1. Introduction
In contemporary industrial intelligence and automation, welding technology plays a crucial role in modern manufacturing processes, with a continuous increase in product demand [
1]. However, the predominant use of manual welding in existing welding products poses challenges in ensuring product consistency, quality, and efficiency, as it is impacted by the technical expertise and physical condition of workers. The development and application of robot technology [
2] have partially mitigated the limitations of manual welding. Robots can execute repetitive welding tasks based on programmed trajectories, thereby enhancing the quality and efficiency of welding operations. Despite the programmed trajectory approach of a single welding robot, deviations in the welding product’s position due to clamping errors and thermal deformation during welding may lead to quality issues such as welding deviations and incomplete welds. To address this challenge, sensor technology is integrated with robots [
3,
4,
5], enabling them to acquire external welding data. By collecting the welding point’s position, the robot can adjust its teaching trajectory, ensuring accurate weld tracking and maintaining welding quality.
1.1. Detecting Element
The crucial role of a high-performance detection element in the seam tracking control system cannot be overstated. In current seam tracking applications, various types of sensors are employed, such as the magnetron arc sensor [
6], ultrasonic sensors [
7], and visual sensors [
8]. With the continuous developments in electronic technology, vision sensors have emerged as capable of gathering more precise data and exhibiting superior resistance to interference as well as enhanced stability. Vision sensors commonly fall into two categories: passive vision sensors [
9] and active vision sensors [
10,
11], based on the utilization of auxiliary light sources. During welding processes, significant noise sources such as arcs, splashes, and smoke are prevalent. Passive vision sensors directly capture image data from the welding area, which often contains substantial noise that can impede image processing. Active vision sensors, leveraging intense and monochromatic laser or structured light, are favored for their ability to mitigate noise interference and are thus widely adopted in practice.
1.2. Image Feature Point Extraction Algorithm
For seam tracking utilizing a vision sensor, a fundamental challenge lies in promptly acquiring the positional data of image seam feature points amidst significant noise interference [
12]. In the initial stages of image processing, conventional methods were employed to extract and pinpoint the weld feature points. Typically, the algorithmic procedure involves utilizing image filtering techniques to eliminate noise, focusing on the region of interest to mitigate algorithmic complexity, employing morphological operations to enhance the weld edge image, extracting the weld line, and determining the positional data of the weld image feature points based on the weld type [
13,
14,
15,
16]. Traditional image processing approaches conventionally operate on images prior to welding to ascertain the weld’s positional information. However, during the welding process, images are often inundated with noise, posing challenges in obtaining accurate positional data of the image feature points.
To enhance the accuracy of weld position detection for real-time welding, numerous researchers have examined weld video images. They have introduced target visual tracking algorithms in computer vision based on the observation that the variation between consecutive frames of the weld image is minimal. These algorithms are designed to extract weld position information. Zou et al. [
17] utilized traditional morphological techniques to identify feature points and define the tracking area pre-welding. They employed a spatio-temporal context (STC) algorithm to track feature points that are susceptible to arc and splash interference during welding. Yu et al. [
18] proposed a method for feature point recognition that combines morphological extraction and kernel correlation filtering (KCF) tracking to extract feature points in the presence of significant noise. Shao et al. [
19] developed an algorithm based on particle filtering and conventional image processing to track feature points in weld images under conditions of poor image quality. Experimental results indicate a detection accuracy of 0.08 mm when welding narrow butt joints with a width of 0.1 mm. Fan et al. [
20] introduced a technique for gathering weld feature points using efficient convolution operator (ECO) and particle filter (PF), suitable for collecting image feature points of various weld types under high noise levels. While the target tracking algorithm enhances welding precision, issues such as target frame disappearance or distortion arise when the image solder joint is obstructed. These challenges reduce the system’s robustness, necessitating manual supervision.
The integration of deep learning technology into seam tracking technology has been facilitated by its rapid development. Deep learning networks are known for their exceptional feature extraction and learning capabilities, enabling the extraction of weld position information even in the presence of significant noise. Currently, two commonly utilized networks are the semantic segmentation network and the target detection network. The former categorizes each pixel in the image into different classes to eliminate noise. Xiao et al. [
21] developed a weld target detection model using a faster-region-based convolutional neural network (RCNN) to identify weld types and detect weld feature areas, thereby enhancing the adaptability and robustness of the weld detection algorithm. Yang et al. [
22] leveraged the contextual features of a deep convolutional neural network (DCNN) to propose a novel method for weld image denoising, facilitating automatic laser stripe extraction for applications such as intelligent robot welding, weld tracking, and weld type detection. Song et al. [
23] introduced a lightweight detector, Light-YOLO-Welding, based on an enhanced version of YOLOv4, which effectively detects welding feature points with improved accuracy and speed. Furthermore, Gao et al. [
24] proposed a feature point detection network, YOLO-Weld, based on an enhanced version of YOLOv5, enhancing the model’s robustness in highly noisy environments.
In conclusion, conventional image processing techniques are capable of extracting feature points from weld images given high-quality images. However, they are not suitable for real-time weld tracking. Computer vision-based tracking algorithms experience changes in tracking position when the feature points of the weld image are obstructed, leading to a compromise in welding accuracy. The utilization of deep learning technology can guarantee effective real-time tracking and mitigate the impact of significant noise interference.
Weld tracking algorithms leveraging deep learning technology can be categorized into two primary approaches: One utilizes semantic segmentation combined with traditional image processing techniques to mitigate noise, though this may result in missed detections and multiple detections. The other approach employs target detection algorithms directly; however, its accuracy can be compromised by the algorithm’s anti-jamming capabilities. To address these challenges, this study proposes a feature point extraction algorithm for seam tracking images that integrates the superior noise reduction capabilities of semantic segmentation with the precise feature point extraction abilities of target detection. The proposed algorithm offers two significant contributions:
- (1)
This approach amalgamates the robust noise reduction capabilities of semantic segmentation algorithms with the precise feature point extraction capabilities of target detection algorithms. This integration effectively mitigates the impact of strong noise on weld image feature points during the welding process, thereby reducing the missed detection rate of feature points and ensuring the accuracy of weld tracking image extraction.
- (2)
Addressing the limitations of the classical Deeplabv3+ algorithm in welding scene semantic segmentation, this method adopts the lightweight MobileNetV2 network to facilitate the deployment in welding environments. Additionally, the DenseASPP module and attention mechanisms are employed to focus on the edge information of laser stripes, thereby enhancing the model’s expressive capability.
The structure of the rest of this paper is as follows.
Section 2 presents the design of the weld tracking system, followed by the introduction of the designed algorithm for extracting weld feature points in
Section 3.
Section 4 focuses on training the algorithm model and analyzing the training results. Subsequently,
Section 5 validates the accuracy of extracting weld feature points on the experimental platform, and
Section 6 provides the conclusion.
2. Weld Tracking System
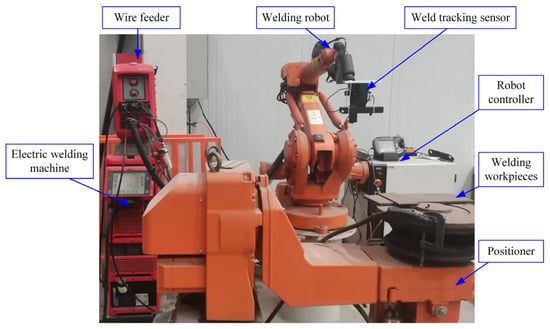
The experimental platform developed in this study is depicted in
Figure 1. It comprises a welding robot system, an image processing system, and associated equipment.
A comprehensive testing platform comprises an image processing system and a welding robot system. The image processing system is composed of a weld tracking sensor and an image algorithm processing system. The weld tracking sensor is positioned at the forefront of the robot welding gun to capture laser stripe image data. The image algorithm processing system utilizes a predefined algorithm to extract feature point coordinates from the laser stripe image, which are then transmitted to the welding robot system following coordinate conversion. The welding robot system employs the robot as the primary tool for execution, carrying out automatic welding tasks based on the actual welding point coordinates provided by the image processing system. The associated equipment includes the welding gun, welding power supply, wire feeder, and other supplementary devices, which regulate welding process parameters and collaborate with the robot during welding operations.
- (1)
Welding noise
During the welding process, the images captured by the camera are impacted by the presence of noise in the welding environment, which is characterized by high levels of interference.
Image noise comprises arc light, diffuse reflection, and smoke. In
Figure 2, the arc manifests as a linear segment resembling a laser stripe in the image. Diffuse reflection is depicted as a prominent section of the laser stripe in the image, surrounded by numerous bright spots. However, welding dust is generated through the processes of evaporation, gasification, and annihilation of welding materials and the surrounding environment during welding, resulting in an irregular shape in the image.
Arc and diffuse reflections, resembling laser stripes, have the potential to obscure the welding area and intensify a specific laser stripe, significantly impacting image processing. Conversely, smoke noise merely causes image blurring without altering the brightness of the image, making it distinguishable from the laser stripe image and thus amenable to processing by image algorithms.
- (2)
Image welding feature points
As defined in classic computer vision, a feature point is an important and unique point and feature that contains the most relevant information in an image, intuitively representing its characteristics. In weld seam images, the combination of laser irradiation and camera image acquisition results in different feature sets, depending on the splicing methods used. This analysis focuses on four typical types of welds: fillet, butt, lap, and bevel welds. Unlike the actual welding trajectory, weld seam tracking sensors are employed to collect images of the weld seams.
In the welding process, welding products are categorized into fillet welding, butt welding, lap welding, and groove welding based on the different steel splicing techniques employed.
Figure 3 illustrates the laser image and feature point position data collected, which differ from the actual weld type.
In
Figure 3a, the laser is directed towards the surface of the fillet weld, depicted as two intersecting straight lines in the image. The point of intersection of these lines corresponds to the location of the welding feature point within the image. However, for butt joints, lap joints, and groove welds, the welding positions cannot be directly determined but can be inferred through the spatial relationship of multiple image feature points. While existing image processing algorithms for feature points are tailored to weld characteristics, the proposed algorithm lacks versatility across different weld types and is susceptible to variations in image quality. Consequently, this limitation may lead to issues such as incomplete inspections and redundant assessments, ultimately compromising the quality of welding processes.
Taking
Figure 3a as an example, laser stripe irradiation on various types of weld surfaces produces distinct shapes, with the weld points displayed in the image as an identifiable feature. For instance, in the case of an angular splicing weld seam, when a linear laser irradiates the surface, two intersecting lines appear in the image, and the intersection point of these two lines serves as the position point of the weld seam. This point is marked with a red cross in the figure, while the other three types of welding points can also be represented as feature points. When the camera captures the pixel coordinate information of the intersection point (“feature point”) of two straight lines, this information undergoes coordinate transformation, enabling conversion into spatial position information, thereby achieving the tracking of the weld seam. The process is similar for the other types of weld seams, and different welding seam splicing methods obtain different image information through laser irradiation and camera acquisition, each with unique image features or points that represent the position information of the welding image.
From the analysis of the shape characteristics of the weld seam images, it is evident that the image feature points differ significantly among weld types. Unlike the butt weld seam, where three laser stripe lines are distributed parallelly, the feature points of the corner, lap, and groove weld seams are represented by the intersection points of two or more laser stripe lines. Based on these characteristics, the feature points of the four typical weld seam types can be categorized into two groups: parallel and intersecting. Intersecting welds include fillet, lap, and bevel welds, while parallel welds comprise butt welds.
The analysis reveals that acquiring weld position information from a noise-free laser stripe image is simple. However, during the welding process, the captured images are often contaminated with significant noise. The image welding feature point extraction algorithm, developed based on traditional image processing methods, is tailored to a specific weld type, limiting the algorithm’s versatility and resilience. Therefore, the primary concern of the seam tracking image processing algorithm is determining the position information of diverse image welding feature points amidst substantial noise interference.
3. Research on Feature Point Extraction Algorithms for Weld Images
The extraction of weld seam position information critically depends on identifying the pixel coordinates of image feature points within the weld seam. To achieve a noise-free laser stripe image, a series of image processing tasks are performed, including image preprocessing, laser stripe centerline extraction, and feature point extraction. The process for extracting these image feature points is illustrated in
Figure 4.
3.1. Improved Image Denoising Algorithm of DeeplabV3+
3.1.1. Deeplapv3+ Network Architecture
In the context of extracting weld seam feature points, the primary challenge is obtaining accurate position information on these points amidst strong noise environments. It is necessary to obtain clean laser stripe image information. However, in real-world working conditions, the required information in weld seam images pertains to pixel-level edge details. While YOLO and SSD perform well in object detection within image segmentation, their functionality is generally confined to bounding box localization rather than pixel-level segmentation, making them suboptimal for weld feature point extraction. Conversely, DeepLab demonstrates excellent performance in semantic segmentation tasks, especially in maintaining spatial resolution against complex backgrounds.
DeeplabV3+ represents the most advanced model in the DeepLab series for semantic segmentation, as noted in reference [
25]. It boasts high segmentation accuracy and rapid prediction capabilities, suitable for end-to-end image segmentation tasks. Despite the relatively simple surface features of welding, DeepLab’s utilization of dilated convolutions allows for an enhanced capture of local details, significantly benefiting subsequent processing stages. The incorporation of conditional random fields during post-processing aims to refine segmentation accuracy. This approach effectively reduces minor noise interferences and enhances edge smoothness, thereby elevating the overall quality of segmentation. The model architecture is bifurcated into encoder and decoder segments: the encoder is tasked with feature extraction and encoding of the input image, while the decoder facilitates the retrieval of the prediction outcome. The network model is depicted in
Figure 5.
Though DeepLabv3+ demonstrates strong performance on semantic segmentation datasets, the network model exhibits several limitations when applied to welding scenes. (1) The model’s parameters are extensive, hindering its practical deployment in welding scenarios. (2) The utilization of feature information is limited to the concatenation of shallow and deep features during encoding and decoding processes. (3) The decoder’s design is overly simplistic, employing direct upsampling methods that impede the accurate recovery of detailed information.
3.1.2. DV3p-Weld Network Model
In response to the scarcity of model networks in welding scenarios, a method for enhancing the DeepLabv3+ model has been proposed. The key enhancements include the following: (1) Substituting the original Xception network with MobileNetV2 as the backbone network. (2) Replacing the ASPP module with DenseASPP. (3) Integrating CoordAttention (CA) and cSE modules into the attention mechanism.
Based on the Deeplabv3+ network, three enhanced modules have been developed and applied in seam tracking, collectively referred to as DV3p-Weld model (Deeplabv3+, Weld, DV3p-Weld). The architecture of DV3P-Weld network model includes MobileNetV2, the DenseASPP module, as well as the cSE and CA modules in the attention mechanism.
The DV3p-Weld network model maintains both the encoder and decoder components (
Figure 6).
The coding process involves the extraction and encoding of features from the input image. Through the MobileNetV2 network, the features are down-sampled multiple times to obtain feature layers at different levels. The final level’s feature map incorporates a CA mechanism to focus on crucial areas, which is then transmitted to the DenseASPP module. Within the DenseASPP module, dense connections are established between feature maps of varying resolutions. Different expansion convolutions, in combination with the squeeze-and-excitation pooling (SP) method, are employed to extract features, resulting in a feature layer with enhanced semantic information.
The decoding process involves upsampling the feature layer containing higher semantic information obtained from the encoding process. This layer is then concatenated with the third feature layer using the output of a 1 × 1 convolution operation for upsampling. The cSE channel attention module is employed to improve the inter-channel relationships and is combined with shallow features to predict image results that match the input image size. This process helps to visualize the pixel categories of the input image and achieve image segmentation.
3.1.3. MobileNetV2 Network
Compared with the classical segmentation task, the laser stripe segmentation task is considered simpler for two primary reasons. (1) The laser stripe segmentation task involves a reduced number of segmentation types, specifically five types of laser stripes: background, corner joint, butt joint, lap joint, and groove. This is simpler when compared to the hundreds of segmentation types present in classical segmentation tasks (2) Each picture in the laser stripe segmentation task only requires two types of segmentation: background and laser stripe.
In the welding process, rapid acquisition of position information for welding feature points is essential for adjusting the robot’s pose. Therefore, a model with high efficiency and accuracy is required for this task. Xception, the backbone network of the original DeepLabv3+ network, contains a higher number of parameters, impacting prediction efficiency and posing challenges for industrial welding applications.
To address this issue, the lightweight network MobileNetV2 [
26] is proposed as a replacement for the original network Xception. MobileNetV2 utilizes deep separable convolution and an inverse residual module, resulting in a reduction in model parameters and overall model size compared to Xception. These characteristics make MobileNetV2 well suited for welding environments.
3.1.4. Pyramid Pool of Densely Connected Cavity Space
The DenseASPP neural network structure for image semantic segmentation [
27] (
Figure 7) integrates the DenseASPP mechanism, DenseASPP module, and SP bar-shaped ASPP module [
28]. It incorporates Dense ASPP between feature maps of varying resolutions to enable the interaction and transmission of features across different levels. Additionally, the original ASPP model is maintained in dense connection, utilizing hole convolution with diverse sizes at each level to capture both local and global information. To mitigate the parameter increase resulting from multiple concatenation convolutions, the inverse residual convolution is introduced as a replacement for the original ordinary convolution, thereby reducing the network’s parameter count.
3.1.5. Attention Mechanism
The attributes of various channels vary significantly. Certain channels may contain a higher amount of valuable information compared to others, which may be comparatively less robust. In
Figure 8, the attention module of the CSE channel is designed to acquire the significance of features from each channel. It dynamically modifies the representational capacity of each channel to concentrate more effectively on crucial feature channels that contribute to the task, eliminate redundant information, and enhance the overall performance of the model.
The CA module (
Figure 9) functions as an attention mechanism designed for image processing. Within the CA module, emphasis is placed on channel dimensions, assigning different weights to input channels to enable the model to focus on inter-channel relationships. The CA module comprises two main components: position coding and channel attention weight generation. In the position coding phase, the input feature map undergoes horizontal and vertical encoding through adaptive average pooling to capture positional information. Subsequently, the CA module merges the two pooled feature maps and conducts additional convolution, normalization, and activation operations to produce channel attention weights. Ultimately, the sigmoid activation function is employed on the attention convolution layer of the two channels to derive weight values in the horizontal and vertical orientations.
3.2. Feature Point Extraction of Weld Image Based on EfficientDet Network
Object detection plays a crucial role in the field of computer vision by identifying the position and category of objects within images or videos. Deep learning-based object detection algorithms can be categorized into one-stage and two-stage methods. One-stage methods, exemplified by YOLO, single-shot multiBox detector (SSD), and EfficientDet, are capable of simultaneously predicting the category and position of objects in real-time with high efficiency.
EfficientDet represents an efficient model for target detection. In
Figure 10, it primarily relies on neural network architecture to enhance the precision and efficiency of target detection. The model incorporates a novel feature pyramid network known as BiFPN, which integrates two-way feature propagation and multi-resolution feature fusion to effectively address targets of varying scales. Additionally, EfficientDet employs a methodology termed compound scaling, which enhances model performance by simultaneously adjusting the network’s width and depth. Furthermore, it leverages EfficientNet as the foundational network architecture to further enhance performance. Ultimately, EfficientDet has achieved a favorable equilibrium between performance and speed for target detection tasks.
- (1)
Feature extraction network
EfficientDet utilizes the EfficientNet model as a feature extraction network. EfficientNet is a convolutional neural network known for its efficiency and effectiveness. It aims to strike a balance between the depth, width, and resolution of the network by introducing a recombination coefficient to achieve high performance. Additionally, EfficientNet comprises a range of models with varying scale factors, denoted as EfficientNet-B0 to EfficientNet-B7. These scale factors govern the depth, width, and resolution of the models, enabling the selection of appropriate models based on computational resources and task requirements. For instance, EfficientNet-B0 is structured into 9 stages, consisting of a 1-stage Conv 3 × 3, a 2~8-stage repetitive stacked MBConv module, and a 9th stage comprising 1 × 1 convolution, an average pooling layer, and a fully connected layer. This design facilitates image classification and advanced feature extraction.
- (2)
Feature fusion network
BiFPN represents a feature fusion network designed for target detection applications (
Figure 11). The key characteristic of BiFPN lies in its ability to integrate features across various scales by utilizing a hierarchical feature pyramid and bidirectional path propagation. In target detection tasks, features from different scales contain different semantic information and receptive fields. Specifically, high-level features in feature maps of varying scales typically encapsulate more advanced semantic details, whereas low-level features focus on finer visual elements. The diversity in feature information across scales plays a crucial role in accurately localizing and recognizing targets. The BiFPN network encompasses five semantic information levels. To leverage these features effectively, BiFPN initially establishes a feature pyramid comprising multiple feature maps with diverse resolutions. Each feature map corresponds to different network levels, and feature fusion is achieved through bidirectional feature propagation, involving top-down and bottom-up pathways. The top-down path propagation involves expanding the feature map to the subsequent level from the highest-resolution feature map through an upsampling operation. Conversely, the bottom-up path propagation entails transmitting the lowest-resolution feature map to the higher level via a down-sampling operation, thereby enhancing the contextual understanding of features by conveying global semantic information. This bidirectional propagation mechanism significantly enhances the semantic richness and discriminative power of features, thereby boosting the performance of target detection tasks.
Through the BiFPN feature fusion network, the EfficientDet target detector enhances the fusion of features across various scales, thereby enhancing the precision and resilience of target detection. BiFPN integrates top-down and bottom-up bidirectional feature propagation along with a tailored pyramid weight distribution, facilitating the flow and integration of information between diverse levels and generating more semantically enriched feature representations.