1. Introduction
Storage as service [
1,
2,
3] allows for consumption-based storage facilities to store and process massive amounts of data through cloud storage. Cloud storage relieves clients of the burden of storage management [
4], simplifying data maintenance and management and reducing reliance on specialized IT personnel. Additionally, cloud storage facilitates universal data access across independent geographical locations, enabling users to easily access and share data regardless of their location. Moreover, cloud storage eliminates the substantial costs associated with purchasing hardware, software, and personnel maintenance [
5], providing a cost-effective solution that significantly reduces the total cost of ownership, enhancing operational efficiency and competitiveness for enterprises. However, cloud service providers are not entirely trustworthy, and clients need to ensure that their data stored on the servers are not subject to integrity or other security threats [
6,
7,
8]. Therefore, effective mechanisms are needed to ensure data integrity in cloud storage. Integrity auditing technology is considered an effective means for clients to verify the correctness of data stored in the cloud. In 2007, Ateniese et al. [
9] proposed Provable Data Possession (PDP), and Jules and Kaliski [
10] introduced Proofs of Retrievability (PORs). Both methods provide clients with guarantees of the integrity and availability of outsourced data. Subsequently, more and more experts began researching how to ensure data integrity for clients in cloud storage. In schemes where clients interact with cloud storage servers [
11,
12], only the original data are stored, making it difficult to recover in case of damage to the original data. However, in multi-replica storage, any damaged data can be correctly recovered using other replicas [
13,
14,
15], refs. [
16,
17,
18], which has been widely applied in industries such as finance, education, and healthcare, where data availability is critical.
However, in multi-replica schemes, servers may still engage in fraudulent behavior, i.e., not actually storing all data replicas. This lack of assurance regarding the genuine storage of data replicas not only leads to the inability to recover damaged data but also significantly undermines the integrity and availability of the stored data, which is especially critical in industries involving key business operations. Therefore, there is an urgent need for a genuine replica sampling mechanism that can resist server fraud to ensure data security and availability, protecting user interests and trust. Moreover, we specifically define server fraud as outsourcing attacks and generation attacks [
19].
In an outsourcing attack, a malicious server attempts to deceive the verifier into passing the audit. During the integrity audit challenge, the malicious server, upon receiving a challenge from the verifier, quickly retrieves the corresponding data from another storage provider and generates the proof. The malicious server appears to be storing the data continuously but, in reality, it does not bear the responsibility of storing it. This behavior allows the malicious server to deceive the client not only about the physical space allocated to the data but also about its storage capacity, even claiming to store data beyond its limit. This behavior not only affects data reliability but also imposes significant economic losses and risks of data leakage for the client. Furthermore, since the data retrieved from external storage lack security guarantees, the overall security of the data are greatly compromised, increasing the risk of data leakage and loss, further exacerbating the trust crisis.
Secondly, in a generation attack, the malicious server uses certain algorithms or predefined methods to quickly and dynamically generate replicas and produce proofs during a challenge without actually storing real data. This allows the malicious server to deceive the client, reducing the actual storage space required, thus saving costs, but posing a serious threat to data security. Therefore, to enhance data integrity and availability, effective mechanisms must be developed to defend against these fraudulent behaviors and maintain user trust and interests.
In data integrity auditing schemes, the client and the server, as two interacting entities, have different evaluation criteria to consider from their respective perspectives [
15,
20,
21]. Existing schemes often focus on different evaluation criteria, attempting to make the scheme more favorable to either the server or the client. However, considering only one party’s evaluation criteria will lead to an imbalanced scheme. Therefore, it is necessary to trade off between the client and the server, meaning that the scheme must consider how to meet the evaluation criteria of both parties. Armknecht et al. proposed a Mirror algorithm [
22], which shifts the replica generation process to the server, reducing the client’s computational burden and significantly saving bandwidth resources. At the same time, the server also benefits from reduced communication transmission, saving bandwidth resources. Additionally, although the server regains the initiative in replication, it is almost impossible for it to engage in improper behavior. This scheme is client-friendly while imposing as little burden as possible on the server. However, this trade-off still faces the issue of linear storage cost increase with the number of replicas when the client generates and uploads copy parameters. Moreover, it does not meet the criteria for public verifiability compared to other schemes. In 2023, the user-friendly scheme [
23] satisfies the public verifiability feature of client generation and uploading of copy parameters under a single cloud server, where the generation and uploading of copy parameters remain constant as the number of copies increases and the copy parameters are recoverable.
Although the aforementioned schemes are excellent, they have some obvious limitations. First, these schemes typically rely on a single-cloud storage environment, making the system vulnerable to single points of failure. If the cloud provider experiences an outage, data may become inaccessible or be permanently lost. Second, in a single-cloud environment, the tasks of replica generation [
13,
19] and storage are all handled by a single server, which not only increases the computational and storage burden but can also lead to performance bottlenecks when dealing with large-scale data. Furthermore, single-cloud schemes are less capable of defending against outsourcing attacks and generation attacks, where a malicious server can deceive the verifier by using external resources or dynamically generating replicas. In contrast, a multi-cloud environment distributes storage and processing tasks, improving the system’s security and stability while also reducing verification overhead. Lastly, the public verifiability of single-cloud schemes is limited; the verifier must rely on a single cloud service provider, lacking the transparency of multi-party collaboration. Multi-cloud storage, however, can enhance the reliability of the audit process through collaboration among different cloud providers. Unfortunately, the above schemes have not been implemented in a multi-cloud environment, and both public verifiability and constant-level copy parameter construction will be called into question.
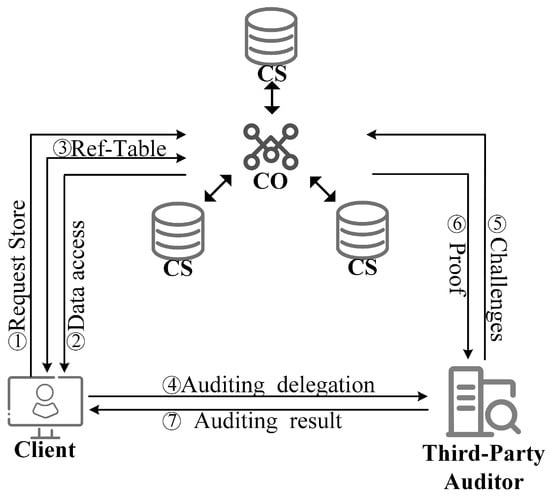
To address the aforementioned challenges, we propose a public authentic-replica sampling mechanism. This mechanism is a security sampling scheme designed to tackle data integrity and availability issues in a multi-cloud storage environment. Our primary goal is to ensure that the data replicas stored on cloud servers genuinely exist and have not been tampered with, thus maintaining the integrity and availability of the data. To achieve this goal, we designed an auditing method based on time-lock puzzles, succinct proofs, and identity-based encryption to ensure the authenticity of replicas. Additionally, recoverable copy parameters are employed, allowing any third party to verify the data, achieving public verifiability. Based on this sampling mechanism, we have instantiated a public authentic-replica sampling scheme. During the designated replica generation process, by utilizing a Ref-Table and random seeds, we achieve the distributed storage of data replicas across multiple clouds with negligible overhead while also reducing the burden on the client. The overall design cleverly allows for proof aggregation, further reducing verification overhead, resulting in a scheme that is both efficient and secure. The main contributions can be summarized as follows:
To address the issue of servers falsely storing replica data, this paper designs an authentic-replica sampling mechanism that periodically checks the server’s replica storage. We formally define the security model for the authentic-replica sampling mechanism and design a publicly verifiable authentic-replica sampling scheme for distributed storage environments. Our scheme distributes data replicas across multiple clouds, ensuring low verification overhead while distributing the pressure of replica generation. Through security analysis, we demonstrate the security of this scheme, ensuring that the replicas stored on the server occupy actual storage space.
This scheme is based on time-lock puzzles and employs identity-based encryption mechanisms and succinct proof techniques to ensure the authentic replica. It is designed to resist generation attacks and outsourcing attacks, avoiding the associated security threats.
To address the issue of linear storage cost increase when the client generates and uploads copy parameters as the number of replicas increases, this paper combines random seeds and reference tables. This approach ensures that even as the number of stored replicas grows, the cost for the client to generate and upload copy parameters remains constant, which greatly reduces the computational overhead on the client side. Additionally, by using publicly recoverable copy parameters, the scheme achieves public verifiability. Security analysis demonstrates the scheme’s security.
We organize our paper as follows: We review the preliminaries required in our paper in
Section 2. The system model and security model of the public authentic-replica sampling mechanism are described in
Section 3. In
Section 4, we give the detailed construction of the public authentic-replica sampling scheme and the security analysis. We give the performance of our scheme in
Section 5, and finally the conclusion is in
Section 6.
Related Work
Distributed storage systems combine network and storage technologies to allow clients to store data remotely and provide various services such as archiving, publishing, federation, and anonymity. As networking technology has evolved, new types of distributed storage systems have emerged [
24]. These systems can be categorized into two main types of architectures: client–server and peer-to-peer. In a client–server architecture [
25], each entity is either a client or a server with the server responsible for authentication, data replication, backup, and handling client requests. This architecture is commonly used in distributed storage systems. In contrast, in a peer-to-peer architecture [
25,
26], each participant can be both a client and a server.
In distributed storage systems [
27,
28,
29,
30], storing data is essentially a data outsourcing problem for the client. Consequently, ensuring the integrity of the data that has been outsourced is of critical importance in terms of security in order to ensure the integrity of outsourced data on cloud servers, Ateniese [
9] et al. proposed the Provable Data Possession (PDP) concept and constructed the PDP scheme, which serves the purpose of verifying the integrity of remote data by checking whether the server has certain blocks through Homomorphic Verifiable Tag (HVT) in the form of probability-based sampling. Secure PDP (S-PDP) is the first sampling mechanism-based PDP, which strongly guarantees the possession of data with its added robustness but at the cost of huge computation on the client side. For this reason, Efficient PDP (E-PDP) [
31] has been proposed again, which is used to reduce the computation on the client side, but they all suffer from high communication cost and a linear relationship between the client’s computation and the replica. In 2013, Hanser and Slamanig provided a PDP based on the elliptic curve cryptosystem [
32], which enables the same tag to be verified both publicly and privately by identifying the vectors of each data block, which in turn achieves the public verifiability of the scheme, enabling the client and third party to audit the data remotely at the same time. In 2013, Chen proposed algebraic signatures to effectively check data possession in cloud storage [
33]. Algebraic signatures have less computational overhead than homomorphic cryptosystems, which makes the scheme guarantee data possession while reducing the overhead, but it suffers from an upper limit on the number of verifications and relies on probabilistic guarantees. Compared to PDP, Juels and Kaliski [
10] proposed the Proofs of Retrievability (PoRs), which is a form of encrypted Proof of Knowledge (PoK) that ensures the integrity of outsourced data in untrusted cloud storage while also enabling the recoverability of slightly damaged data through the use of Forward Error-correcting Codes (FECs), but it has the limitation of having an upper limit on the number of verifications. Subsequently, Shacham and Waters achieved data retrievability through coding techniques in 2008 [
34], and through homomorphic authenticators, they achieved an infinite number of integrity verifications. In 2013, Yuan and Yu designed a new PoR scheme, which generates polynomials with short strings as a constant-size polynomial commitment technique through the use of constant-size polynomials as a proof, which makes the scheme have a communication cost of constant magnitude. Subsequently, more and more researchers have devoted themselves to this topic and produced a large number of research results.
However, even PoR schemes that can have a weak recovery capability can only repair minor damage. If the source data are damaged to a greater extent, the data will not be recovered, and at the same time, data retrievability will be damaged at the same time. In order to make up for this shortcoming, many researchers have begun to focus on replica storage. Replica [
35] is used to ensure data availabilit. Basic principles are used in the server to store different replicas, so that even if the data and more than one replica are corrupted, the remaining complete replica can restore the damaged data, to a large extent, to ensure the availability of data. In the specific scheme to realize multiple replicas, the first thing that researchers think of is to make the replicas directly become additional copies of data. This approach is simpler to implement, but it does not provide strong proof that the server is actually storing multiple copies; the server can be challenged without the client submitting a sufficient number of copies, and it will create copies when challenged, which in turn achieves the effect of spoofing. Thus, the copies that the client expects the server to store become difficult to prove. These schemes also do not guarantee the authenticity, integrity, and availability of the data copies on the server. In 2008, Curtmola et al. made the first attempt at Multiple-Replica Provable Data Possession (MR-PDP) [
36], in which the client is able to securely confirm that the server stores multiple unique replicas. In addition, because multiple replicas can be checked in a batch, the overhead of verifying n replicas is less than that of verifying one replica n times. It succeeds in securely networking [
37] and storing multiple replicas to create uniquely distinguishable copies of data, but MR-PDP only supports private authentication. In 2009, Bowers et al. proposed a new cloud storage scheme that is based on PoR and utilizes both within-server redundancy and cross-server redundancy, allowing for the testing and reallocation of storage resources when failures are detected. In 2010, Barsoum and Hasan proposed another scheme [
36]. There are two versions: one is at the cost of higher storage overhead on the client and server, and the other one is with probabilistic detection to reduce client and server overhead. This scheme is able to delegate the auditing task to a trusted third party using a BLS homomorphic linear authenticator, but the client must re-encrypt and upload the entire copy to the server. Subsequently, multi-copy integrity auditing on dynamic data updates was also proposed. In 2014, Barsoum and Hasan proposed a scheme [
38], which supports multi-copy storage in addition to the dynamic operations on the number of outsourcing.
In 2016, Armknecht et al. proposed the Mirror scheme [
22], which is based on the difficult problem of Linear Feedback Shift Registers (LFSRs) with Rivest, where mirroring shifts the overhead of building replicas to the cloud servers, which makes the cloud servers reduce the bandwidth overhead. Subsequently, Guo et al. improved on Mirror [
39] in order to resist the replacement forgery attacks caused by the extensibility of data labels. These schemes reduce the computation of the client and make the replica generation part realized by the server; however, these schemes still have the problem that the client has a linear relationship with the copy parameters, and the client still has a relatively large amount of computation. At the same time, compared with the previous schemes, it cannot satisfy the public verifiability characteristic. In 2023, the user-friendly scheme [
23] satisfies the public verifiability feature of client generation and uploading of copy parameters under a single cloud server, where the generation and uploading of copy parameters remain constant as the number of copies increases and the copy parameters are recoverable. However, if all cloud servers store one more layer of copy parameter generation in a multi-cloud environment, in this environment, the constant and copy parameter generation cannot be satisfied, and the public verifiability characteristic will be questioned. None of the existing integrity auditing schemes can resist the two attacks: the generation attack and the outsourcing attack.
Although existing schemes have made significant efforts in ensuring data integrity and availability, most are confined to single-cloud environments. In a multi-cloud environment, these schemes fail to guarantee client-friendliness and cannot achieve public verifiability. Verification is limited to a single cloud, and whether efficient verification can be achieved in a multi-cloud setting remains uncertain. In contrast, the scheme proposed in this paper overcomes these limitations. By adopting techniques such as time-lock puzzles, succinct proofs, and identity-based encryption, it ensures the authenticity and security of replicas, effectively resisting outsourcing attacks and generation attacks. In a multi-cloud environment, our scheme significantly reduces the overhead of replica generation by combining Ref-Table and random seeds. Additionally, it introduces public verifiability in the replica verification process, greatly enhancing the security and efficiency of the system.