
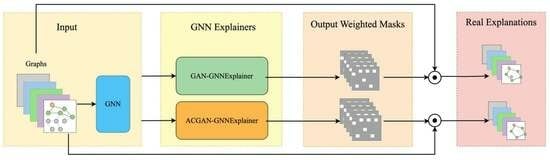
4.1. Experimental Settings
The BA-Shapes dataset comprises a Barabasi–Albert (BA) graph with 300 nodes. It incorporates 80 “house”-structured network motifs randomly attached to nodes within the base graph. Nodes are classified into four categories based on their structural roles: those at the top, middle, and bottom of houses and those not part of any house.
The Tree-Cycles dataset originates from an initial eight-level balanced binary tree. It incorporates 80 six-node cycle motifs attached randomly to nodes within the base graph. Nodes are divided into two classes based on whether they belong to the tree or the cycle.
The Mutagenicity datasets consist of 4337 molecule graphs representing atoms as nodes and chemical bonds as edges. These graphs are categorised into two classes, nonmutagenic and mutagenic, indicating their effects on the Gram-negative bacterium Salmonella Typhimurium. Specifically, carbon rings containing or groups are known to be mutagenic. However, carbon rings are present in both mutagenic and nonmutagenic graphs, rendering them nondiscriminative.
NCI1 is a curated subset of chemical compounds evaluated for their efficacy against non-small-cell lung cancer. It encompasses over 4000 compounds, each tagged with a class label indicating positive or negative activity. Each compound is depicted as an undirected graph, with nodes representing atoms, edges denoting chemical bonds, and node labels indicating atom types.
Different top edges (K or R). After calculating the importance (or weight) of each edge in the input graph G, selecting an appropriate number of edges for the explanation is crucial. Choosing too few edges may result in incomplete explanations, while selecting too many can introduce noise. To address this, we define a top K for synthetic datasets and a top ratio (R) for real-world datasets to determine the number of edges to include in the explanation. We evaluate the stability of our method by experimenting with different values of K and R. Specifically, we use for the BA-Shapes dataset, for the Tree-Cycles dataset, and for the real-world datasets.
Data split. To ensure consistency and fairness in our experiments, we split the data into three subsets: 80% for training, 10% for validation, and 10% for testing. The testing data are kept completely separate and unused until the final evaluation stage.
where G represents the original graph requiring explanation and refers to its corresponding explanation (such as the significant subgraph). The term denotes the number of instances where the predictions of the target GNN model f on both G and are identical, while is the total number of instances.
where N represents the total number of samples and denotes the class label for instance i. The terms and refer to the prediction probabilities for class based on the original graph and the occluded graph , respectively. The occluded graph is created by removing the important features (explanations) identified by the explainers from the original graph. A higher value is preferred, indicating a more critical explanation. On the other hand, refers to the prediction probability for class using the explanation graph , which contains the crucial structures identified by the explainers. A lower value is desirable as it reflects a more complete and sufficient explanation.
In summary, the accuracy of the explanation () evaluates how well the generated explanations reflect the model’s predictions, while and measure the necessity and sufficiency of these explanations, respectively. By comparing the accuracy and fidelity metrics across different explainers, we can gain meaningful insights into the effectiveness and suitability of each method.
Source link
Yiqiao Li www.mdpi.com

