
25] constructs a dichotomous user–item graph for each modality and applies GNN on these graphs to learn the feature representations of users and items. MGAT [
18] captures the fine-grained preferences of users for different modalities by constructing multimodal interaction graphs. It also introduces a gate attention mechanism to adaptively capture the preferences of users for different modalities during the information dissemination process. GRCN [
26] identifies and prunes potential false alarm interaction edges through a graph refinement layer to optimize the structure of the user–item interaction graph. DualGNN [
27] employs a dual graph structure—user–microvideo bipartite graph and user co-occurrence graph—to collaboratively learn user–item interaction graphs leveraging correlation between users. The correlation between users is used to collaboratively learn each user-specific fusion modality. EgoGCN [
28] is able to adaptively extract multimodal information at the edge level and adjust features of unimodal nodes under the supervision of other modalities. CAmgr [
16] focuses on using user preferences to guide model training, extracting unique features along with generic feature information, and the cross-attention mechanism focuses on improving the representation and fusion of information through user and item interaction ID features. However, the above methods may lead to insufficient learning of certain modes by the model in case of modal imbalance, thus affecting the overall recommendation effect.
Item–item isomorphisms are introduced into recommendation systems due to their ability to mine potential associations between items. HCGCN [
29] and LATTICE [
30] further capture the potential relationships between user behavior patterns and items through graph convolution operations. However, this structure may face challenges in dynamic recommendation environments to update delays, which affects the effectiveness of real-time recommendations. LUDP [
31] explores potential relationships between items by constructing an item–item similarity graph based on multimodal features. In addition, LUDP constructs a user preference graph that captures users’ preferences for different modalities through their historical interaction behavior with items. FREEDOM [
10] proposed a method to freeze the item–item graph structure, which reduces computational and memory overhead by constructing the graph before training and keeping it fixed during training. FREEDOM also introduced a degree-sensitive edge pruning method for denoising interaction graphs, which rejects possible noisy edges with high probability when sampling the graphs. POWERec [
8] introduced prompt-based user interest learning and weak modality augmented training, which models multimodal user interests through shared user embeddings and modality-specific prompts. Although FREEDOM [
10] and POWERec [
8] focus on optimizing computational and storage overheads while improving model performance, these models still need to deal with the inhomogeneity of modal information and inter-modal dependencies in real-world applications in order to model both products and users more accurately.
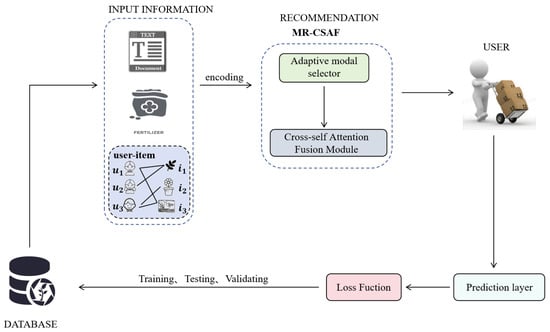
To solve the above challenges, we propose MR-CSAF, an adaptive multimodal recommendation algorithm based on cross-self-attention fusion. As shown in
Figure 1, MR-CSAF builds on FREEDOM by adding an adaptive modality selector and a cross-self-attention fusion module. First, MR-CSAF’s adaptive modality selector dynamically adjusts the weights of different modalities to ensure that the features of each modality are learned in a balanced manner during training, even under data imbalance. MR-CSAF’s adaptive modality selector is able to dynamically adjust the attention between different product image and text modalities according to the current interaction context and user preferences. This dynamic adaptation mechanism enables MR-CSAF to adaptively optimize modal contributions in different scenarios, thus improving the accuracy and robustness of the recommendation system. The cross-self-attention fusion module propagates information between text and images, transferring information within each modality through the self-attention mechanism. Using this module, we can explicitly model the interactions between text, images, and interactions within modalities. These features are later propagated and aggregated across the user–item graph through a GNN. We performed experiments on three publicly available benchmark datasets. Our experimental results show that our model outperforms existing baseline approaches.
In summary, our main contributions include the following:
We propose a new recommendation algorithm called MR-CSAF. It leverages an adaptive modal selector and a cross-self-attention fusion mechanism that aims at accurately modeling both products and users.
We propose an adaptive modal selector that constructs a potential multimodal item relationship graph by dynamically adjusting modal weights, significantly enhancing the information fusion process in multimodal recommendation systems.
We designed a fusion module based on a cross-self-attention mechanism that explores intra- and inter-modal interactions, allowing for more comprehensive and efficient processing and fusion of multimodal information.
We evaluate MR-CSAF performance against several baseline approaches on three public benchmark datasets for multimodal recommendation, demonstrating superior performance compared to existing models.
The rest of this paper is organized as follows: A detailed description of our proposed model approach, MR-CSAF, is presented in
Section 2. We describes the dataset and our optimization process in
Section 3. In
Section 4, we conduct model-related experiments and analyze the results.
Section 5 provides a brief conclusion of this paper.
2. Proposed Method
As shown in
Figure 2, MR-CSAF uses Sentence2Vec [
32] and DeepCNN [
33] to extract features from texts and images, respectively, constructs a KNN modality-aware graph using original features for each modality m, and aggregates the modality-aware graphs using an adaptive modality selector. Next, the extracted feature information is fed into the cross-self-attention fusion module to learn the inter- and intra-modal interactions of text and images. Finally, the user-modal features are linked to the corresponding user-modal features and propagated through the user–item interaction graph to obtain the final feature representation. This representation is passed through another prediction layer tailored for downstream recommendation tasks.
2.1. Problem Definition
Let U denote the set of users and I denote the set of items. For any user , item , their corresponding modal embedding is denoted as in which d is the embedding dimension, and denotes the visual or textual modality.
Construct a heterogeneous user–item graph
, where the nodes are the union of all users and all products, i.e.,
, the set of edges represents the interaction between users and items, denoted by
, where each edge connects a user and an item. By using a matrix
based on user–item interactions, a symmetric adjacency matrix
expression can be obtained, as shown in Equation (
1):
In this matrix, if user u has interacted with item i; otherwise, .
2.2. Adaptive Modal Selector
Our adaptive modal selector constructs a perceptual graph
corresponding to each modal based on the initial features of each modality. Cosine similarity, denoted as
, is used to assess the similarity between two products, as shown in Equation (
2).
where and denote the features of item i and item j on modality m, respectively. For each product, we only keep their front edges that are similar, as shown in Equation (3):
We normalize the discrete adjacency matrix to , where , is the diagonal matrix of .
To solve the problem of multimodal information fusion, we design an adaptive modal selector that dynamically weights between different modalities
m to generate a comprehensive modal similarity matrix. Specifically, the image embedding
of the product is spliced with the text embedding
to form a joint feature representation. The modality selector module uses these common features to dynamically generate image and text modality weights for each product, as shown in Equation (
4).
Based on the spliced features, the modality selector module generates the modal weights through a two-layer fully connected neural network, as shown in
Figure 3, which ultimately generates a two-dimensional vector representing the weights of the image and text modalities of each product, respectively. Finally, the output is normalized by a softmax operation, as shown in Equation (
5).
where , is the learnable matrix, , is the bias term, is the ReLU activation function, and ensures that the outputs are modal weights, generating the corresponding image and text modal weights denoted as and .
The inter-product similarity graph
is constructed by aggregating the structure of each modality, as shown in Equation (
6):
Compared to traditional fixed-weight approaches, the adaptive modal selector dynamically generates modal weights in an adaptive and learnable manner, enabling more precise fusion of multimodal information and capturing complex inter-modal interactions more effectively.
We apply graph convolution on the inter-product similarity graph to facilitate information propagation and aggregation, as defined in Equation (
7):
where is the neighboring node of item i on graph S, and denotes the layer representation of the item, . We superimpose a convolutional layer a on graph S, and the last layer is denoted as .
2.3. Cross-Self-Attention Fusion Module
The cross-self-attention fusion module aims to use attention mechanism to propagate information between text and images and within each modality. Using the cross-self-attention module, we can model the intra-modal and inter-modal interactions of text and images. The cross-attention mechanism uses one modality to compute the distribution of attention, which is then used to guide the information flow on the other modality. Firstly, we define the query (Q), key (K) and value (V) in the cross-self-attention mechanism using Equations (8) and (9):
where , , , , , is the learnable weight matrix. We then use the dot product between query and key to reflect the correlation between different modalities. Next, we obtain the cross-attention weights by normalizing them with the softmax function, as shown in Equations (10) and (11):
Finally, we apply cross-attentional weights to value (V) to obtain a weighted output, as illustrated in Equations (12) and (13).
where , denote the propagation of information from image to text and text to image, respectively. Finally, we update the feature embedding of this modality with the propagation information of another modality, as shown in Equations (14) and (15).
We summarize the process of the cross-self-attention mechanism, as shown in Equations (16) and (17).
where denotes the information propagated within the modality m. Let and , denote the outputs of different modalities of the cross-attention layer and the self-attention layer, respectively. We fuse the acquired features of the self-attention mechanism with those of the cross-attention mechanism through the fully connected layer to obtain the corresponding item modal features , as shown in Equation (18).
where W is the learnable weight matrix, and b denotes bias.
To process the graph convolution operation on the user–item graph
G for information propagation and aggregation, we follow the approach adopted by FREEDOM [
10]. Firstly, user–item homomodal feature embeddings are spliced to form a tensor containing the homomodal feature embeddings, as shown in Equation (
19). Then a multi-layer graph convolution operation is performed using the adjacency matrix to update the embedding representation layer by layer. At each layer, we update the modal embedding by multiplying sparse matrices, as shown in Equation (
20).
where is the user feature embedding in modality m, n is the number of convolutional layers, and is the embedding in the n-th layer. After n layers of message passing, we obtain a sequence of embeddings . To synthesize information from different layers, we compute the mean using Equation (21):
Lastly, we split the obtained final embedding into a product embedding and user embedding, as shown in Equations (22) and (23).
2.4. Prediction Layer
Based on the modal feature data of the project obtained from
Section 2.2 and
Section 2.3, we adopt the feature summation approach to obtain the final modal representation of the item, as shown in Equation (
24).
Finally, the prediction score is expressed as the dot product of the user and product embeddings in the same modality, as shown in Equation (
25).
2.5. Loss Function
After obtaining the modal feature representations of all products and users, we use Bayesian personalized ranking (BPR) loss to optimize the interaction performance of the user and the item. Specifically, MR-CSAF computes the BPR loss for different modalities separately, as shown in Equation (
26). The BPR loss aims to make the difference between the scores of the positive samples and those of the negative samples as large as possible, and the data it is trained on triples
, in which user
u’s chooses product
i over product
j.
where D is the set of training examples and is the sigmoid function.
Moreover, MR-CSAF further transforms the original feature embeddings using a line projection layer, as shown in Equation (
27). This transformation allows the model to capture more complex interactions between user features and user preferences in modality
m. It serves as a regularization mechanism that ensures robust learning of the embeddings. We compute their BPR losses with user embeddings separately, as shown in Equation (
28).
where is the linear transformation matrix in modes m, and is the bias vector.
The final total loss, shown in Equation (
29), combines the BPR losses for the different modalities and the regularized losses for the features.
where the weight parameter is used to control the effect of feature transformation loss.
4. Results and Discussion
4.1. Overall Performance (RQ1)
We compare the effect of this model with the current mainstream eight baseline models under three datasets, as shown in
Table 3. Based on
Table 3, we make following observations:
1. Our experiments revealed key insights across three datasets. In the Garden dataset, which contains richer interaction data compared to the other datasets, MR-CSAF demonstrated improvements across all four evaluation metrics. These improvements can be attributed to the cross-self-attention fusion module’s ability to effectively capture both intra- and inter-modal interactions, leading to more accurate product modeling. The Baby dataset, despite its large scale of users and products, presents significant challenges due to its high sparsity. However, MR-CSAF successfully maintains its effectiveness by exploring modal interactions and accurately modeling information even with sparse data relationships. In the Sports dataset, which is the largest and also exhibits high sparsity, MR-CSAF’s adaptive modality selector and cross-attention mechanism prove particularly valuable. The adaptive modality selector dynamically adjusts modal weights to optimize the integration of image and text information, while the cross-attention mechanism enables effective multimodal fusion even under sparse data conditions, ultimately enhancing recommendation quality.
2. MR-CSAF outperformed all eight baseline models on NDCG@10, NDCG@20, Recall@10, and Recall@20 metrics. Our superior performance comes from following:
- (1)
Our proposed method effectively captures multimodal information by modeling product information in each dimension and propagating and aggregating it over the graph to accurately generate user modal embeddings.
- (2)
Our adaptive modal selector combines the distinct dimensional characteristics of various products and dynamically calculates weights for image and text modalities. This effectively adjusts the influence of each modality across different product recommendations, enabling adaptive adjustments within the product–product graph structure. This approach optimizes the alignment of modality contributions, enhancing the recommendation system’s flexibility and responsiveness to diverse product attributes.
- (3)
Our cross-self-awareness fusion module effectively captures both cross-modal and intra-modal interactions, enabling precise fusion and modeling of product attribute features alongside modality-specific features. This approach enhances the integration of diverse modality information for a more accurate representation of product attributes.
3. In modeling multimodal feature information, graph-based multimodal recommendation models outperform the traditional matrix decomposition model VBPR [
35]. This is primarily because our method can effectively capture complex relationships between users and items, enhancing contextual understanding through multimodal information. Furthermore, the graph structure better represents sparse data, improving recommendation accuracy, especially when handling high-dimensional features of users and items.
4. In graph-based multimodal recommendation models, GRCN [
26] performs better than MMGCN [
25], which is a result of GRCN capturing and utilizing users’ true preference information more effectively through graph structure optimization and targeted noise processing. SLMRec [
36] primarily learns product feature representations through self-supervised learning; however, its reliance on individual user embeddings to simulate user features across different modalities results in weaker performance. LATTICE [
30] achieves stronger results on the Garden dataset by explicitly modeling item relationships and leveraging negative samples to guide learning, which helps the model distinguish between positive and negative samples in smaller datasets. In contrast, BM3 [
37] employs a self-supervised learning framework that does not depend on negative samples, making it more robust in handling larger datasets. The multimodal recommendation approaches LATTICE [
30], FREEDOM [
10], and POWERec [
8], which all aim to enhance recommendation performance through graph structure optimization and multimodal data fusion. LATTICE [
8] builds latent graph structures by dynamically assigning weights to textual and graphical modalities, effectively capturing complex relationships between items, although it may encounter efficiency challenges with large datasets. FREEDOM, in contrast, improves model efficiency by freezing the graph structure, which reduces computational complexity and noise, albeit at the cost of reduced flexibility. POWERec [
8] utilizes cue learning and weak modality augmentation to efficiently model user preferences across modalities but requires extensive tuning for very large graphs, resulting in diminished performance on the Sports dataset due to its substantial data volume.
In contrast, the MR-CSAF method dynamically adjusts modal preferences across varying product dimensions based on feature information, allowing it to capture potential graph structures on the item–item graph more precisely. Additionally, MR-CSAF introduces a cross-self-attention mechanism to construct more accurate product feature representations and refines user modality feature representations by aggregating and propagating information within the user–item graph, achieving exceptional performance.
Table 3.
Comparison of MR-CSAF against baselines on model efficiency. Best results are presented in bold; second-best results are underlined.
Table 3.
Comparison of MR-CSAF against baselines on model efficiency. Best results are presented in bold; second-best results are underlined.
| Datasets | Metrics | VBPR | MMGCN | GRCN | SLMRec | LATTICE | BM3 | FREEDOM | POWERec | MR-CSAF |
|---|
| Garden | NDCG@10 | 0.0547 | 0.0655 | 0.0758 | 0.0747 | 0.0849 | 0.0835 | 0.0791 | 0.0748 | 0.0948 |
| NDCG@20 | 0.0709 | 0.0826 | 0.0945 | 0.0922 | 0.1022 | 0.1034 | 0.0961 | 0.0914 | 0.1136 |
| Recall@10 | 0.1030 | 0.1155 | 0.1361 | 0.1345 | 0.1571 | 0.1429 | 0.1376 | 0.1262 | 0.1637 |
| Recall@20 | 0.1651 | 0.1823 | 0.2090 | 0.2019 | 0.2242 | 0.2199 | 0.2026 | 0.1910 | 0.2379 |
| Baby | NDCG@10 | 0.0223 | 0.0220 | 0.0282 | 0.0285 | 0.0292 | 0.0301 | 0.0330 | 0.0311 | 0.0344 |
| NDCG@20 | 0.0284 | 0.0282 | 0.0358 | 0.0357 | 0.0370 | 0.0383 | 0.0424 | 0.0398 | 0.0444 |
| Recall@10 | 0.0423 | 0.0421 | 0.0532 | 0.0540 | 0.0547 | 0.0564 | 0.0627 | 0.0579 | 0.0641 |
| Recall@20 | 0.0663 | 0.0660 | 0.0824 | 0.0810 | 0.0850 | 0.0883 | 0.0992 | 0.0918 | 0.1033 |
| Sports | NDCG@10 | 0.0307 | 0.0209 | 0.0306 | 0.0374 | 0.0335 | 0.0355 | 0.0385 | 0.0300 | 0.0394 |
| NDCG@20 | 0.0384 | 0.0270 | 0.0389 | 0.0462 | 0.0421 | 0.0438 | 0.0481 | 0.0377 | 0.0498 |
| Recall@10 | 0.0558 | 0.0401 | 0.0559 | 0.0676 | 0.0620 | 0.0656 | 0.0617 | 0.0565 | 0.0734 |
| Recall@20 | 0.0856 | 0.0636 | 0.0877 | 0.1017 | 0.0953 | 0.0980 | 0.1089 | 0.0863 | 0.1130 |
4.2. Ablation Studies (RQ2)
In this section, we decouple the proposed model and evaluate the contribution of each component to the recommendation accuracy. We choose Recall@20 and NDCG@20 as metrics for the ablation experiments and validate them on three datasets, as shown in
Table 4. Based on the architecture of MR-CSAF, we designed the following variant of MR-CSAF:
Adaptive modal selector (AMS): AMS enhances the Ours model by incorporating adaptive modality selectors but does not utilize the cross-self-attention mechanism to manage embeddings.
Cross-Self-Attention Fusion (CSAF): CSAF learns interactions between different modalities. Within the same modality, it only uses the cross-self-attention fusion mechanism.
Table 4.
Ablation study on a different dataset.
Table 4.
Ablation study on a different dataset.
| Datasets | Modules | NDCG@20 | Recall@20 |
|---|
| Garden | AMS | 0.1128 | 0.2378 |
| CSAF | 0.1077 | 0.2256 |
| MR-CSAF | 0.1136 | 0.2379 |
| Baby | AMS | 0.0433 | 0.1014 |
| CSAF | 0.0435 | 0.1012 |
| MR-CSAF | 0.0444 | 0.1033 |
| Sports | AMS | 0.0496 | 0.1123 |
| CSAF | 0.0486 | 0.1106 |
| MR-CSAF | 0.0498 | 0.1130 |
The results demonstrate that our proposed MR-CSAF consistently outperforms both AMS and CSAF across all three datasets, indicating that both methods enhance the accuracy of model recommendations. Moreover, removing AMS significantly impacts recommendation performance more than removing CSAF in all cases across the datasets. In multimodal recommendation systems, different modalities contain rich and diverse information, making it essential to select and fuse these modalities effectively. In scenarios with sparse data, an adaptive modality selector optimizes information utilization, ensuring the model can still make accurate recommendations despite limited available data. By selectively concentrating on specific modalities, the adaptive modality selector helps alleviate performance degradation caused by imbalanced modal information. Additionally, the cross-self-attention fusion mechanism enhances feature representation by assigning varying weights to different features, enabling the model to prioritize critical information during decision making.
Although both CSAF and CAmgr employ cross-attention mechanisms (CAmgr-CAM), their approaches differ significantly. CSAF focuses on capturing both inter-modal interactions between products and intra-modal information transfers, propagating these refined representations through the user–product graph to enhance both user and product features. In contrast, CAmgr-CAM primarily optimizes the model using user feature information, processing user–item interactions to identify user interests and match them with product features. Our experimental results, shown in
Table 5, demonstrate CSAF’s superior ability to capture complex modal interactions and effectively propagate these refined representations through graph structures.
In cross-self-attention, all modalities interact with each other, which can introduce noise from irrelevant modalities. In contrast, the modality selector learns weights based on the specific product embedding, allowing it to assign lower weights to irrelevant modalities. This mechanism prevents noisy modalities from interfering with the decision-making process, thereby enhancing the accuracy of the recommendations.
4.3. Hyperparameter Study (RQ3)
In this subsection, we evaluate the following two key hyperparameters: the feature dimensions
defined in Equation (
5) and the weight parameters
defined in Equation (
29).
4.3.1. Impact of Hidden_dim Size in Adaptive Modal Selectors
When tuning the parameters of the adaptive modality selector, we experimentally set the hidden layer sizes
to candidate values of 8, 16, 32, 64, and 128. We then assessed their impact on Recall@20 and NDCG@20, as illustrated in the results of
Figure 4. Our findings indicate that a hidden layer size of 16 yields the best performance on the Garden, Baby and Sports datasets. Compared to other hidden layer dimension sizes,
may provide the model with the appropriate expressiveness to capture the complex inter-modal relationships in these three datasets more effectively, while avoiding the risk of overfitting associated with too high a dimension.
4.3.2. Effect of Feature Transformation Loss
We set the MR-CSAF feature transformation loss to the following values: 0.0, 1
, 1
, 1
, 1
, 1
. This was completed to investigate how this hyperparameter affects the model’s recommendation performance.
Figure 5 illustrates its impact on Recall@20 and NDCG@20 across three public datasets. Notably, the value of 1e-05 achieves the best performance on all datasets. However, increasing this value leads to a decline in performance. A larger loss may hinder the model’s ability to fully leverage useful features within the dataset. In this scenario, the contribution of the feature transformation loss
to the total loss function
becomes significantly larger, causing the model to concentrate excessively on feature transformation during training. This heightened focus can make the model more sensitive to noise and outliers in the original data. Conversely, a value that is too small may undermine the model’s generalization ability, resulting in poor performance on unseen test data.
5. Conclusions
In this paper, we propose MR-CSAF, an adaptive multimodal recommendation algorithm based on cross-attentional fusion. This algorithm significantly improves the accuracy of information fusion by introducing an adaptive modality selector, which dynamically constructs a multimodal item relationship graph. Additionally, it improves the relevance of recommendation results by capturing complex inter- and intra-modal interactions through the cross-self-attention mechanism, thereby boosting recommendation performance. MR-CSAF outperformed eight state-of-the-art methods across three public benchmark datasets, demonstrating its potential in multimodal recommendation systems.
However, the current implementation of MR-CSAF is slow to train due to the increased number of parameters, resulting from the adaptive modality selector. In a future study, we plan to explore techniques that can reduce the number of parameters in the selector, such as model compression, model distillation, and lightweight self-attention mechanisms. Furthermore, we plan to investigate our model’s generalization performance on larger and more diverse datasets to further enhance the applicability of MR-CSAF in practical scenarios.