1. Introduction
COVID-19 vaccination hesitancy is one of the greatest challenges that must be addressed to enhance community protection against the virus and its potential variants, especially in anticipation of a future pandemic. Coronavirus Disease 2019 (COVID-19) is among the top 10 causes of death, having caused 8.8 million deaths worldwide, according to public data reports [
1]. Vaccination remains the most effective strategy for preventing COVID-19 [
2,
3]. Despite the safety and effectiveness of COVID-19 vaccinations in reducing hospitalizations and mortality [
4], its uptake in the Deep South, United States (U.S.), which includes Alabama, Georgia, Louisiana, Mississippi, and South Carolina, remains consistently over 10% lower than the national average [
5], sparking concern in this geographic region. In 2022, the COVID-19 vaccination rate for individuals aged 12 years and older was 63% in the Deep South compared to 75% nationwide [
5]. Similarly, the COVID-19 booster uptake rate in the Deep South was 40%, compared to 51% nationwide [
5]. Based on population studies in the Deep South, disparities in COVID-19 vaccination and booster rates may be influenced by factors such as age [
5] and political party affiliation [
6,
7,
8,
9,
10,
11,
12]. The booster uptake rate was higher among individuals aged 65 and above compared to adults aged 18 to 64 and youth aged 12 to 17 [
5]. Low booster uptake is further exacerbated by the tendency of Republicans in the U.S. to be less likely to hold accurate beliefs about vaccines compared to Democrats [
6], especially in the Deep South states, which are predominantly Republican. Political ideology is a key factor in explaining why some people hesitate to receive a vaccine, according to research on COVID-19 vaccine hesitancy [
10,
11]. Additionally, individuals with limited knowledge of COVID-19 tend to have anti-vaccine policy preferences and overestimate their understanding of vaccines compared to experts [
13,
14]. Conversely, individuals with a good understanding of COVID-19 are more likely to have a positive attitude toward vaccination [
15,
16]. Therefore, the lower vaccine uptake rate in the Deep South may be attributed to party affiliation and limited knowledge of COVID-19, leading to vaccine hesitancy.
Several specialized scales have been developed to identify and quantify vaccine hesitancy as well as the explanatory factors behind vaccine hesitancy. These scales are crucial for uncovering the specific factors contributing to vaccine hesitancy in the Deep South. Vaccine hesitancy can be directly linked to concerns about the vaccine itself [
17] or trust in medical providers, trust in pharmacists [
18], and trust in public health authorities [
19]. The multidimensional COVID-19 Vaccine Hesitancy Scale (CoVaH) [
17] introduced a three-factor structured scale—Skepticism, Risk, and Fear—capturing meaningful constructs related to COVID-19 vaccination uptake. This scale demonstrated good overall specificity and sensitivity in differentiating unvaccinated individuals from vaccinated ones. The Trust in Doctors in General (T-DiG) Scale [
20] introduced seven subscales—Communication competency, Fidelity, Systems trust, Confidentiality, Fairness, Stigma-based discrimination, and Global trust—with sound psychometric properties. This scale is useful for researchers evaluating trust-related interventions or conducting studies where trust in medical doctors, such as physicians, is a significant construct or main outcome. The Trust in Community Pharmacists (TRUST-Ph) [
18] measure introduced three dimensions—Benevolence, Technical Competence, and Communication—to evaluate patient trust in community pharmacists, demonstrating relatively high validity and reliability. This scale can potentially be used to measure patient-reported perceptions of community pharmacists. The Trust in Public Health Authorities (TiPHA) scale [
19] introduced a two-factor—Beneficence and Competence—structural scale, which facilitated the development of targeted interventions to address low trust and improve compliance with public health authorities during routine and emergency public health activities. It is critical to comprehensively include multiple factors that may influence vaccination intention. These studies [
15,
21,
22,
23] evaluated the effect of perceived vaccination efficacy, effectiveness, trust in corporations, trust in health authorities, and trust in doctors on vaccination intention.
Data-driven analysis and subgroup identification are valuable for informing policies and messages to target different vulnerable groups within a population [
24]. Additionally, subgrouping is critical for identifying diverse barriers and informing targeted interventions to address the concerns of vulnerable groups, thereby increasing vaccination rates. The challenge arises from the fact that no single intervention is likely to address vaccine hesitancy comprehensively, and identifying the diverse concerns and barriers to vaccination uptake at a subpopulation level is essential, particularly in groups with lower vaccination rates [
25]. The unsupervised learning approach provides an unbiased method to address these challenges [
24,
26]. For instance, K-Means clustering has been employed to characterize participants based on demographics, knowledge, perceptions, risks, and other factors. This approach helps identify specific archetypes or subgroups within the cohort, determining if certain groups are more likely to take the COVID-19 vaccine. However, several limitations exist in clustering algorithms, including their limited predictive power for vaccination uptake or doses, the inclusion of incoherent participants in the clustering process, and the absence of an explicit cutoff for subgroup formation. Moreover, long-standing beliefs that predate the pandemic contribute to distrust in government [
27] and foster reluctance to receive vaccinations. These entrenched beliefs are difficult to change in the short term, making identifying individuals who are more open to vaccination based on their attitudes essential. Therefore, there is an urgent need to develop a new computational model that efficiently addresses existing limitations and targets populations likely to accept vaccines.
This study aims to prioritize the subgroups that have the potential to obtain a COVID-19 vaccine in the future. We performed a cross-sectional study to investigate the vaccine hesitancy of Alabaman adults and developed the Embedding-based Spatial Information Gain (EMSIG) method to create a latent space that captures similarities based on perceptions of COVID-19 and trust levels, allowing us to identify subgroups. The central idea is that individuals with low or no COVID-19 vaccine doses who share similar vaccine perceptions and trust levels with those with high COVID-19 vaccine doses in the same subgroup are more likely to be open to change and get vaccinated in the future. Alabama, as a representative politically conservative state in the Deep South, serves as a valuable case study for examining vaccine hesitancy. By analyzing Alabama’s participants’ concerns through the machine learning model, EMSIG can explore barriers and inform targeted intervention strategies to potentially increase the COVID-19 vaccination rate in the Deep South. EMSIG advances three key aspects to fulfill our three objectives: (1) uncovering factors that naturally emerge from the data in this study, (2) identifying subgroups through the screening of regions of interest (ROI), and (3) revealing subgroup-specific concerns and characterizing the demographic features to target the identified subgroups effectively. First, EMSIG enhances factor extraction using a data-driven, correlation-based approach to evaluate global and local cluster quality, and it employs advanced large language models (LLMs) for factor annotation. Second, EMSIG uses embedding-based techniques to generate latent projections of participant perceptions and introduces spatial information gain (SIG) signals to quantify the predictive power of each factor and aggregated factors. Third, EMSIG conducts a disparity analysis to enrich demographic characteristics and establish relationships between these characteristics and perception factors. EMSIG represents an innovative approach for exploring subgroups within COVID-19 survey data, with implications for developing tailored and informative interventions.
2. Materials and Methods
2.1. Study Population and Data Collection
This cross-sectional study was conducted between 1 February and 11 March 2024 using an online structured questionnaire administered by Qualtrics, a survey sampling company, to Alabama residents aged 18 years and older. The survey targeted a diverse demographic representative of the state, employing sampling quotas based on race, ethnicity, COVID-19 vaccination status, and residency. Qualtrics sent out 3951 invitations and had 3101 (78%) survey entrants. After excluding 2081 responses due to various reasons, including quality terminations, in-survey terminations, over-quota terminations, and data quality checks, 1020 valid and complete responses remained. The questionnaire captured demographics, health status, and attitudes towards public health authorities and integrated the four validated measures to assess hesitancy towards COVID-19 vaccinations (CoVaH) [
17] and trust across three dimensions: (1) medical doctors (T-DiG) [
20], (2) pharmacists (Trust-Ph) [
18], and (3) public health authorities (TiPHA) [
19]. All scales demonstrated acceptable internal reliability as measured by Cronbach’s alpha, with a range of α = 0.753–0.958 across all the original scales and associated subscales.
2.2. The Data-Driven Correlation-Based Factor Extraction and Factor Annotation Based on the Large Language Model
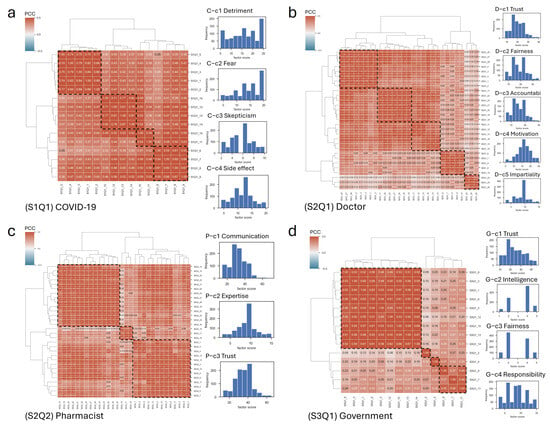
We performed a five-step procedure for data-driven factor extraction based on all 85 items across the four primary scales (CoVaH, T-DiG, Trust-Ph, and TiPHA). Responses on the CoVah, T-DiG, and Trust-Ph ranged from 1 “Strongly disagree” to 5 ”Strongly agree”, with responses on the TiPHA ranged from 1 “Strongly agree” to 4 “Strongly disagree”.
First, we reversely scored items that were phrased in the opposite direction to the other items within each section. Second, we generated the questionnaire’s pairwise Pearson Correlation Coefficient (
) matrix using the formula
. We then performed agglomerative clustering to iteratively merge the most similar pairs of items until all items formed a single cluster in a tree structure, using Ward’s method to minimize the variance within clusters. Third, to determine the optimal number of clusters, we iteratively tested cluster sizes (
) ranging from 2 to 8 in the hierarchical cluster analysis with Ward’s linkage method and assessed the cluster quality based on both the Silhouette Coefficient (
) [
28] and the
within each cluster. The
measures the relative cohesion of clusters based on intra-cluster and inter-cluster distances. For example, in a cluster
with the center
, each item
’s in-cluster distance and the smallest mean distance to all points in any other cluster were calculated by
, and
, respectively. Then, the
of the item
i could be calculated by
could be calculated by
. The
varied from −1 to 1, with higher values indicating better quality clusters. The in-cluster
mean-variance analysis, on the other hand, ensures the local cluster quality by measuring cluster cohesion and dispersion. To optimize the number of clusters within an acceptable range of the
, we set the
threshold above 0.25, which is the cutoff for “weak”. Meanwhile, we set a minimum threshold for the in-cluster
to ensure cluster quality. Thus, we derived the correlation-based factors from each scale by finalizing the cluster size. Fourth, we used LLMs to annotate the factors based on the survey questions. Particularly, we adopted ChatGTP-4 (
https://chat.openai.com/, accessed on 11 July 2024), Gemini (
https://gemini.google.com/, accessed on 11 July 2024), and meta-AI (
https://www.meta.ai/, accessed on 11 July 2024) for the perception inference. The questions in each cluster were concatenated as input, and we generated prompt messages using the following template with the prompt strategy: “Identify one succinct aspect from the perceptions regarding vaccination in the related questions. \n [the survey questions]”. The LLMs returned key sentences in bold font. We manually reviewed the keywords generated by the three LLMs, selected the most representative word for factor annotation, and performed queries with the prompt five times for the repeated prompt strategy, selecting the most frequent response among the queries as the final result. Fifth, we calculated the factor scores by aggregating the item scores within each factor’s cluster.
2.3. The Participant’s Latent Projection Based on the 85-Item Questionnaire with a Five-Point Likert Scale
To explore the heterogeneity of factor scores using latent models, we utilized these factors and their scores as embeddings to project the participants into latent spaces using Uniform Manifold Approximation and Projection (UMAP) [
29]. Latent non-linear projections often unravel complex combinations of scores in ways that are interpretable by humans. For example, a distance-based projection can capture the similarity between participants based on multi-factor scores. Specifically, we used all the factors extracted from the 85 questions to determine each participant’s latent projection. To visualize the heterogeneity in factor scales, we created a scatter plot of latent projections, applying a color scale to represent different factors and COVID-19 vaccine doses.
2.4. The Regions of Interest (ROI) Discovery to Form the Participant’s Subgroup in Latent Projection
To explore participant subgroups, we employed UMAP to generate a survey-based latent space and applied information gain to identify factors predicting COVID-19 vaccine doses. Particularly, we developed embedding-based spatial information gain (EMSIG) to explore the ROI where these subgroups were located. We were inspired by the spatial decision tree for geographical classification [
30] to develop the spatial information gain (SIG) method to quantify the importance of a specific feature or features in refining the separation of COVID-19 vaccine doses in the latent space. Since the embedding space reflects survey similarity, an SIG for a particular factor suggests that it can effectively predict the COVID-19 vaccine doses within that ROI. Consequently, that factor can be used to inform and encourage participants in the identified subgroups to get the COVID-19 vaccination.
Firstly, we took the latent-projected coordinates in 2D space, denoted as and , where is the index of the participants. We pulled out the minimum and maximum values from and , respectively, and created a grid matrix with a 0.5 step in the latent embeddings. Secondly, we performed subgroup screening based on the latent embedding. We took every grid position and calculated the grid-level’s SIG using the Kullback Leibler divergence formula , where is a random variable, and are the same random variable before and after obtained for , is the prior distribution for , and is the posterior distribution for given . The expected value of the information gain is the mutual information I(X;A) of and . After calculating the SIG for all the pixels, we created an interpolated SIG signal surface based on the formula , where is the smoothed signal height at the pixel p, is a scale factor controlling the degree of signal dispersion (default is 1), and is the Euclidian distance from the position v to the current pixel p. Since the SIG signal cannot be negative, the record set in the ROI can be retrieved by raising the positive cutoff c in the interpolated SIG signal surface in the formula . Thirdly, we set the cutoff c to be 34% of the maximum value of the SIG signals to filter the subgroups with clear boundaries. The contour lines were added based on the four levels of the SIG signals: 0%, 17%, 34%, and 51%.
2.5. The Correlation Analysis Between the Factor and COVID-19 Doses in Each ROI Subgroup
To reveal the correlation between each factor and COVID-19 doses in the ROI subgroups, we performed Pearson Correlation analysis and calculated the . We set the absolute cutoff at 0.2 to identify at least weak correlations between COVID-19 vaccine doses and the factor.
2.6. The Statistical Analysis of the Patient’s Characteristics in ROI Subgroups
To investigate disparities among patients with distinct characteristics across different ROI subgroups, we conducted a chi-squared contingency test using the SciPy library in Python. Specifically, we used the frequency of each category in a selected variable among all participants as the null hypothesis (). We then considered the observed frequency of each category in the selected variable within the ROI subgroup as the observation (, where i is the index of categories). The expected frequency of each category was based on the whole population (). The chi-square statistic was calculated using the formula , where is the total number of categories, and the degree of freedom is . We applied a p-value cutoff of 0.05 to filter statistically significant results. When a category had too few observations, we pooled the categories with a sample size larger than 5. Subsequently, we extracted these significant characteristics and visualized them using pie charts to compare the proportions of these characteristics across the ROI subgroups.
2.7. The Regression-Based Machine Learning Model for COVID-19 Vaccine Dose Prediction
We performed and compared supervised ML models in the six major categories, including (1) Linear/generalized linear methods (Linear Regression [
31], Least Angle Regression [
32], Huber Regressor, Elastic Net [
33], Orthogonal Matching Pursuit [
34], and Passive Aggressive Regressor [
35]); (2) Tree-based methods (Decision Tree Regressor [
36]); (3) Instance-based methods (K Neighbors Regressor [
37]); (4) Bayesian methods (Bayesian Ridge [
38]); (5) Gradient boosting methods (Gradient Boosting Regressor [
39], Light Gradient Boosting Machine [
40], and Extreme Gradient Boosting [
41]); and (6) Ensemble methods (Random Forest Regressor [
42], Extra Trees Regressor [
43], and AdaBoost Regressor [
44]). To evaluate the performance of the candidate models, we applied the coefficient of determination (R
2), indicating the goodness of fit [
45]. We also measured five additional metrics, including Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Root Mean Squared Logarithmic Error (RMSLE), and Mean Absolute Percentage Error (MAPE). The 1020 participants were divided into 70% for training and 30% for testing. The 70% training set was further subdivided, with 63% for training and 7% for validation within a 10-fold cross-validation framework. The model’s performance was evaluated based on the testing set. In addition, we utilized two measurements, feature importance [
46] and Shapley values [
47], to extract the predominant predictors. Feature importance measures each feature’s relative contribution in reducing the training dataset’s variance. Shapley values measure the contribution of individual predictors in a regression model based on cooperative game theory.
4. Discussion
We conducted a data-driven, correlation-based analysis of COVID-19 vaccination attitudes using an 85-item questionnaire completed by 1020 participants in Alabama and identified 16 key factors which differed from what has been previously reported. Using our data, we identified: “detriment”, “fear”, “skepticism”, and “side effects”. These factors differ slightly from the three identified in the published CoVaH [
17] study (“skepticism”, “risk”, and “fear”). For five questions—regarding the perceived goodness, importance, community benefit, effectiveness, and provider recommendation of the COVID-19 vaccine—we summarized the positive responses as “benefit” and used reverse coding to classify negative responses as “detriment” rather than “skepticism” as identified by CoVaH. The CoVaH’s “risk” was divided into two factors: “skepticism” and “side effects”. The ‘skepticism’ factor consisted of two questions: one regarding the perception that the government created COVID-19 and the other expressing caution about government recommendations. Next, the published T-DiG reported seven factors [
20], including “communication competency”, “fidelity”, “system trust”, “confidentiality”, “fairness”, “stigma-based discrimination”, and “global trust”. For our study, five factors were extracted. That is, “trust” was a result of the merging of “global trust” and “communication competency”. The factor “accountability” was formed by combining “system trust” and “confidentiality”. We derived the factor “motivation” by reverse coding “fidelity”, and “impartiality” was formed by reverse coding “stigma-based discrimination”. Compared to the three factors previously reported for the TRUST-Ph [
18] scale which consists of: “benevolence”, “technical competence”, and “communication”, we extracted four factors. The “expertise” factor consists of three questions: “Pharmacists should be the persons who make decisions about your medications”, “Pharmacists can help you with your illness”, and “Pharmacists can solve your medication problems”. These were identified as a subset of the original factor of “technical competence”. The remaining questions from “technical competence” were combined with “benevolence” to form the factor “communication”. Lastly, the TiPHA [
19] reported two factors while our study extracted four factors. Specifically, the factor “beneficence” was replaced by the data-driven correlation-based factors “trust”, “intelligence”, and “fairness”. The questions regarding “unhelpful recommendations” and “wasting money” formed the factor “responsibility”. For the factor annotations, LLMs offered significant advantages for inferring the key concept as a factor annotation due to their contextual understanding [
48]. The representative words extracted from the integrated prompts results of the three state-of-the-art LLMs addressed the subjectivity inherent in the factor labels.
To identify subgroups of Alabama residents with similar perceptions, enriched by demographic characteristics but with varying COVID-19 vaccine doses, we developed the EMSIG to explore the ROI subgroups. The ROI subgroups were critical for identifying participants who have the potential to obtain additional COVID-19 vaccine doses, given that their survey answers were similar to those of high-dose individuals but with minor concerns that could be shown by EMSIG. The four ROI subgroups exhibited distinct demographic characteristics. The ROI-1 subgroup, characterized by relatively good health status, showed similarities to the ROI-3 subgroup characterized by educated Democrats, which had a high flu-shot rate. In comparison, the ROI-2 subgroup was characterized by being white, older, and Republican. Lastly, the ROI-4 subgroup was characterized by minority status and a relatively lower flu shot rate. This finding supports the idea that political preference differences influence vaccination attitudes via political networks [
6,
7,
8,
9,
10,
11,
12].
This study addressed the barriers to the uptake of the COVID-19 vaccination in various groups and identified factors critical to the success of multi-faceted interventions targeted to overcome vaccine hesitancy [
25]. To encourage participants, particularly those with low COVID-19 vaccine doses in the ROI subgroups with high COVID-19 variance, several common concerns need to be addressed, including the perceived detriments, fears, and side effects of COVID-19. Notably, the vaccination efficacy and effectiveness factors included in the COVID-19 perceived detriment factor have been reported in other studies [
15,
21,
22]. Meanwhile, the trust factors, including trust in corporations, trust in health authorities, and healthcare provider advice reported previously [
15,
21,
22,
23] have been found in each ROI-specific subgroup as specific concerns. The ROI-1 and ROI-3 subgroups tend to put “pharmacists communication” and “government responsibility” as the top priority, specifically. In contrast, the ROI-2 subgroup showed more concerns with the “doctor trust” and “government intelligence” specifically. Therefore, to persuade the ROI-1 and ROI-3 subgroups to get the COVID-19 vaccination, it is crucial to highlight the helpful recommendations of public health agencies as well as how they address drug problems and promote efficient spending practices. Additionally, endorsements and recommendations from pharmacists should be emphasized. To persuade the ROI-2 subgroup to get the COVID-19 vaccination, it is crucial to solve their concerns about doctor trust and the intelligence of public health authorities, especially regarding the repeated strategies to help the public despite acknowledging their limited effectiveness. The concerns regarding pharmacist communication expressed by the ROI-1 and ROI-3 subgroups highlight the critical role of pharmacists as advocates for COVID-19 vaccination, as well as educators and vaccine administrators. By adhering to the regulations of their respective jurisdictions, pharmacists can significantly contribute to vaccination efforts [
49]. Restoring trust in doctors for the ROI-2 subgroup, characterized by being white, older, and Republican participants, is crucial for improving vaccination compliance and other health behaviors, especially given the survey’s findings of a significant decline of trust in physicians and hospitals during the COVID-19 pandemic [
50]. Health and political leaders should work to enhance public trust in the government [
51], particularly addressing the concerns of the ROI-2 subgroup regarding intelligence, as well as the responsibilities highlighted by the ROI-1 and ROI-3 subgroups, to potentially increase vaccination rates. Providers can offer trusted and reliable resources to families, including local and national public health and government websites as well as fair and unbiased social media sites that provide transparent, accurate, and updated information [
52] to address the fundamental concerns regarding perceived detriment, fear, skepticism, and side effects. For instance, the Centers for Disease Control and Prevention (CDC) provides timely updates for research on adverse events following COVID-19 vaccination [
53]. Additionally, it is not surprising that the ROI-1 and ROI-3 subgroups exhibited both higher COVID-19 vaccine doses and flu-shot rates compared to the ROI-2 and ROI-4 subgroups, as another study has also demonstrated a strong association between flu-shot updates and COVID-19 vaccine uptake [
54].
The current research has several limitations that need to be addressed in future studies. First, we did not consider the brands of the COVID-19 vaccination (e.g., Moderna, Pfizer, Johnson & Johnson) and their impact on vaccine hesitancy. Different vaccines are perceived differently by the public and vary in terms of side effects and efficacy, all of which could affect participants’ responses and their willingness to get vaccinated. Second, for the number of COVID-19 vaccine doses, since we did not request the dates of each COVID-19 vaccination, we could not identify when each vaccine dose was received. Additionally, we did not account for individuals who did not receive the vaccination due to prior COVID-19 infection. Addressing these gaps could enhance our model for targeting individuals susceptible to COVID-19, considering that the effectiveness of COVID-19 vaccines tends to decline after six months [
55,
56]. Third, to validate our discovery of the factors and their influence on COVID-19 vaccine doses, our future work will focus on developing multi-faceted interventions to increase COVID-19 vaccine uptake. Fourth, this study is limited to the state of Alabama. Expanding the research to cover the Deep South or conducting a national study could reveal subgroup perceptions and heterogeneity of demographic characteristics. At the national level, political influence on COVID-19 vaccine dose variance can be more effectively analyzed by comparing party affiliations across different states. Since the Deep South lags in coronavirus vaccination rates and experiences significant racial and ethnic residential segregation [
5], examining ecological and spatiotemporal differences (e.g., urban vs. rural) could provide valuable insights for tailored interventions, especially in comparison to other regions. Fifth, since this was a cross-sectional study, causality cannot be established. Sixth, while our model identified subgroup-specific factors, it may not capture all nuances across diverse populations. For instance, the levels of health literacy [
57,
58,
59] can vary significantly. The model did not efficiently evaluate the main concerns specified through open-ended questions expressed by the participants. Additionally, the current design has not incorporated a longitudinal study, and the modeling techniques could help validate the findings and explore changes in attitudes over time. Seventh, the EMSIG model could be enhanced by integrating multidimensional data to create comprehensive latent embeddings. This approach would allow for a more holistic representation of factors, capturing demographics, vaccine hesitancy, trust scales, and geographic information, ultimately improving the model’s accuracy and ability to identify subgroup-specific concerns. Lastly, the survey participants were subject to selection bias and recall bias, which may have influenced the EMSIG results with distorted data. The EMSIG method could be applied to other vaccines, such as the flu shot, to explore subgroup concerns and develop targeted interventions.